什么是线程池?为什么要用线程池?
1、降低资源的消耗。降低线程创建和销毁的资源消耗;
2、提高响应速度:线程的创建时间为T1,执行时间T2,销毁时间T3,免去T1和T3的时间
3、提高线程的可管理性。
实现一个我们自己的线程池
1、 线程必须在池子已经创建好了,并且可以保持住,要有容器保存多个线程;
2、线程还要能够接受外部的任务,运行这个任务。容器保持这个来不及运行的任务.
package com.xiangxue.ch6.mypool; import java.util.LinkedList; import java.util.List; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue; /** *类说明:自己线程池的实现 */ public class MyThreadPool2 { // 线程池中默认线程的个数为5 private static int WORK_NUM = 5; // 队列默认任务个数为100 private static int TASK_COUNT = 100; // 工作线程组 private WorkThread[] workThreads; // 任务队列,作为一个缓冲 private final BlockingQueue<Runnable> taskQueue; private final int worker_num;//用户在构造这个池,希望的启动的线程数 // 创建具有默认线程个数的线程池 public MyThreadPool2() { this(WORK_NUM,TASK_COUNT); } // 创建线程池,worker_num为线程池中工作线程的个数 public MyThreadPool2(int worker_num,int taskCount) { if (worker_num<=0) worker_num = WORK_NUM; if(taskCount<=0) taskCount = TASK_COUNT; this.worker_num = worker_num; taskQueue = new ArrayBlockingQueue<>(taskCount); workThreads = new WorkThread[worker_num]; for(int i=0;i<worker_num;i++) { workThreads[i] = new WorkThread(); workThreads[i].start(); } Runtime.getRuntime().availableProcessors(); } // 执行任务,其实只是把任务加入任务队列,什么时候执行有线程池管理器决定 public void execute(Runnable task) { try { taskQueue.put(task); } catch (InterruptedException e) { e.printStackTrace(); } } // 销毁线程池,该方法保证在所有任务都完成的情况下才销毁所有线程,否则等待任务完成才销毁 public void destroy() { // 工作线程停止工作,且置为null System.out.println("ready close pool....."); for(int i=0;i<worker_num;i++) { workThreads[i].stopWorker(); workThreads[i] = null;//help gc } taskQueue.clear();// 清空任务队列 } // 覆盖toString方法,返回线程池信息:工作线程个数和已完成任务个数 @Override public String