锁
概念
锁是计算机协调多个进程或线程并发访问某一资源的机制。 在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
分类
1、从对数据操作的类型(读写)分
读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁。
2、从对数据操作的粒度分
为了尽可能提高数据库的并发度,每次锁定的数据范围越小越好,理论上每次只锁定当前操作的数据的方案会得到最大的并发度,但是管理锁是很耗资源的事情(涉及获取,检查,释放锁等动作),因此数据库系统需要在高并发响应和系统性能两方面进行平衡,这样就产生了“锁粒度(Lock granularity)”的概念。一种提高共享资源并发发性的方式是让锁定对象更有选择性。尽量只锁定需要修改的部分数据,而不是所有的资源。更理想的方式是,只对会修改的数据片进行精确的锁定。任何时候,在给定的资源上,锁定的数据量越少,则系统的并发程度越高,只要相互之间不发生冲突即可。
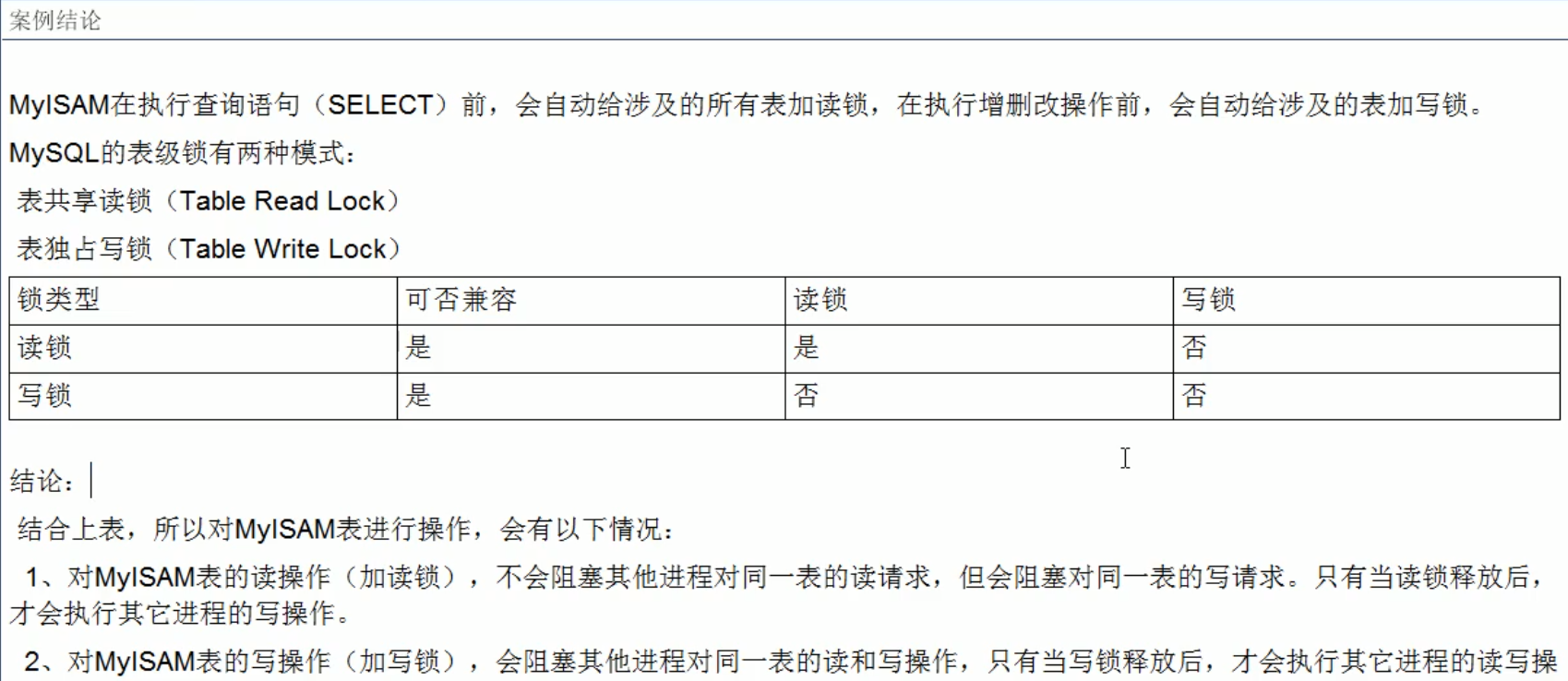
表锁(偏读)-----因为写多了的话,会造成N个线程出现阻塞
行锁(偏写)
页锁
表锁(偏读)
建表语句
