0.写在前面
MyBatis是一个简单,小巧但功能非常强大的ORM开源框架,它的功能强大也体现在它的缓存机制上。MyBatis提供了一级缓存、二级缓存 这两个缓存机制,能够很好地处理和维护缓存,以提高系统的性能。本文的目的则是向读者详细介绍MyBatis的一级缓存,深入源码,解析MyBatis一级缓存的实现原理,并且针对一级缓存的特点提出了在实际使用过程中应该注意的事项。
1. 什么是一级缓存? 为什么使用一级缓存?
每当我们使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话。
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
如下图所示,MyBatis会在一次会话的表示----一个SqlSession对象中创建一个本地缓存(local cache),对于每一次查询,都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;否则,从数据库读取数据,将查询结果存入缓存并返回给用户。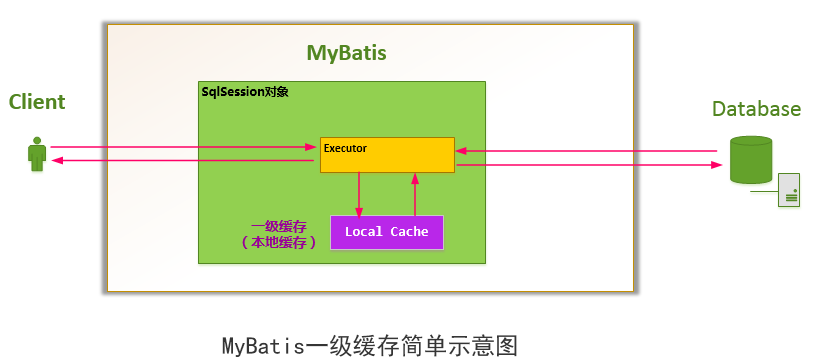
对于会话(Session)级别的数据缓存,我们称之为一级数据缓存,简称一级缓存。
2. MyBatis中的一级缓存是怎样组织的?(即SqlSession中的缓存是怎样组织的?)
由于MyBatis使用SqlSession对象表示一次数据库的会话,那么,对于会话级别的一级缓存也应该是在SqlSession中控制的。
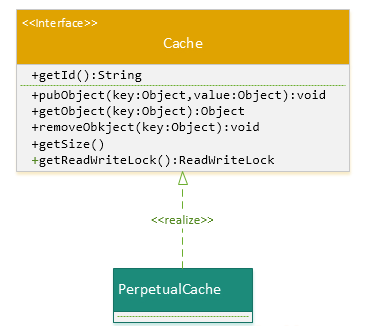
实际上, MyBatis只是一个MyBatis对外的接口,SqlSession将它的工作交给了Executor执行器这个角色来完成,负责完成对数据库的各种操作。当创建了一个SqlSession对象时,MyBatis会为这个SqlSession对象创建一个新的Executor执行器,而缓存信息就被维护在这个Executor执行器中,MyBatis将缓存和对缓存相关的操作封装成了Cache接口中。SqlSession、Executor、Cache之间的关系如下列类图所示: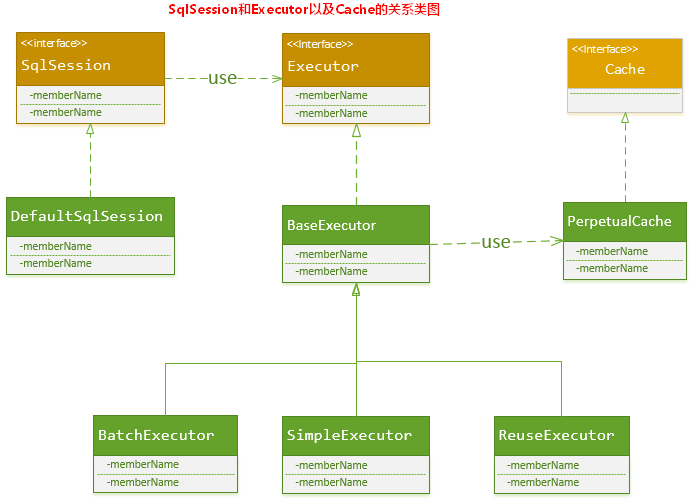
如上述的类图所示,Executor接口的实现类BaseExecutor中拥有一个Cache接口的实现类PerpetualCache,则对于BaseExecutor对象而言,它将使用PerpetualCache对象维护缓存。
综上,SqlSession对象、Executor对象、Cache对象之间的关系如下图所示:
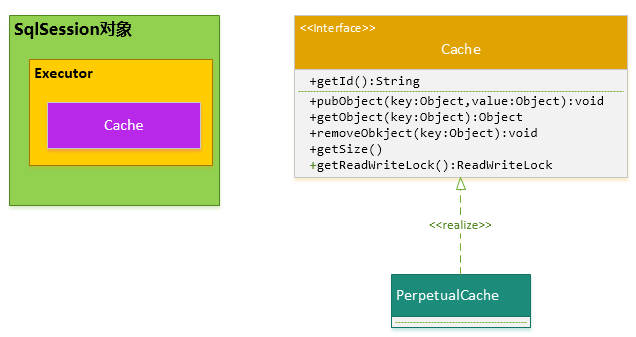
由于Session级别的一级缓存实际上就是使用PerpetualCache维护的,那么PerpetualCache是怎样实现的呢?