toString() { return "WorkThread number:" + worker_num + " wait task number:" + taskQueue.size(); } /** * 内部类,工作线程 */ private class WorkThread extends Thread{ @Override public void run(){ Runnable r = null; try { while (!isInterrupted()) { r = taskQueue.take(); if(r!=null) { System.out.println(getId()+" ready exec :"+r); r.run(); } r = null;//help gc; } } catch (Exception e) { // TODO: handle exception } } public void stopWorker() { interrupt(); } } }
测试类:
package com.xiangxue.ch6.mypool; import java.util.Random; /** *类说明: */ public class TestMyThreadPool { public static void main(String[] args) throws InterruptedException { // 创建3个线程的线程池 MyThreadPool2 t = new MyThreadPool2(3,0); t.execute(new MyTask("testA")); t.execute(new MyTask("testB")); t.execute(new MyTask("testC")); t.execute(new MyTask("testD")); t.execute(new MyTask("testE")); System.out.println(t); Thread.sleep(10000); t.destroy();// 所有线程都执行完成才destory System.out.println(t); } // 任务类 static class MyTask implements Runnable { private String name; private Random r = new Random(); public MyTask(String name) { this.name = name; } public String getName() { return name; } @Override public void run() {// 执行任务 try { Thread.sleep(r.nextInt(1000)+2000); } catch (InterruptedException e) { System.out.println(Thread.currentThread().getId()+" sleep InterruptedException:" +Thread.currentThread().isInterrupted()); } System.out.println("任务 " + name + " 完成"); } } }
JDK中的线程池和工作机制
线程池的创建
ThreadPoolExecutor,jdk所有线程池实现的父类
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
int corePoolSize:线程池中核心线程数,< corePoolSize ,就会创建新线程,= corePoolSize ,这个任务就会保存到BlockingQueue,如果调用prestartAllCoreThreads()方法就会一次性的启动corePoolSize个数的线程。