【表级锁分析--建表SQL】 create table mylock( id int not null primary key auto_increment, name varchar(20) )engine myisam; insert into mylock(name) values('a'); insert into mylock(name) values('b'); insert into mylock(name) values('c'); insert into mylock(name) values('d'); insert into mylock(name) values('e'); select * from mylock; 【手动增加表锁】 lock table 表名字1 read(write),表名字2 read(write),其它; 【查看表上加过的锁】 show open tables; 【释放表锁】 unlock tables;
案例分析
读锁




写锁
lock table mylock write;
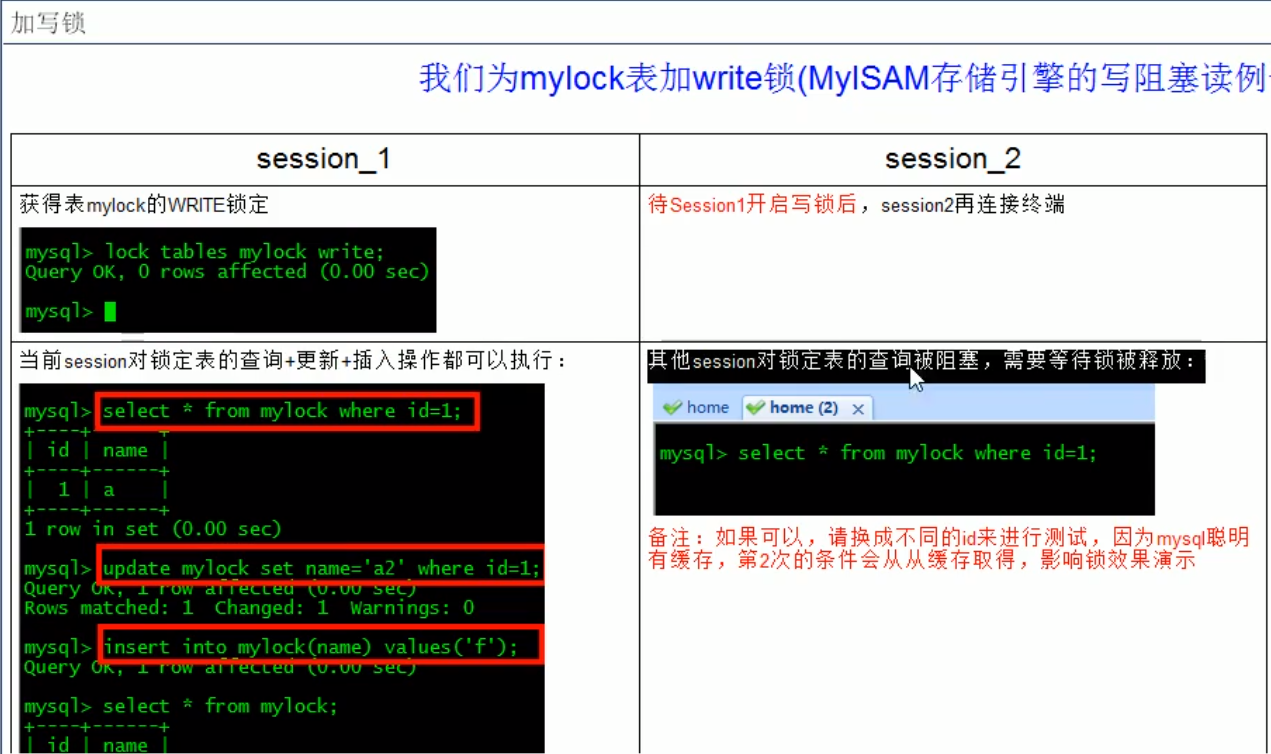
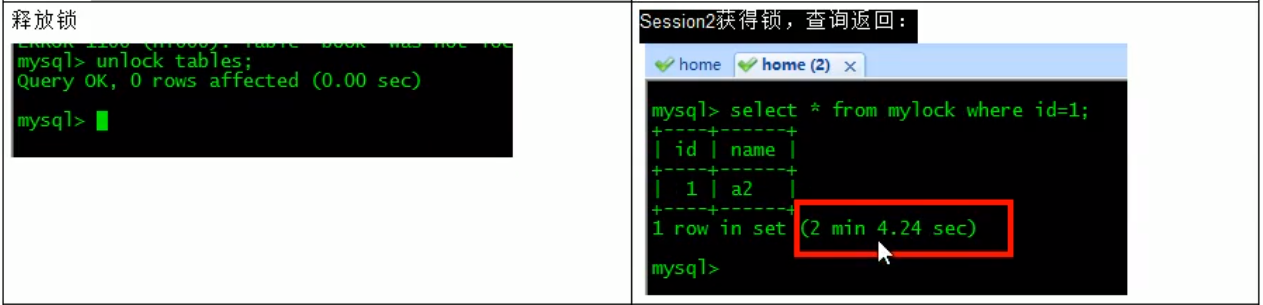
总结:
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
锁表分析
#查看哪些表被锁了 show open tables;
#如何分析表锁定 #可以通过检查table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定: show status like 'table%';



