在说分布式事务之前,先回顾下事务的相关知识点。
事务
概念
事务指的是一系列数据库操作,它是保证数据库正确性的基本逻辑单元,拥有ACID四个特性:原子性、一致性、隔离性与持久性。
举个例子,下面这两种组成情况都叫做事务:
1.由单个操作序列(一条SQL语句)组成的事务
select * from test;
2.由多个操作序列(SQL语句)组成的事务
select * from test where id = 1; update test(id, name) set name = 'john' where id = 1;
当然,如果我们没有显示声明事务的话,数据库则会给我们自动地划分事务,对于MySQL来说,没有显示声明事务,则一条SQL语句就是一个事务,执行完便会自动提交。
一个事务由开始标识(begin_transaction)、数据库操作和结束标识(commit或rollback)三部分组成。如下图所示:
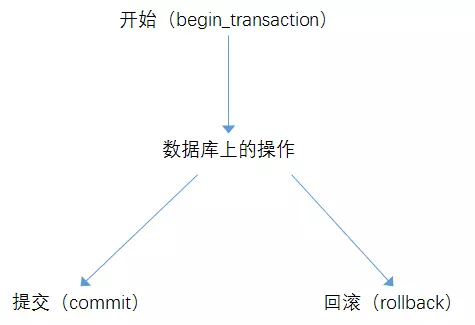
关于上图的相关说明如下:
-
事务开始:begin_transaction,说明事务的开始;
-
数据库上的操作:表现为一条或多条SQL语句;
-
事务提交:commit_transaction,提交事务操作,操作生效;
-
事务回滚:rollback_transaction,事务取消,操作废弃。
特性
事务是对数据库的一系列操作,是保证数据库正确性的基本逻辑单元,这句话就决定了事务必须具备ACID四个特性,才能保证数据库的正确性。下面我们简要说明下ACID四个特性的基本概念:
1.原子性
事务的原子性主要体现在事务中包含的操作要么全部完成,要么全部放弃,不存在中间状态,即一部分操作成功,一部分操作失败的状态。
2.一致性
事务的一致性是指事务的执行结果必须使数据库从一种一致性状态变化到另一种一致性状态,而不会停留在某种中间状态上。也就是说无论事务执行前还是执行后,数据库状态均为一致性状态,处于这种状态的数据库才被认为是正确的。由此可见,事务的一致性与原子性是密切相关的。

3.隔离性
当多个事务的操作交叉执行时,若不加控制,一个事务的操作及其所使用的数据可能会对其他事务造成影响。事务的隔离性是指:一个事务的执行既不能被其他事务所干扰,同时也不能干扰其他事务。具体来讲,一个没有结束的事务在提交之前不允许将其结果暴露给其他事务,这是因为未提交的事务有可能在以后的执行中回滚,因此,当前结果不一定是最终结果,而是一个无效的数据,不允许其他事务使用这种无效数据。
4.持久性
事务的持久性体现在当一个事物提交后,系统保证该事务的结果不会因以后的故障而丢失,也就是说,事务一旦提交,它对数据库的更改将是永久性的。