int maximumPoolSize:允许的最大线程数,BlockingQueue也满了,< maximumPoolSize时候就会再次创建新的线程
long keepAliveTime:线程空闲下来后,存活的时间,这个参数只在> corePoolSize才有用
TimeUnit unit:存活时间的单位值
BlockingQueue<Runnable> workQueue:保存任务的阻塞队列
ThreadFactory threadFactory:创建线程的工厂,给新建的线程赋予名字
RejectedExecutionHandler handler:饱和策略
AbortPolicy:直接抛出异常,默认;
CallerRunsPolicy:用调用者所在的线程来执行任务
DiscardOldestPolicy:丢弃阻塞队列里最老的任务,队列里最靠前的任务
DiscardPolicy :当前任务直接丢弃
实现自己的饱和策略,实现RejectedExecutionHandler接口即可
提交任务
1、execute(Runnable command) 不需要返回
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command); }
2、Future<T> submit(Callable<T> task) 需要返回
public Future<?> submit(Runnable task) { //提交的task为null,抛出空指针异常 if (task == null) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null); //执行任务 execute(ftask); return ftask; }
关闭线程池
shutdownNow():设置线程池的状态,还会尝试停止正在运行或者暂停任务的线程
shutdown():设置线程池的状态,只会中断所有没有执行任务的线程
工作机制

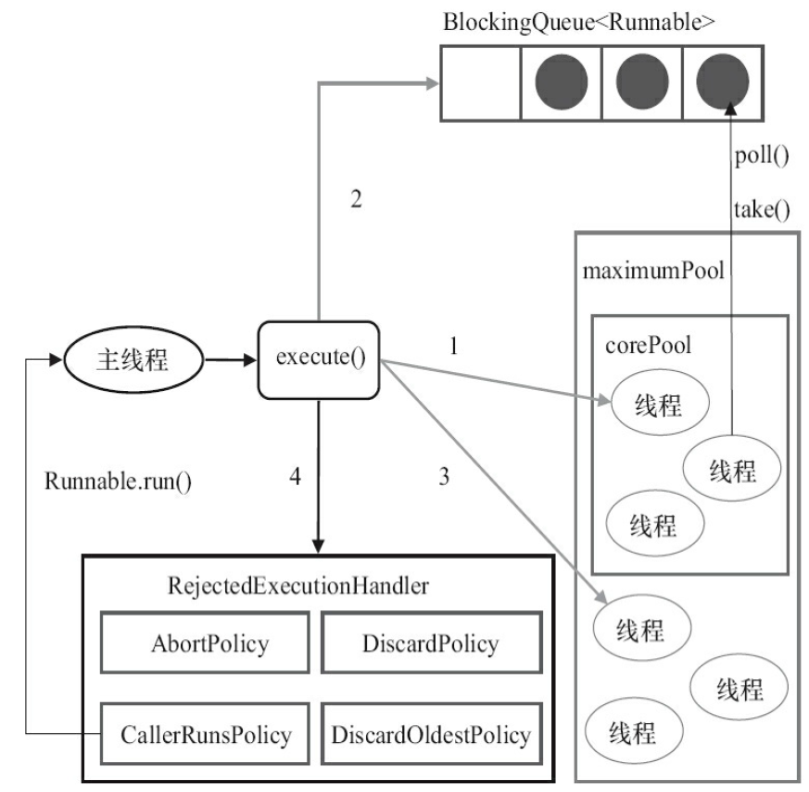
- 通过
workerCountOf计算出当前线程池的线程数,如果线程数小于corePoolSize,执行addWork方法创建新的线程执行任务; - 如果当前线程池线程数大于
coreSize,向队列里添加task,不继续增加线程; - 当
workQueue.offer失败时,也就是说现在队列已满,不能再向队列里放,此时工作线程大于等于corePoolSize,创建新的线程执行该task; - 执行
addWork失败,执行reject方法处理该任务。
总结一下,对于使用线程池的外部来说,线程池的机制是这样的:
- 如果正在运行的线程数 <
coreSize,马上创建线程执行该task,不排队等待; - 如果正在运行的线程数 >=
coreSize,把该task放入队列; - 如果队列已满 && 正在运行的线程数 <
maximumPoolSize,创建新的线程执行该task; - 如果队列已满 && 正在运行的线程数 >=
maximumPoolSize,线程池调用handler的reject方法拒绝本次提交。
合理配置线程池
根据任务的性质来:计算密集型(CPU),IO密集型,混合型
计算密集型:加密,大数分解,正则……., 线程数适当小一点,最大推荐:机器的Cpu核心数+1,为什么+1,防止页缺失,(机器的Cpu核心=Runtime.getRuntime().availableProcessors();)
IO密集型:读取文件,数据库连接,网络通讯, 线程数适当大一点,机器的Cpu核心数*2,
混合型:尽量拆分,IO密集型>>计算密集型,拆分意义不大,IO密集型~计算密集型