行锁(偏写)
- 偏向InnoDB存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁
并发事务处理带来的问题
更新丢失(Lost Update)-----相当于svn中的版本覆盖,A跟B更改了同一文件,A覆盖了B的记录
脏读(Dirty Reads)-----事务A读取到了事务B已修改但尚未提交的数据,还在这个数据基础上做了操作。此时,如果B事务回滚,A读取的数据无效,不符合一致性要求
不可重复读(Non-Repeatable Reads) -----事务A读取到了事务B已经提交的修改数据,不符合隔离性
幻读(Phantom Reads) -----事务A读取到了事务B提交的新增数据,不符合隔离性
事务隔离级别

建表
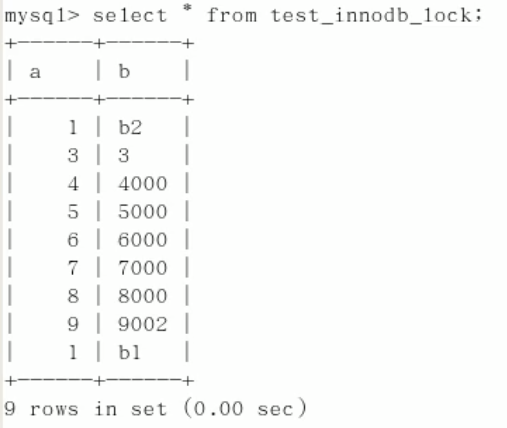
CREATE TABLE test_innodb_lock ( a int(11), b varchar(16) ) ENGINE = innodb; INSERT INTO test_innodb_lock VALUES (1, 'b2'); INSERT INTO test_innodb_lock VALUES (3, '3'); INSERT INTO test_innodb_lock VALUES (4, '4000'); INSERT INTO