PerpetualCache实现原理其实很简单,其内部就是通过一个简单的HashMap<k,v> 来实现的,没有其他的任何限制。如下是PerpetualCache的实现代码:
package org.apache.ibatis.cache.impl; import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReadWriteLock; import org.apache.ibatis.cache.Cache; import org.apache.ibatis.cache.CacheException; /** * 使用简单的HashMap来维护缓存 * @author Clinton Begin */ public class PerpetualCache implements Cache { private String id; private Map<Object, Object> cache = new HashMap<Object, Object>(); public PerpetualCache(String id) { this.id = id; } public String getId() { return id; } public int getSize() { return cache.size(); } public void putObject(Object key, Object value) { cache.put(key, value); } public Object getObject(Object key) { return cache.get(key); } public Object removeObject(Object key) { return cache.remove(key); } public void clear() { cache.clear(); } public ReadWriteLock getReadWriteLock() { return null; } public boolean equals(Object o) { if (getId() == null) throw new CacheException("Cache instances require an ID."); if (this == o) return true; if (!(o instanceof Cache)) return false; Cache otherCache = (Cache) o; return getId().equals(otherCache.getId()); } public int hashCode() { if (getId() == null) throw new CacheException("Cache instances require an ID."); return getId().hashCode(); } }
3.一级缓存的生命周期有多长?
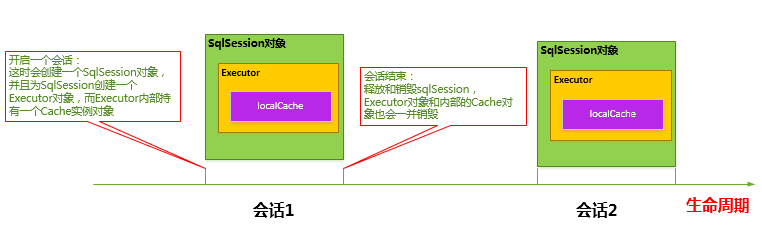
- a. MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
- b. 如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
- c. 如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
- d.SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
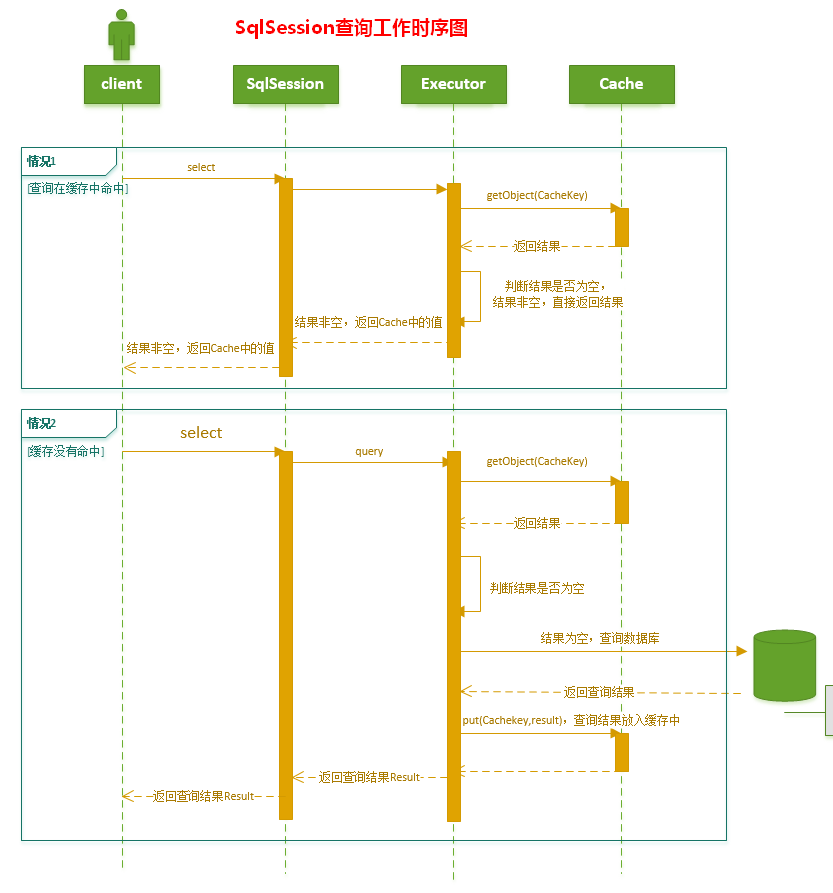
4. SqlSession 一级缓存的工作流程:
- 1.对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果;
- 2. 判断从Cache中根据特定的key值取的数据数据是否为空,即是否命中;