上述即为事务的四个特性,ACID这四条特性起到了保证事务操作的正确性、维护数据库的一致性及完整性的作用。
分布式事务
概念
分布式事务与单机事务一样都是由一组操作序列组成,不同的是单机事务只是在单机上执行,而分布式事务则是在多台机器上执行。

应用场景
比如对于一个电商公司,由于当前微服务系统的火热,因此用户、订单、支付、商品等都会拆分成不同系统,并且每个系统都会有各自的数据库,比如小明买了一双篮球鞋,订单系统需要新增一条记录,个人账户需要支出篮球鞋的费用,商家的账户需要增加来自小明的费用,并且商品库存需要-1,对于这些操作来说,要么同时成功,要么一起失败。
常见的分布式事务解决方案
基于XA协议的两阶段提交
1、思想
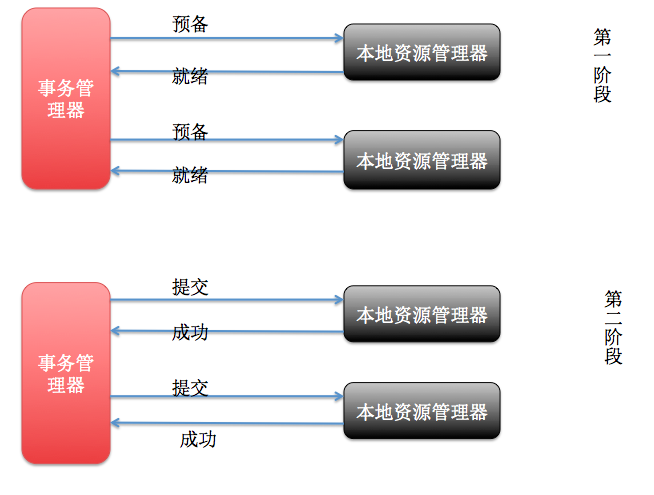
两阶段提交协议是为了实现分布式事务提交而采用的协议。其基本思想是把全局事务的提交分为如下两个阶段:
a.决定阶段:由协调者向各个参与者发出“预提交”(Prepare)命令,然后等待应答,若所有的参与者返回“准备提交”(Ready)应答,则该事务满足提交条件。如果至少有一个子事务返回“准备废弃”(Abort)应答,则该事务不能提交;
b.执行阶段:在事务具备提交条件的情况下,协调者向各个参与者发出“提交”(Commit)命令,各个参与者执行提交;否则,协调者向各个参与者发出“废弃”(Abort)命令,各个参与者执行回滚,放弃对数据库的修改。无论是“提交”还是“废弃”,各参与者执行完毕后都需要向协调者返回“确认”(ACK)应答,通知协调者事务执行结束。
两阶段提交协议的基本思想可以用下图表示:
总的来说,XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
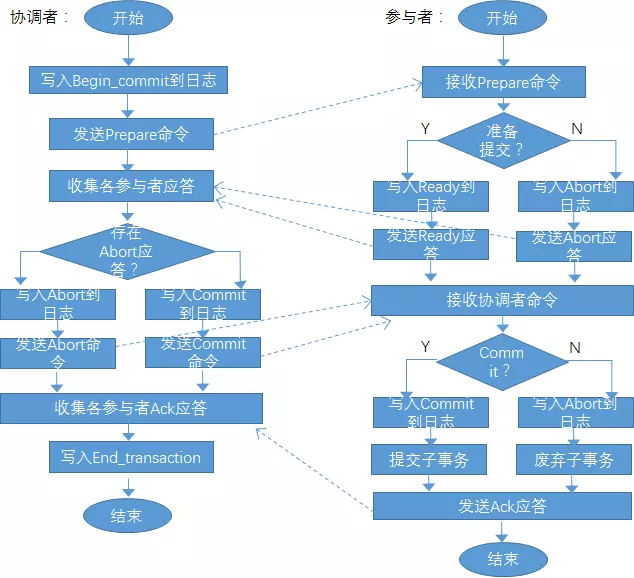
2、基本流程
说明:
a.协调者在征求各参与者的意见之前,首先要在它的日志文件中写入一条“开始提交”(Begin_commit)的记录。然后,协调者向所有参与者发送“预提交”(Prepare)命令,此时协调者进入等待状态,等待收集各参与者的应答;
b.各个参与者接收到“预提交”(Prepare)命令后,根据情况判断其是否已经准备好提交子事务。若可以提交,则在参与者日志文件中写入一条“准备提交”(Ready)的记录,并将“准备提交”(Ready)的应答发送给协调者,否则,在参与者的日志文件中写入一条“准备废弃”(Abort)的记录,并将“准备废弃”(Abort)的应答发送给协调者。发送应答后,参与者将进入等待状态,等待协调者所做出的最终决定;