test_innodb_lock VALUES (5, '5000'); INSERT INTO test_innodb_lock VALUES (6, '6000'); INSERT INTO test_innodb_lock VALUES (7, '7000'); INSERT INTO test_innodb_lock VALUES (8, '8000'); INSERT INTO test_innodb_lock VALUES (9, '9000'); INSERT INTO test_innodb_lock VALUES (1, 'b1'); CREATE INDEX test_innodb_a_ind ON test_innodb_lock (a); CREATE INDEX test_innodb_lock_b_ind ON test_innodb_lock (b); SELECT * FROM test_innodb_lock;
案例分析
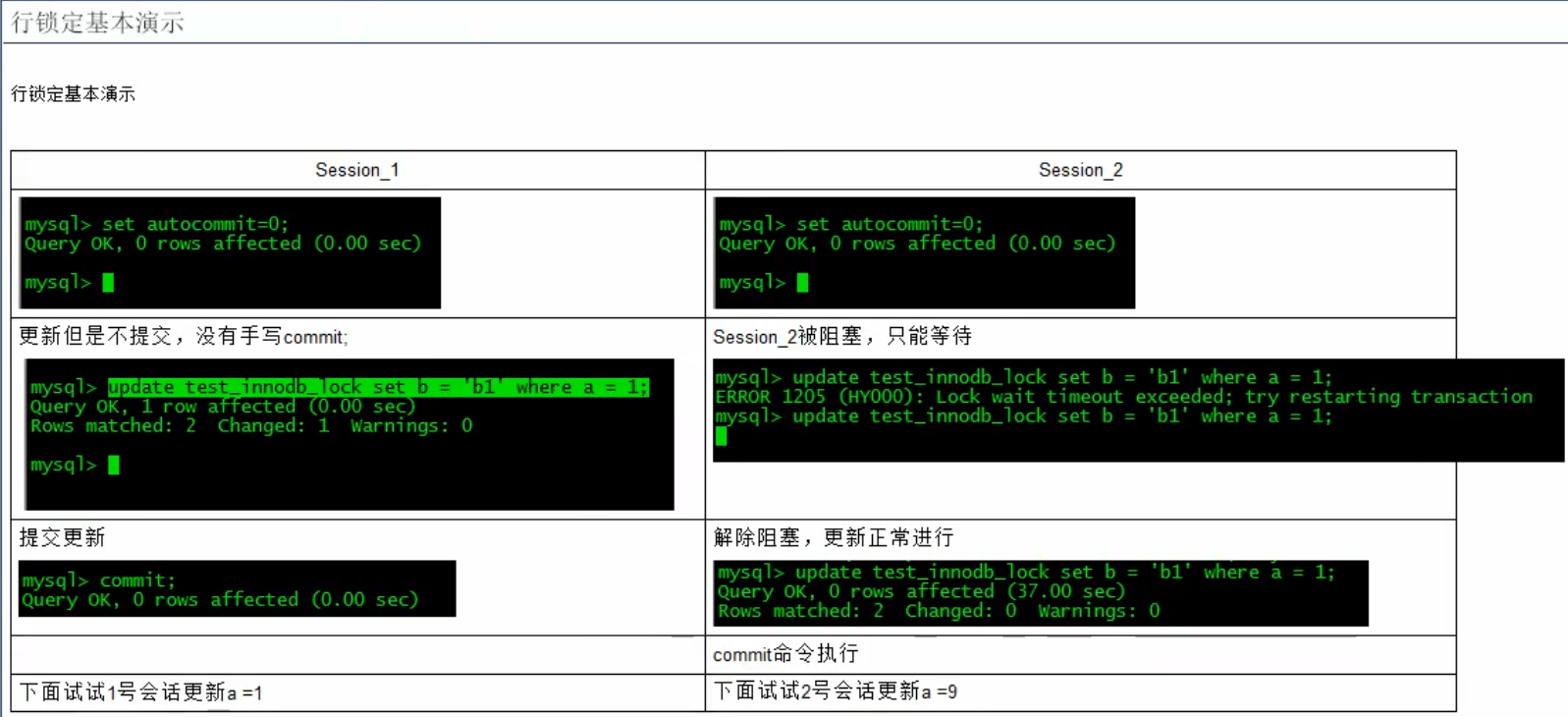
问题:行锁变表锁
Session_1Session_2正常情况,各自锁定各自的行,互相不影响,一个2000另一个3000由于在column字段b上面建了索引,如果没有正常使用,会导致行锁变表锁比如没加单引号导致索引失效,行锁变表锁被阻塞,等待。只到Session_1提交后才阻塞解除,完成更新
行锁总结
