发表在 ACL 2020
属于文本迁移中的半监督方法
动机
现有的平行语料很少,而神经网络含有大量参数需要训练学习,这时需要更多的平行语料提供更多有用的信息,因此,作者针对 formal 风格迁移任务提出了三种数据增强方法,来获得更多有用的句子对
方法
-
Back Translation
机器翻译中很常见的一种方数据增强方法,将目标语言使用训练好的翻译模型翻译成原语言,构成伪句子对
先用已有的平行语料(informal--formal)训练一个 seq2seq 模型,然后将目标语句中 formal 的语句喂给这个 seq2seq 模型,生成 informal 句子,形成伪句子对 informal—formal,来扩充平行语料
-
Formality discrimination

先将 informal 英语句子翻译成另一种语言(如法语),然后将翻译回英语
使用带 formal 标签的语料训练一个 CNN 来给句子打分,如果大于阈值,则被选为 伪平行语料
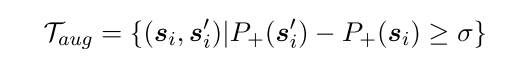
-
multi-task transfer
使用其它任务中带注释的句子对,观察到 inform l的句子通常语法是错误的,而 formal 的句子语法是对的,因此可以将 GEC(Grammatical error correction) 模型所用到的训练数据集直接扩充到现有的平行语料
模型
使用 transformer(base)作为 seq2seq 模型
训练方法:使用增强的数据进行预训练,再用现有的平行语料进行微调
实验
文章在实验方面做的还是比较充分的,对影响结果的因素都做了定性分析,但感觉缺少对选择 transformer 模型的对比分析