- 3. 如果命中,则直接将缓存结果返回;
- 4. 如果没命中:
- 4.1 去数据库中查询数据,得到查询结果;
- 4.2 将key和查询到的结果分别作为key,value对存储到Cache中;
- 4.3. 将查询结果返回;
- 5. 结束。
5. Cache接口的设计以及CacheKey的定义(非常重要)
如下图所示,MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Service Provider Interface) ,所有的MyBatis内部的Cache缓存,都应该实现这一接口。MyBatis定义了一个PerpetualCache实现类实现了Cache接口,实际上,在SqlSession对象里的Executor 对象内维护的Cache类型实例对象,就是PerpetualCache子类创建的。(MyBatis内部还有很多Cache接口的实现,一级缓存只会涉及到这一个PerpetualCache子类,Cache的其他实现将会放到二级缓存中介绍)。
我们知道,Cache最核心的实现其实就是一个Map,将本次查询使用的特征值作为key,将查询结果作为value存储到Map中。
现在最核心的问题出现了:怎样来确定一次查询的特征值?
换句话说就是:怎样判断某两次查询是完全相同的查询?
也可以这样说:如何确定Cache中的key值?
MyBatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
- 1. 传入的 statementId
- 2. 查询时要求的结果集中的结果范围 (结果的范围通过rowBounds.offset和rowBounds.limit表示);
- 3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
- 4. 传递给java.sql.Statement要设置的参数值
现在分别解释上述四个条件:
1. 传入的statementId,对于MyBatis而言,你要使用它,必须需要一个statementId,它代表着你将执行什么样的Sql;
2. MyBatis自身提供的分页功能是通过RowBounds来实现的,它通过rowBounds.offset和rowBounds.limit来过滤查询出来的结果集,这种分页功能是基于查询结果的再过滤,而不是进行数据库的物理分页;
由于MyBatis底层还是依赖于JDBC实现的,那么,对于两次完全一模一样的查询,MyBatis要保证对于底层JDBC而言,也是完全一致的查询才行。而对于JDBC而言,两次查询,只要传入给JDBC的SQL语句完全一致,传入的参数也完全一致,就认为是两次查询是完全一致的。
上述的第3个条件正是要求保证传递给JDBC的SQL语句完全一致;第4条则是保证传递给JDBC的参数也完全一致;
3、4讲的有可能比较含糊,举一个例子:
<select id="selectByCritiera" parameterType="java.util.Map" resultMap="BaseResultMap"> select employee_id,first_name,last_name,email,salary from louis.employees where employee_id = #{employeeId} and first_name= #{firstName} and last_name = #{lastName} and email = #{email} </select>
如果使用上述的"selectByCritiera"进行查询,那么,MyBatis会将上述的SQL中的#{} 都替换成 ? 如下:
select employee_id,first_name,last_name,email,salary
from louis.employees
where employee_id = ?
and first_name= ?
and last_name = ?
and email = ?
