spring data项目是spring解决数据访问问题的一系列解决方案,包含了大量关系型数据库以及非关系型数据库的访问解决方案。
spring data jpa
1、简介
jpa是一套规范,不提供实现,由不同的软件提供商自行实现各自的功能。这样做的好处就是使用者只需要按照规范中定义的操作方式来使用,不需要具体软件厂商的实现方式。
在soring data jpa中,建立访问层非常简单,如下:

不过这种方式只能操作于单表以及一些最基本的crud。
在使用spring data jpa之前,项目中必须配置了数据源datasource或者连接池之类的(druid连接池)。
2、使用方法
spring data jpa默认提供了findAll、save等方法,并且可以使用findByName的类似方式来操作数据库,不过总的来说,我个人觉得spring data jpa提供的这套方案有点鸡肋。首先写方法的时候会增加难度,其次企业级应用的业务逻辑也很复杂。
a、findByName等等方式
根据字段name到数据库中查询,这块可以自行百度
b、@Query
这种方式有点类似于mybatis提供的方案,sql由开发自己完成
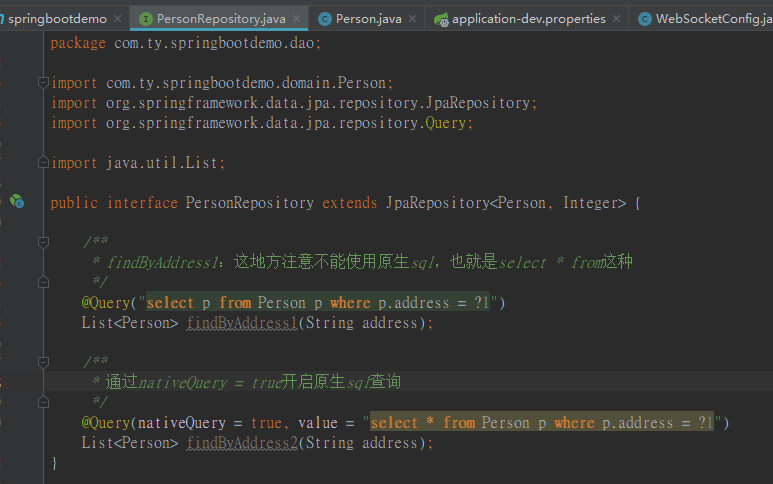
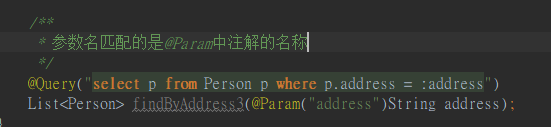
这种是使用参数索引的方式来查询,也可以基于参数名称查询,如下:
也可以搭配其他注解用于更新,如下:
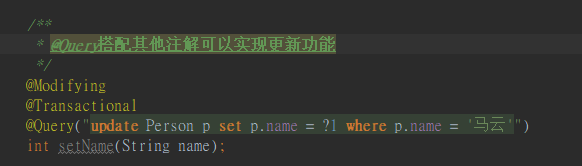
注意,此@Transactional是org.springframework.transaction.annotation.Transactional,而不是javax.transaction.
非关系型数据库nosql
nosql是对于不使用关系作为数据管理的数据库系统的统称,nosql特点:不使用sql语言作为查询语言、数据存储也不是固定的表与字段。目前主要有以下几类:
---------文档存储型(MongoDB)
|
nosql------------>---------图形关系存储型(Neo4j)
|
---------键值对存储(Redis)
1、MongoDB
springboot中集成mongodb参考博客:https://blog.csdn.net/stronglyh/article/details/81024588
2、Redis
springboot中集成redis参考博客:https://www.cnblogs.com/gdpuzxs/p/7222309.html
与mybatis整合
本人还是比较喜欢mybatis,可能用起来比较顺手。
1、引入依赖
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.1.1</version> </dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.21</version>
</dependency>
2、配置数据源----->springboot默认数据库连接池为HikariCP
spring.datasource.url=jdbc:mysql://localhost:3306/test spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver
3、使用mybatis
public class User { private Long id; private String name; private Integer age; // 省略getter和setter }
@Mapper public interface UserMapper {
//根据string查询 @Select("SELECT * FROM USER WHERE NAME = #{name}") User findByName(@Param("name") String name); //插入两个参数 @Insert("INSERT INTO USER(NAME, AGE) VALUES(#{name}, #{age})") int insert(@Param("name") String name, @Param("age") Integer age);
//插入map
@Insert("INSERT INTO USER(NAME, AGE) VALUES(#{name,jdbcType=VARCHAR}, #{age,jdbcType=INTEGER})")
int insertByMap(Map<String, Object> map);
//插入对象
@Insert("INSERT INTO USER(NAME, AGE) VALUES(#{name}, #{age})")
int insertByUser(User user);
@Update("UPDATE user SET age=#{age} WHERE name=#{name}")
void update(User user);
@Delete("DELETE FROM user WHERE id =#{id}")
void delete(Long id);
}
测试案例:
@RunWith(SpringJUnit4ClassRunner.class) @SpringApplicationConfiguration(classes = Application.class) public class ApplicationTests { @Autowired private UserMapper userMapper; @Test @Rollback public void findByName() throws Exception { userMapper.insert("AAA", 20); User u = userMapper.findByName("AAA"); Assert.assertEquals(20, u.getAge().intValue()); } }
如果dto中的属性与数据库字段不对应时,可使用如下方式:
@Results({ //property对应user对象中的字段,column则是数据库中对应的字段 @Result(property = "name", column = "name"), @Result(property = "age", column = "age") }) @Select("SELECT name, age FROM user") List<User> findAll();
事务
1、简介