c.协调者收集各参与者发来的应答,判断是否存在某个参与者发来“准备废弃”的应答,若存在,则采取两阶段提交协议的“一票否决制”,在其日志文件中写入一条“决定废弃”(Abort)的记录,并发送“全局废弃”(Abort)命令给各个参与者,否则,在其日志中写入一条“决定提交”(Commit)的记录,向所有参与者发送“全局提交”(Commit)命令。此时,协调者再次进入等待状态,等待收集各参与者的确认信息;
d.各个参与者接收到协调者发来的命令后,判断该命令类型,若为“全局提交”命令,则在其日志文件中写入一条“提交”(Commit)的记录,并对子事务实施提交,否则,参与者在其日志文件中写入一条“废弃”(Abort)的记录,并对子事务实施废弃。实施完毕后,各个参与者要向协调者发送确认信息(Ack);
e.当协调者接收到所有参与者发送的确认信息后,在其日志文件中写入“事务结束”(End_transaction)记录,全局事务终止。
消息事务+最终一致性
1、原理

a、A系统向消息中间件发送一条预备消息
b、消息中间件保存预备消息并返回成功
c、A执行本地事务
d、A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
步骤一出错,则整个事务失败,不会执行A的本地操作
步骤二出错,则整个事务失败,不会执行A的本地操作
步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:

虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
TCC 分布式事务
1、业务背景描述
咱们先来看看业务场景,假设你现在有一个电商系统,里面有一个支付订单的场景。

那对一个订单支付之后,我们需要做下面的步骤:
- 更改订单的状态为“已支付”
- 扣减商品库存
- 给会员增加积分
- 创建销售出库单通知仓库发货
这是一系列比较真实的步骤,无论大家有没有做过电商系统,应该都能理解。
好,业务场景有了,现在我们要更进一步,实现一个 TCC 分布式事务的效果。
什么意思呢?也就是说,[1] 订单服务-修改订单状态,[2] 库存服务-扣减库存,[3] 积分服务-增加积分,[4] 仓储服务-创建销售出库单。
上述这几个步骤,要么一起成功,要么一起失败,必须是一个整体性的事务。
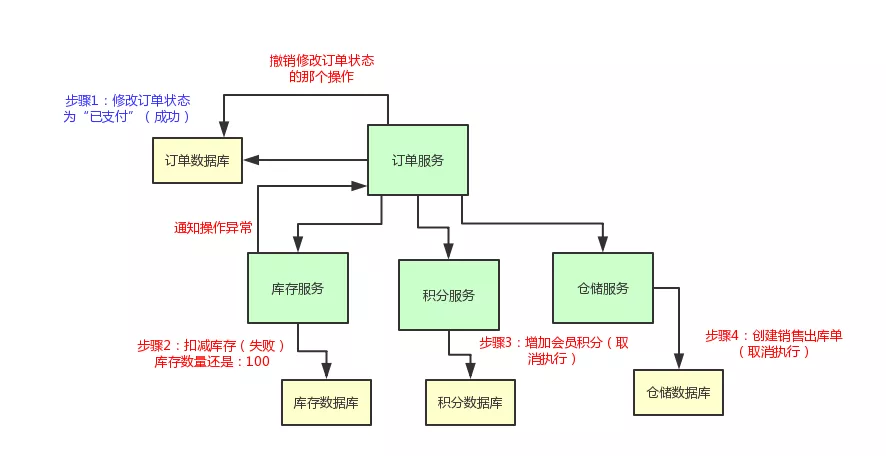
举个例子,现在订单的状态都修改为“已支付”了,结果库存服务扣减库存失败。那个商品的库存原来是 100 件,现在卖掉了 2 件,本来应该是 98 件了。
结果呢?由于库存服务操作数据库异常,导致库存数量还是 100。这不是在坑人么,当然不能允许这种情况发生了!
