Connector用于跟客户端建立连接,获取客户端的Socket,交由Container处理。需要解决的问题有监听、协议以及处理器映射等等。
一、Connector设计
Connector要实现的主要功能如下:

设计图如下:

1、ProtocolHandler
Connector中的ProtocolHandler用于处理不同的通信协议,Tomcat主要支持HTTP、AJP协议,并且支持BIO、NIO、APR等I/O方式。ProtocolHandler中使用AbstractEndpoint启动Socket监听,并且根据不同的I/O方式进行分类,例如NIO2Endpoint.
获取到客户端Socket之后,需要根据请求地址映射到具体的容器进行处理。
2、映射规则实现
在获取到客户端的请求之后,需要根据请求地址映射到具体的容器中进行处理,主要是通过Mapper以及MapperListener两个类实现映射功能。
Mapper:维护容器映射信息。
MappListener:实现了ContainerListener以及LifecycleListener接口,在容器组件状态发生变更时,注册或者取消对应的容器映射信息。
因此到目前为止,Tomcat的架构图如下所示:
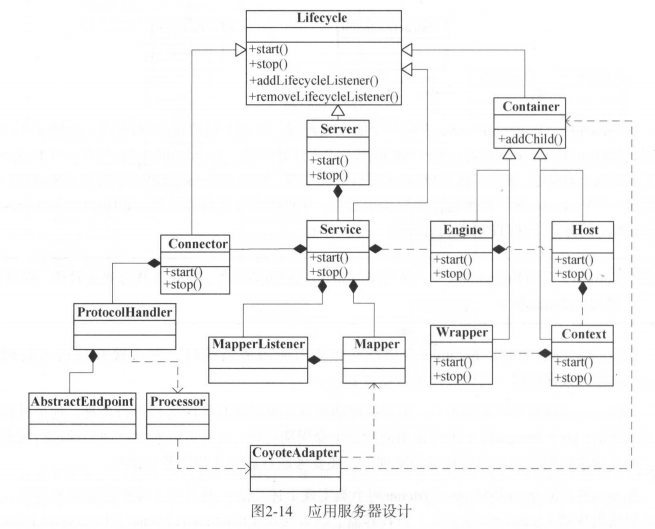
到目前为止,还没有考虑到并发的问题,在客户端大量请求的情况下,使用多线程技术是必不可少的,至于多线程为啥效率高?啥时候用多线程?使用多线程有啥注意事项?自行百度。。。。
Tomcat提供了Executor接口,用于组件中的共享线程池,并且该接口集成了Lifecycle接口。Executor由Service维护,一个Service中的所有容器都可以共享此Executor。加入线程池后的Tomcat结构图如下:
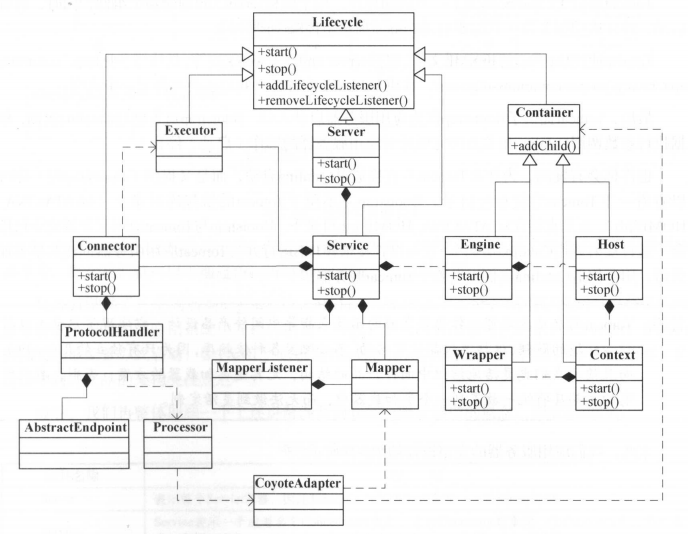
二、Tomcat启动
Tomcat通过Catalina类来启动Tomcat容器,Catalina提供了shell程序,用于解析server.xml文件,负责启动、关闭Tomcat容器。另外Tomcat提供了Bootstrap类作为启动的入口,Bootstrap创建一个Catalina实例。
为啥有了Catalina还需要Bootstrap呢?因为Bootstrap依赖JRE,并通过反射调用Catalina实例,与Tomcat容器是松耦合的。并且为Tomcat创建共享类加载器,构造整个Tomcat服务器。
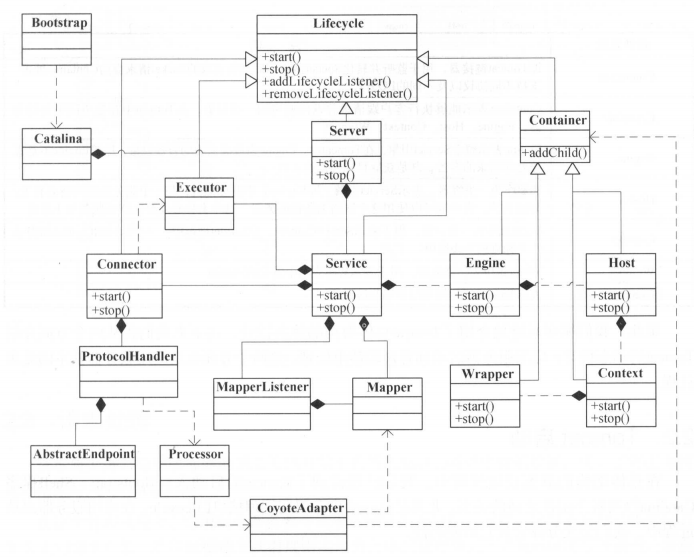
Tomcat启动过程如下:

请求处理过程如下:

三、Catalina
Catalina其实就是Tomcat的servlet容器的实现,是Tomcat的核心,基于Servlet的web应用都需要servlet容器才能对外提供服务,例如SpringMVC等框架也是基于servlet。
1、Digester
Digester是将xml转变为java对象的工具,是对sax的高层次的封装。工作原理就是通过流来读取xml文件,当碰到特定的xml节点执行特定的处理规则,一般为创建对象或是调用对象的某个方法。
加上xml中的标签都是成对出现的,如下所示:
<a...>
<b...>
<c...>
</c...>
</b...>
</a...>
假设各个节点当中的处理规则都是创建对象,当Digester解析到a节点时,创建a对象,等到识别到</a>标签时,此创建a对象的动作才算是完成。因此这里跟JVM中的方法执行是非常相似的,先进后出,因此Digester也是使用的栈结构来解析各个xml文件。
当识别到<a>标签时,将a对象放入到栈中,然后一直执行b、c标签中的各个动作,当创建b对象时,则把b对象放入栈顶,如此循环,b对象创建完毕后,则调用a对象的某个方法,将b对象作为参数放入a中,最后识别到</a>标签时,将对象从整个栈中移除,
因此最终的结果是得到一个对象树,并且子对象与父对象的关系也配置完成。常见的栈操作则如下所示:

四、创建Server
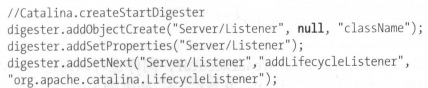
1、创建Server实例

首先通过Catalina创建Digester对象,通过Digester创建Server对象,默认的Server实现类为StandardServer,当然可以通过自行指定实现类。
a、addObjectCreate(String rule, String className, String attributeName)
设置节点与Java对象的映射规则,rule指定节点的筛选规则,className设置要创建的java类的名字,可以覆盖要创建的默认Java类名称。创建完对象后,放入栈顶。
b、addSetProperties(String rule)
此方法则是当遇到符合rule的节点时,将该节点中的属性值获取到,并根据反射将这些属性注入到当前栈顶的对象中;
eg:
<?xml version="1.0" encoding="UTF-8?>
<database>
<user userName="guest" password="guest">
</user>
</database>
digester.addSetProperties("database/user"),解析遇到user节点时,会获取键值对 userName=guest,password=guest,获得栈顶的dataBase对象,设置实例的userName、password属性;
c、addSetNext(String rule, String methodName)
设置当前rule节点与父节点的调用规则,当遇到rule节点时,调用栈中的次栈顶元素调用methodName方法。将栈顶元素作为次顶元素指定方法的输入参数。
比如:digester.addSetNext("database/user","addUser"),调用database实例的addUser,user为参数
2、创建企业命名上下文

3、为Server添加生命周期
4、构造Service实例

5、为Service添加生命周期

6、Service中添加Executor

7、为Service添加Connector

addRule(String rule, Rule ruler):当解析到rule节点时,使用ruler规则处理器进行处理
然后接下来就是为Connector添加虚拟主机SSL配置、Connector添加生命周期监听器、Connector添加升级协议、Connector添加子元素解析规则
接着后面就是Engine、Host、Context的解析,请关注后续博文~~~~~