Innodb存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面所带来的性能损耗可能比表级锁定会要更高一些,但是在整体并发处理能力方面要远远优于MyISAM的表级锁定的。当系统并发量较高的时候,Innodb的整体性能和MyISAM相比就会有比较明显的优势了。 但是,Innodb的行级锁定同样也有其脆弱的一面,当我们使用不当的时候,可能会让Innodb的整体性能表现不仅不能比MyISAM高,甚至可能会更差。
间隙锁
间隙锁带来的插入问题 Session_1Session_2阻塞产生,暂时不能插入commit;阻塞解除,完成插入
【什么是间隙锁】当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(GAP Lock)。
【危害】因为Query执行过程中通过过范围查找的话,他会锁定整个范围内所有的索引键值,即使这个键值并不存在。间隙锁有一个比较致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定键值范围内的任何数据。在某些场景下这可能会对性能造成很大的危害
举例说明:

对上表中的内容执行update,范围为a>1 and a<6,暂时不commit
现在再插入:

2在1~6范围内,会阻塞很久,损害性能。
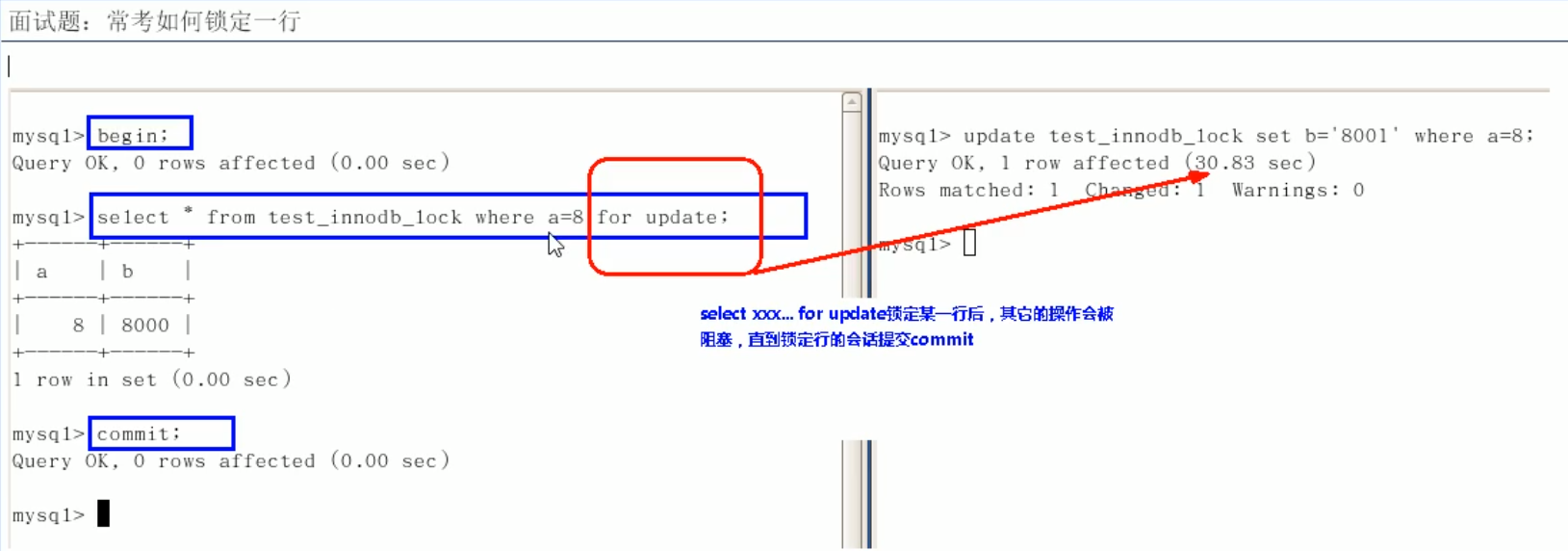
如何锁定一行?