但是如果你不用 TCC 分布式事务方案的话,就用个 Spring Cloud 开发这么一个微服务系统,很有可能会干出这种事儿来。
我们来看看下面的这个图,直观的表达了上述的过程:
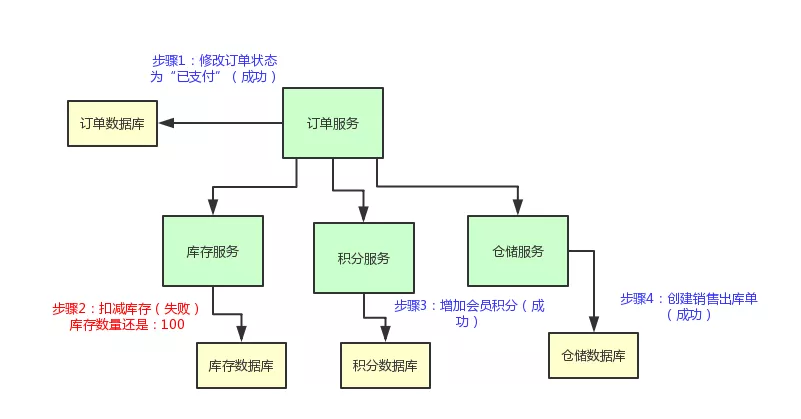
所以说,我们有必要使用 TCC 分布式事务机制来保证各个服务形成一个整体性的事务。
上面那几个步骤,要么全部成功,如果任何一个服务的操作失败了,就全部一起回滚,撤销已经完成的操作。
比如说库存服务要是扣减库存失败了,那么订单服务就得撤销那个修改订单状态的操作,然后得停止执行增加积分和通知出库两个操作。
说了那么多,老规矩,给大家上一张图,大伙儿顺着图来直观的感受一下:
2、落地实现
以一个 Spring Cloud 开发系统作为背景来解释。
a、try:
首先,订单服务那儿,它的代码大致来说应该是这样子的:
public class OrderService { // 库存服务 @Autowired private InventoryService inventoryService; // 积分服务 @Autowired private CreditService creditService; // 仓储服务 @Autowired private WmsService wmsService; // 对这个订单完成支付 public void pay(){ //对本地的的订单数据库修改订单状态为"已支付" orderDAO.updateStatus(OrderStatus.PAYED); //调用库存服务扣减库存 inventoryService.reduceStock(); //调用积分服务增加积分 creditService.addCredit(); //调用仓储服务通知发货 wmsService.saleDelivery(); } }
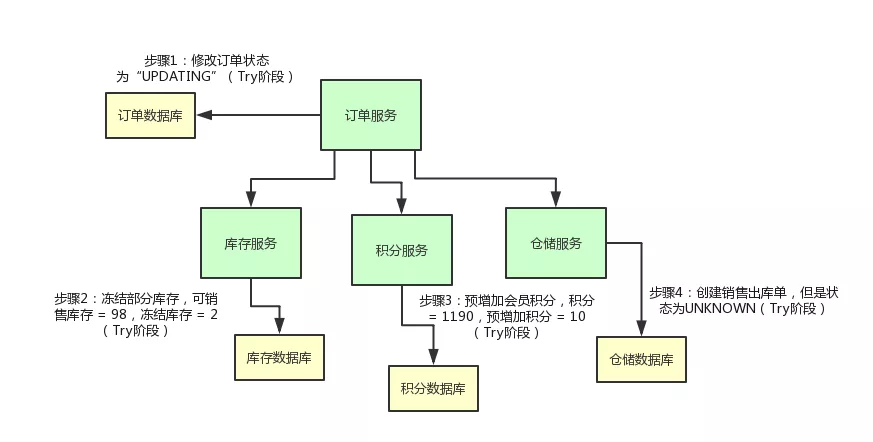
首先,上面那个订单服务先把自己的状态修改为:OrderStatus.UPDATING。
这是啥意思呢?也就是说,在 pay() 那个方法里,你别直接把订单状态修改为已支付啊!你先把订单状态修改为 UPDATING,也就是修改中的意思。
这个状态是个没有任何含义的这么一个状态,代表有人正在修改这个状态罢了。
然后呢,库存服务直接提供的那个 reduceStock() 接口里,也别直接扣减库存啊,你可以是冻结掉库存。
举个例子,本来你的库存数量是 100,你别直接 100 - 2 = 98,扣减这个库存!
你可以把可销售的库存:100 - 2 = 98,设置为 98 没问题,然后在一个单独的冻结库存的字段里,设置一个 2。也就是说,有 2 个库存是给冻结了。
积分服务的 addCredit() 接口也是同理,别直接给用户增加会员积分。你可以先在积分表里的一个预增加积分字段加入积分。
比如:用户积分原本是 1190,现在要增加 10 个积分,别直接 1190 + 10 = 1200 个积分啊!