所有数据访问技术都有事务处理机制,一般都是提供api来打开事务、提交事务以及回滚事务等操作。spring的事务机制是用统一的机制来处理不同数据访问技术的事务处理,提供了一个PlatformTransactionManager的接口。不同数据访问技术
则对应不同的实现类,如下:
JDBC------------------------------->DataSourceTrasactionManager
JPA---------------------------------->JpaTransactionManager
Hibernate-------------------------->HibernateTransactionManager
JDO--------------------------------->JdoTransactionManager
分布式事务------------------------>JtaTransactionManager
2、声明式事务
声明式事务,就是使用注解来表明该方法上是需要事务支持的。在spring中提供了@EnableTransactionManagement来开启事务,我们之前都是使用xml配置事务,等同于xml配置方式的 <tx:annotation-driven />。
3、注解事务行为
参考文章:https://blog.csdn.net/mawming/article/details/52277431
@Transaction不仅可以用于方法上,也可以使用在类上,使用在类上说明此类中的所有public方法都将开启事务,并且方法上的事务注解优先级高于类事务注解。
4、springboot的事务支持
在SpringBoot中,当我们使用了spring-boot-starter-jdbc或spring-boot-starter-data-jpa依赖的时候,框架会自动默认分别注入DataSourceTransactionManager或JpaTransactionManager。所以我们不需要任何额外配置就可以用@Transactional注解进行事务的使用。
事务隔离级别
隔离级别是指若干个并发的事务之间的隔离程度,与我们开发时候主要相关的场景包括:脏读取、重复读、幻读。
我们可以看 org.springframework.transaction.annotation.Isolation 枚举类中定义了五个表示隔离级别的值:
public enum Isolation { //这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是:READ_COMMITTED。不过mysql的默认隔离级别为REPEATABLE_READ DEFAULT(-1), //该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。 READ_UNCOMMITTED(1), //该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。 READ_COMMITTED(2), //该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。 REPEATABLE_READ(4), //所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。 SERIALIZABLE(8); }
指定方式如下:
@Transactional(isolation = Isolation.DEFAULT)
事务传播行为
所谓事务的传播行为是指,如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。
我们可以看 org.springframework.transaction.annotation.Propagation 枚举类中定义了6个表示传播行为的枚举值:
public enum Propagation { //如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。 REQUIRED(0), //如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 SUPPORTS(1), //如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。 MANDATORY(2), //创建一个新的事务,如果当前存在事务,则把当前事务挂起。 REQUIRES_NEW(3), //以非事务方式运行,如果当前存在事务,则把当前事务挂起。 NOT_SUPPORTED(4), //以非事务方式运行,如果当前存在事务,则抛出异常。 NEVER(5), //如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于REQUIRED。 NESTED(6); }
指定方式:
@Transactional(propagation = Propagation.REQUIRED)
springboot定时任务
在介绍springboot中定时任务之前,先来回顾下如何在spring中使用定时任务。
1、在spring配置文件application.xml中引入命名空间
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/task/spring-task-3.0.xsd"
2、开启任务配置
<!-- 启动定时器 --> <task:annotation-driven/>
3、java类
@Scheduled(fixedDelay = 3000) //每隔3秒钟执行一次任务 public void start() throws ServletException { validate(); }
4、@Scheduled参数解释
- @Scheduled(fixedRate = 5000) :上一次开始执行时间点之后5秒再执行
- @Scheduled(fixedDelay = 5000) :上一次执行完毕时间点之后5秒再执行
- @Scheduled(initialDelay=1000, fixedRate=5000) :第⼀次延迟1秒后执行,之后按fixedRate的规则每5秒执行一次
- @Scheduled(cron="*/5 * * * * *") :通过cron表达式定义规则
ok这样springboot中使用定时任务就非常简单了,只要在运行主类中使用@EnableScheduling:
@SpringBootApplication @EnableScheduling public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
然后在类中就可以直接使用@Scheduled注解了。