主从复制
mysql复制原理
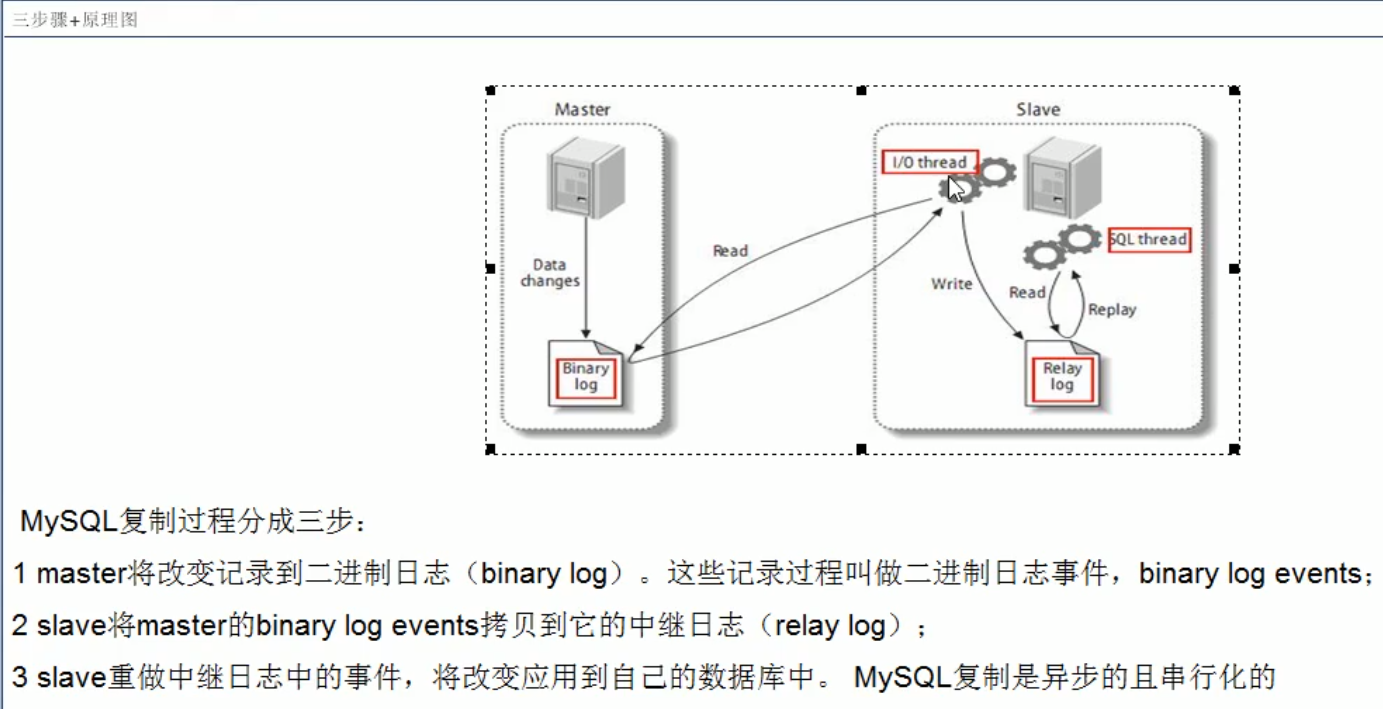
复制基本原则
- 每个slave只有一个master
- 每个slave只能有一个唯一的服务器ID
- 每个master可以有多个salve
一主一从常见配置
1、mysql版本一致且后台以服务运行-----保证master与salve能互相ping的通,保证通信没有问题
2、主从都配置在[mysqld]结点下,都是小写
3、主机修改my.ini配置文件
- a、[必须]主服务器唯一ID-----server-id=1
- b、[必须]启用二进制日志-----log-bin=自己本地的路径/data/mysqlbin(eg:log-bin=D:/devSoft/MySQLServer5.5/data/mysqlbin)
- c、[可选]启用错误日志-----log-err=自己本地的路径/data/mysqlerr(eg:log-err=D:/devSoft/MySQLServer5.5/data/mysqlerr)
- d、[可选]根目录-----basedir="自己本地路径"(eg:basedir="D:/devSoft/MySQLServer5.5/")
- e、[可选]临时目录-----tmpdir="自己本地路径"(eg:tmpdir="D:/devSoft/MySQLServer5.5/")
- f、[可选]数据目录-----datadir="自己本地路径/Data/"(eg:datadir="D:/devSoft/MySQLServer5.5/Data/")
- g、read-only=0-----主机,读写都可以
- h、[可选]设置不要复制的数据库-----binlog-ignore-db=mysql
- i、[可选]设置需要复制的数据库-----binlog-do-db=需要复制的主数据库名字