你可以保持积分为 1190 不变,在一个预增加字段里,比如说 prepare_add_credit 字段,设置一个 10,表示有 10 个积分准备增加。
仓储服务的 saleDelivery() 接口也是同理啊,你可以先创建一个销售出库单,但是这个销售出库单的状态是“UNKNOWN”。
也就是说,刚刚创建这个销售出库单,此时还不确定它的状态是什么呢!
上面这套改造接口的过程,其实就是所谓的 TCC 分布式事务中的第一个 T 字母代表的阶段,也就是 Try 阶段。
总结上述过程,如果你要实现一个 TCC 分布式事务,首先你的业务的主流程以及各个接口提供的业务含义,不是说直接完成那个业务操作,而是完成一个 Try 的操作。
这个操作,一般都是锁定某个资源,设置一个预备类的状态,冻结部分数据,等等,大概都是这类操作。
咱们来一起看看下面这张图,结合上面的文字,再来捋一捋整个过程:
b、 confirm
然后就分成两种情况了,第一种情况是比较理想的,那就是各个服务执行自己的那个 Try 操作,都执行成功了,Bingo!
这个时候,就需要依靠 TCC 分布式事务框架来推动后续的执行了。这里简单提一句,如果你要玩儿 TCC 分布式事务,必须引入一款 TCC 分布式事务框架,比如国内开源的 ByteTCC、Himly、TCC-transaction。
否则的话,感知各个阶段的执行情况以及推进执行下一个阶段的这些事情,不太可能自己手写实现,太复杂了。
如果你在各个服务里引入了一个 TCC 分布式事务的框架,订单服务里内嵌的那个 TCC 分布式事务框架可以感知到,各个服务的 Try 操作都成功了。
此时,TCC 分布式事务框架会控制进入 TCC 下一个阶段,第一个 C 阶段,也就是 Confirm 阶段。
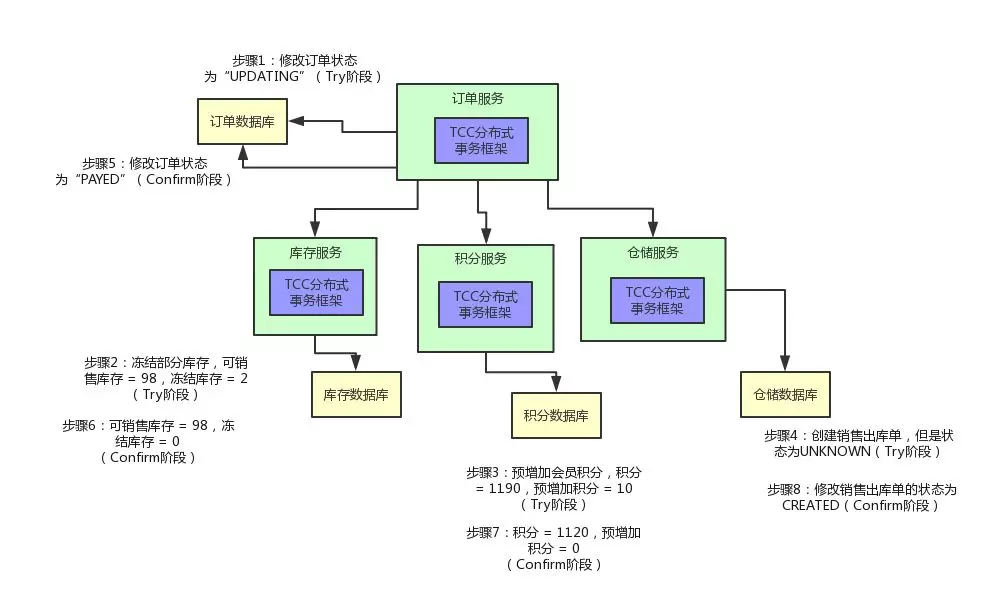
为了实现这个阶段,你需要在各个服务里再加入一些代码。比如说,订单服务里,你可以加入一个 Confirm 的逻辑,就是正式把订单的状态设置为“已支付”了,大概是类似下面这样子:
public class OrderServiceConfirm { public void pay(){ orderDao.updateStatus(OrderStatus.PAYED); } }
库存服务也是类似的,你可以有一个 InventoryServiceConfirm 类,里面提供一个 reduceStock() 接口的 Confirm 逻辑,这里就是将之前冻结库存字段的 2 个库存扣掉变为 0。
这样的话,可销售库存之前就已经变为 98 了,现在冻结的 2 个库存也没了,那就正式完成了库存的扣减。