MyBatis最终会使用上述的SQL字符串创建JDBC的java.sql.PreparedStatement对象,对于这个PreparedStatement对象,还需要对它设置参数,调用setXXX()来完成设值,第4条的条件,就是要求对设置JDBC的PreparedStatement的参数值也要完全一致。
即3、4两条MyBatis最本质的要求就是:调用JDBC的时候,传入的SQL语句要完全相同,传递给JDBC的参数值也要完全相同。
综上所述,CacheKey由以下条件决定:
statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值
一级缓存的性能分析
我将从两个 一级缓存的特性来讨论SqlSession的一级缓存性能问题:
1.MyBatis对会话(Session)级别的一级缓存设计的比较简单,就简单地使用了HashMap来维护,并没有对HashMap的容量和大小进行限制。
读者有可能就觉得不妥了:如果我一直使用某一个SqlSession对象查询数据,这样会不会导致HashMap太大,而导致 java.lang.OutOfMemoryError错误啊? 读者这么考虑也不无道理,不过MyBatis的确是这样设计的。
MyBatis这样设计也有它自己的理由:
- a. 一般而言SqlSession的生存时间很短。一般情况下使用一个SqlSession对象执行的操作不会太多,执行完就会消亡;
- b. 对于某一个SqlSession对象而言,只要执行update操作(update、insert、delete),都会将这个SqlSession对象中对应的一级缓存清空掉,所以一般情况下不会出现缓存过大,影响JVM内存空间的问题;
- c. 可以手动地释放掉SqlSession对象中的缓存。
2. 一级缓存是一个粗粒度的缓存,没有更新缓存和缓存过期的概念
MyBatis的一级缓存就是使用了简单的HashMap,MyBatis只负责将查询数据库的结果存储到缓存中去, 不会去判断缓存存放的时间是否过长、是否过期,因此也就没有对缓存的结果进行更新这一说了。
根据一级缓存的特性,在使用的过程中,我认为应该注意:
- 1、对于数据变化频率很大,并且需要高时效准确性的数据要求,我们使用SqlSession查询的时候,要控制好SqlSession的生存时间,SqlSession的生存时间越长,它其中缓存的数据有可能就越旧,从而造成和真实数据库的误差;同时对于这种情况,用户也可以手动地适时清空SqlSession中的缓存;
- 2、对于只执行、并且频繁执行大范围的select操作的SqlSession对象,SqlSession对象的生存时间不应过长。
举例:
例1、看下面这个例子,下面的例子使用了同一个SqlSession指令了两次完全一样的查询,将两次查询所耗的时间打印出来,结果如下:
package com.louis.mybatis.test; import java.io.InputStream; import java.util.Date; import java.util.HashMap; import java.util.List; import java.util.Map; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.ibatis.executor.BaseExecutor; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.apache.log4j.Logger; import com.louis.mybatis.model.Employee; /** * SqlSession 简单查询演示类 * @author louluan */ public class SelectDemo1 { private static final Logger loger = Logger.getLogger(SelectDemo1.class); public static void main(String[] args) throws Exception { InputStream inputStream = Resources.getResourceAsStream("mybatisConfig.xml"); SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory factory = builder.build(inputStream); SqlSession sqlSession = factory.openSession(); //3.使用SqlSession查询 Map<String,Object> params = new HashMap<String,Object>(); params.put("min_salary",10000); //a.查询工资低于10000的员工 Date first = new Date(); //第一次查询 List<Employee> result = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",params); loger.info("first quest costs:"+ (new Date().getTime()-first.getTime()) +" ms"); Date second = new Date(); result = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",params); loger.info("second quest costs:"+ (new Date().getTime()-second.getTime()) +" ms"); } }
运行结果:

由上面的结果你可以看到,第一次查询耗时464ms,而第二次查询耗时不足1ms,这是因为第一次查询后,MyBatis会将查询结果存储到SqlSession对象的缓存中,当后来有完全相同的查询时,直接从缓存中将结果取出。
例2、对上面的例子做一下修改:在第二次调用查询前,对参数 HashMap类型的params多增加一些无关的值进去,然后再执行,看查询结果:

从结果上看,虽然第二次查询时传递的params参数不一致,但还是从一级缓存中取出了第一次查询的缓存。
读到这里,请读者晓得这一个问题:
MyBatis认为的完全相同的查询,不是指使用sqlSession查询时传递给算起来Session的所有参数值完完全全相同,你只要保证statementId,rowBounds,最后生成的SQL语句,以及这个SQL语句所需要的参数完全一致就可以了。