队列的选择上,应该使用有界,无界队列可能会导致内存溢出,OOM
预定义的线程池
FixedThreadPool
创建固定线程数量的,适用于负载较重的服务器,使用了无界队列(LinkedBlockingQueue)
SingleThreadExecutor
创建单个线程,需要顺序保证执行任务,不会有多个线程活动,使用了无界队列(LinkedBlockingQueue)
CachedThreadPool
会根据需要来创建新线程的,执行很多短期异步任务的程序,使用了SynchronousQueue
WorkStealingPool(JDK7以后)
基于ForkJoinPool实现
ScheduledThreadPoolExecutor
需要定期执行周期任务,Timer不建议使用了,Timer中出现异常整个挂掉。
newSingleThreadScheduledExecutor:只包含一个线程,只需要单个线程执行周期任务,保证顺序的执行各个任务
newScheduledThreadPool 可以包含多个线程的,线程执行周期任务,适度控制后台线程数量的时候
方法说明:
schedule:只执行一次,任务还可以延时执行
scheduleAtFixedRate:提交固定时间间隔的任务
scheduleWithFixedDelay:提交固定延时间隔执行的任务
//达到给定的延时时间后,执行任务。这里传入的是实现Runnable接口的任务, //因此通过ScheduledFuture.get()获取结果为null public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); //达到给定的延时时间后,执行任务。这里传入的是实现Callable接口的任务, //因此,返回的是任务的最终计算结果 public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit); //是以上一个任务开始的时间计时,period时间过去后, //检测上一个任务是否执行完毕,如果上一个任务执行完毕, //则当前任务立即执行,如果上一个任务没有执行完毕,则需要等上一个任务执行完毕后立即执行 public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit); //当达到延时时间initialDelay后,任务开始执行。上一个任务执行结束后到下一次 //任务执行,中间延时时间间隔为delay。以这种方式,周期性执行任务。 public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
两者的区别:
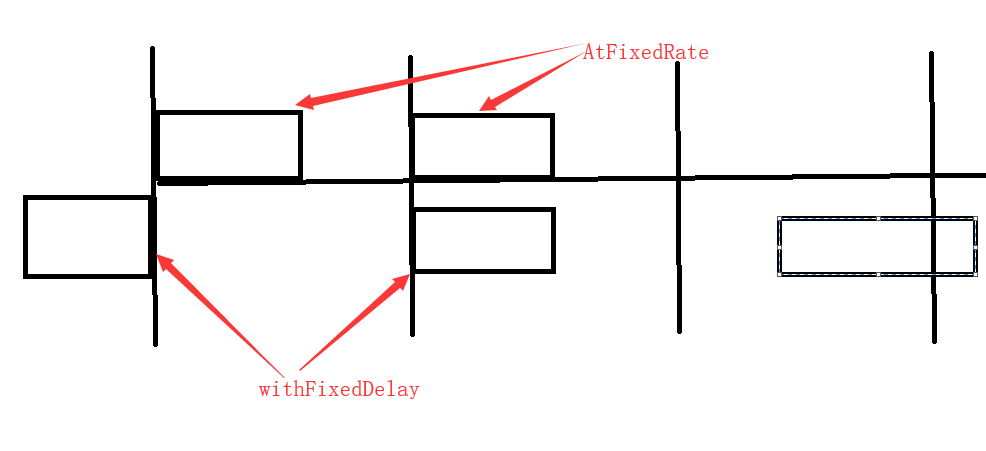
scheduleAtFixedRate任务超时:
规定60s执行一次,有任务执行了80S,下个任务马上开始执行
第一个任务 时长 80s,第二个任务20s,第三个任务 50s
第一个任务第0秒开始,第80S结束;
第二个任务第80s开始,在第100秒结束;
第三个任务第120s秒开始,170秒结束
第四个任务从180s开始
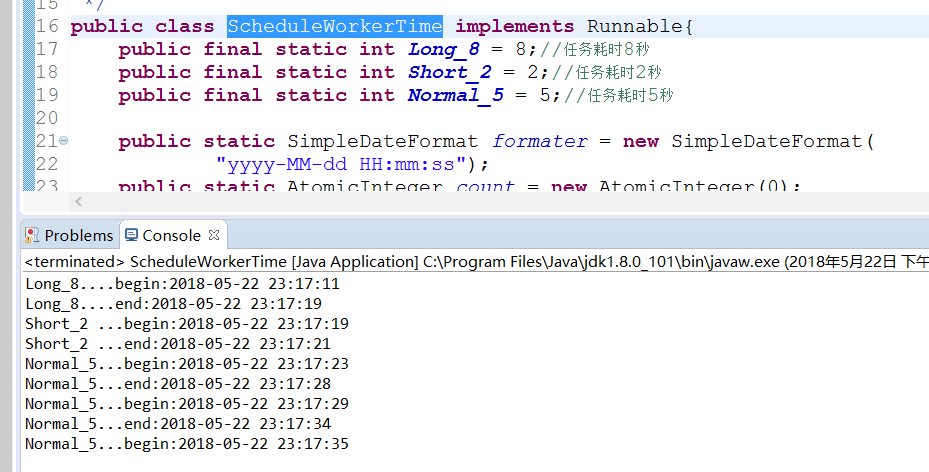
参加代码:ScheduleWorkerTime类,执行效果如图:
建议在提交给ScheduledThreadPoolExecutor的任务要catch异常,否则会导致整个周期任务挂掉,下个周期不会执行。
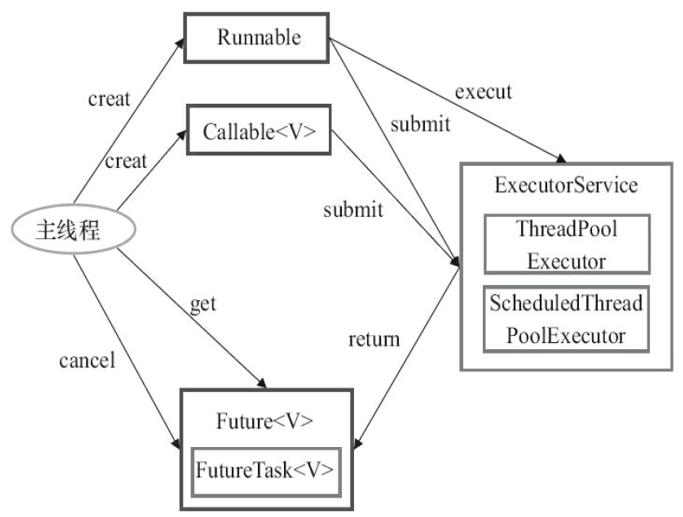
Executor框架
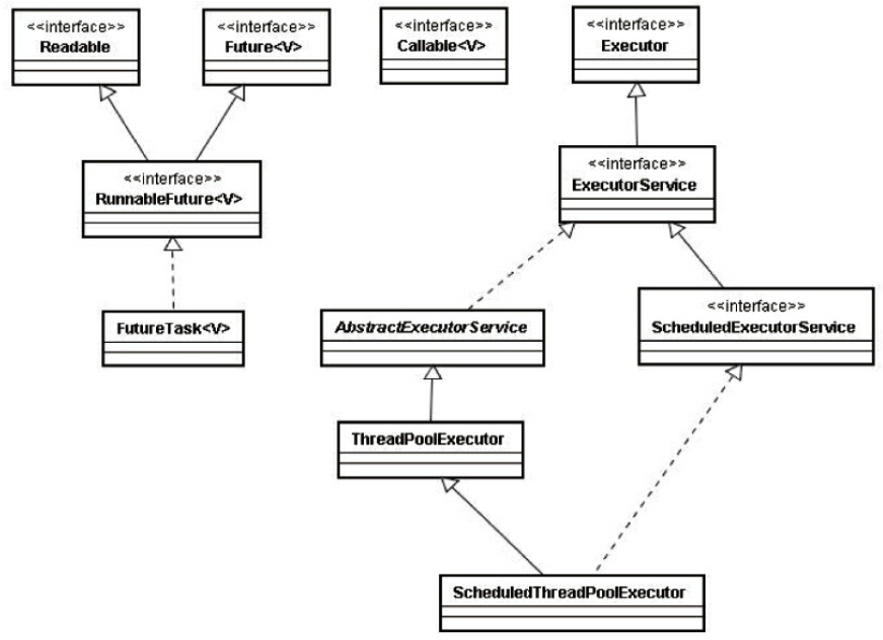
Executor框架基本使用流程