积分服务也是类似的,可以在积分服务里提供一个 CreditServiceConfirm 类,里面有一个 addCredit() 接口的 Confirm 逻辑,就是将预增加字段的 10 个积分扣掉,然后加入实际的会员积分字段中,从 1190 变为 1120。
仓储服务也是类似,可以在仓储服务中提供一个 WmsServiceConfirm 类,提供一个 saleDelivery() 接口的 Confirm 逻辑,将销售出库单的状态正式修改为“已创建”,可以供仓储管理人员查看和使用,而不是停留在之前的中间状态“UNKNOWN”了。
好了,上面各种服务的 Confirm 的逻辑都实现好了,一旦订单服务里面的 TCC 分布式事务框架感知到各个服务的 Try 阶段都成功了以后,就会执行各个服务的 Confirm 逻辑。
订单服务内的 TCC 事务框架会负责跟其他各个服务内的 TCC 事务框架进行通信,依次调用各个服务的 Confirm 逻辑。然后,正式完成各个服务的所有业务逻辑的执行。
同样,给大家来一张图,顺着图一起来看看整个过程:
c、confirm
3|3TCC 实现阶段三:Cancel
好,这是比较正常的一种情况,那如果是异常的一种情况呢?
举个例子:在 Try 阶段,比如积分服务吧,它执行出错了,此时会怎么样?
那订单服务内的 TCC 事务框架是可以感知到的,然后它会决定对整个 TCC 分布式事务进行回滚。
也就是说,会执行各个服务的第二个 C 阶段,Cancel 阶段。同样,为了实现这个 Cancel 阶段,各个服务还得加一些代码。
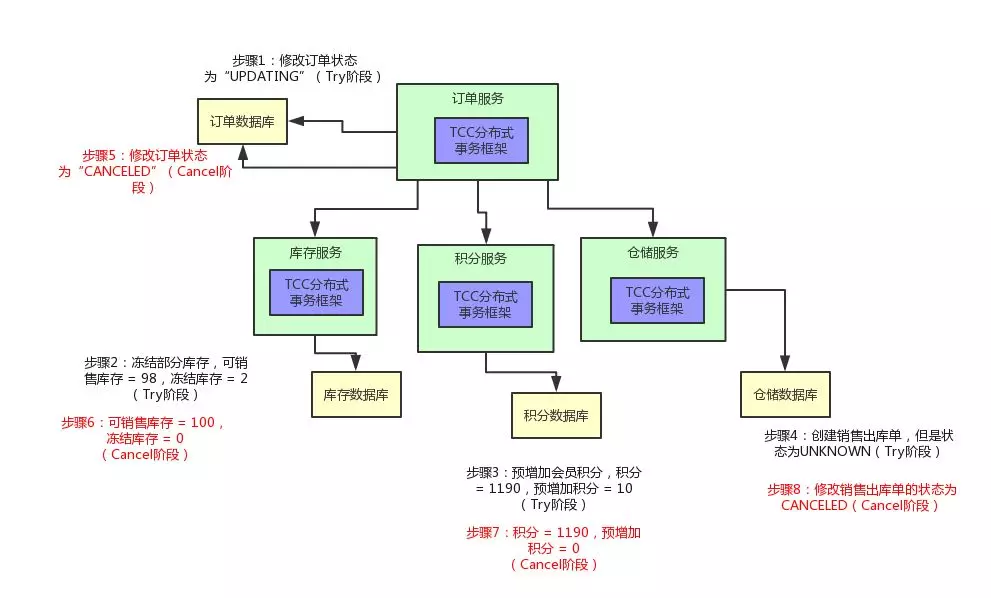
首先订单服务,它得提供一个 OrderServiceCancel 的类,在里面有一个 pay() 接口的 Cancel 逻辑,就是可以将订单的状态设置为“CANCELED”,也就是这个订单的状态是已取消。
库存服务也是同理,可以提供 reduceStock() 的 Cancel 逻辑,就是将冻结库存扣减掉 2,加回到可销售库存里去,98 + 2 = 100。
积分服务也需要提供 addCredit() 接口的 Cancel 逻辑,将预增加积分字段的 10 个积分扣减掉。
仓储服务也需要提供一个 saleDelivery() 接口的 Cancel 逻辑,将销售出库单的状态修改为“CANCELED”设置为已取消。
然后这个时候,订单服务的 TCC 分布式事务框架只要感知到了任何一个服务的 Try 逻辑失败了,就会跟各个服务内的 TCC 分布式事务框架进行通信,然后调用各个服务的 Cancel 逻辑。
大家看看下面的图,直观的感受一下:
总结一下,你要玩儿 TCC 分布式事务的话:首先需要选择某种 TCC 分布式事务框架,各个服务里就会有这个 TCC 分布式事务框架在运行。
然后你原本的一个接口,要改造为 3 个逻辑,Try-Confirm-Cancel:
- 先是服务调用链路依次执行 Try 逻辑。
- 如果都正常的话,TCC 分布式事务框架推进执行 Confirm 逻辑,完成整个事务。
- 如果某个服务的 Try 逻辑有问题,TCC 分布式事务框架感知到之后就会推进执行各个服务的 Cancel 逻辑,撤销之前执行的各种操作。
这就是所谓的 TCC 分布式事务。TCC 分布式事务的核心思想,说白了,就是当遇到下面这些情况时:
- 某个服务的数据库宕机了。
- 某个服务自己挂了。
- 那个服务的 Redis、Elasticsearch、MQ 等基础设施故障了。
- 某些资源不足了,比如说库存不够这些。
先来 Try 一下,不要把业务逻辑完成,先试试看,看各个服务能不能基本正常运转,能不能先冻结我需要的资源。
如果 Try 都 OK,也就是说,底层的数据库、Redis、Elasticsearch、MQ 都是可以写入数据的,并且你保留好了需要使用的一些资源(比如冻结了一部分库存)。
接着,再执行各个服务的 Confirm 逻辑,基本上 Confirm 就可以很大概率保证一个分布式事务的完成了。
那如果 Try 阶段某个服务就失败了,比如说底层的数据库挂了,或者 Redis 挂了,等等。
此时就自动执行各个服务的 Cancel 逻辑,把之前的 Try 逻辑都回滚,所有服务都不要执行任何设计的业务逻辑。保证大家要么一起成功,要么一起失败。
等一等,你有没有想到一个问题?如果有一些意外的情况发生了,比如说订单服务突然挂了,然后再次重启,TCC 分布式事务框架是如何保证之前没执行完的分布式事务继续执行的呢?
所以,TCC 事务框架都是要记录一些分布式事务的活动日志的,可以在磁盘上的日志文件里记录,也可以在数据库里记录。保存下来分布式事务运行的各个阶段和状态。
问题还没完,万一某个服务的 Cancel 或者 Confirm 逻辑执行一直失败怎么办呢?
那也很简单,TCC 事务框架会通过活动日志记录各个服务的状态。举个例子,比如发现某个服务的 Cancel 或者 Confirm 一直没成功,会不停的重试调用它的 Cancel 或者 Confirm 逻辑,务必要它成功!
当然了,如果你的代码没有写什么 Bug,有充足的测试,而且 Try 阶段都基本尝试了一下,那么其实一般 Confirm、Cancel 都是可以成功的!
最后,再给大家来一张图,来看看给我们的业务,加上分布式事务之后的整个执行流程:

不少大公司里,其实都是自己研发 TCC 分布式事务框架的,专门在公司内部使用,比如我们就是这样。
不过如果自己公司没有研发 TCC 分布式事务框架的话,那一般就会选用开源的框架。
这里笔者给大家推荐几个比较不错的框架,都是咱们国内自己开源出去的:ByteTCC,TCC-transaction,Himly。