4、从机修改my.cnf配置文件
- a、[必须]从服务器唯一ID-----server-id=2
- b、[可选]启用二进制日志
5、因修改过配置文件,请主机+从机都重启后台mysql服务
6、主机从机都关闭防火墙
- a、windows手动关闭
- b、关闭虚拟机linux防火墙 service iptables stop
7、在Windows主机上建立帐户并授权slave
a、授权
GRANT REPLICATION SLAVE ON *.* TO 'zhangsan'@'从机器数据库IP' IDENTIFIED BY '123456';
b、刷新
flush privileges;
c、查询master的状态
show master status;
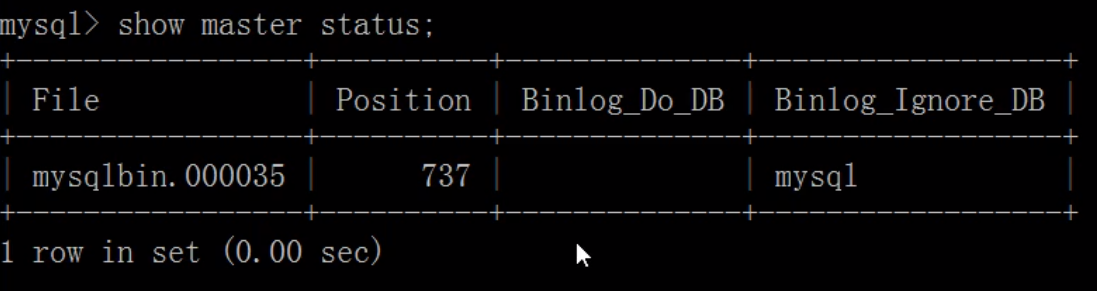
并且记录下File和Position的值。执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化。
8、在Linux从机上配置需要复制的主机
a、告诉从机在master上哪个文件的哪个行开始照抄做备份
CHANGE MASTER TO MASTER_HOST='主机IP',MASTER_USER='zhangsan',MASTER_PASSWORD='123456',MASTER_LOG_FILE='File名字',MASTER_LOG_POS=Position数字;
b、启动从服务器复制功能
start slave;
c、查看状态
show slave statusG
下面两个参数都是Yes,则说明主从配置成功!
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
到此步,代表主从搭建完成
如何停止从服务复制功能
stop slave;