1.提交任务得方式:
同步:提交完任务,等结果,执行下一个任务
异步:提交完,接着执行,异步 + 回调 异步不等结果,提交完任务,任务执行完后,会自动触发回调函数
2.同步不等于阻塞:
阻塞:遇到io,自己不处理,os会抢走cpu ,解决办法:监测到io,gevent切换到其他任务,类似欺骗os
非阻塞:cpu 运行
3.IO分类:
1.阻塞IO blocking IO
2.非阻塞IO nonblocking IO
3.IO多路复用 IO multiplexing
4.信号驱动IO signal driven IO 用得比较少
5.异步IO asynchronous IO
4.network io
涉及到两个系统对象:
1.调用这个io的进程(process/thread)
2.系统内核(kernel)
操作涉及到两个阶段:
1.等待数据准备
2.将数据从内核拷贝到进程中
5.阻塞io:
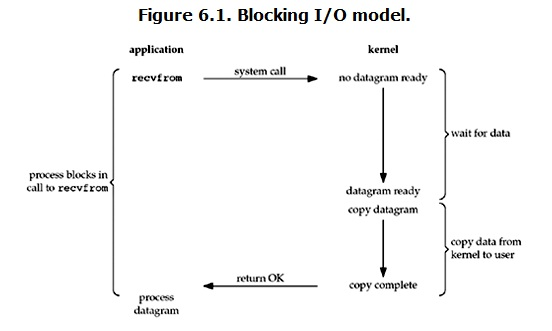
blocking IO的特点:
在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了.
socket编程:
几乎所有的IO接口 ( 包括socket接口 ) 都是阻塞型的.
解决方案:
多线程/线程池,可以解决小规模的服务请求;面对大规模的服务请求,多线程模型也会遇到瓶颈,用非阻塞接口来解决.


1 from socket import * 2 from threading import Thread 3 4 def communicate(conn): 5 while True: 6 try: 7 data = conn.recv(1024) 8 if not data: break 9 conn.send(data.upper()) 10 except ConnectionResetError: 11 break 12 13 conn.close() 14 15 server = socket(AF_INET, SOCK_STREAM) 16 server.bind(('127.0.0.1',8080)) 17 server.listen(5) 18 19 while True: 20 print('starting...') 21 conn, addr = server.accept() # io 阻塞 os拿走了cpu 22 print(addr) 23 24 t=Thread(target=communicate,args=(conn,)) 25 t.start() 26 27 server.close()
1 # -*- coding:utf-8 -*- 2 3 from socket import * 4 5 client=socket(AF_INET,SOCK_STREAM) 6 client.connect(('127.0.0.1',8080)) 7 8 9 while True: 10 msg=input('>>: ').strip() 11 if not msg:continue 12 client.send(msg.encode('utf-8')) 13 data=client.recv(1024) 14 print(data.decode('utf-8')) 15 16 client.close()
6.非阻塞io:
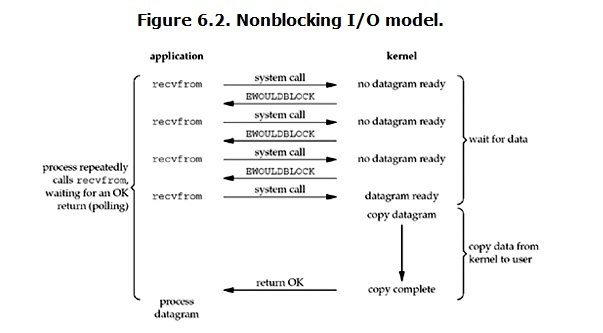
说明:
非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,
此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,
循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,
进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
结果:在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有.
缺点:
非阻塞IO模型绝不被推荐
1.循环调用recv()将大幅度推高CPU占用率;这也是我们在代码中留一句time.sleep(2)的原因,否则在低配主机下极容易出现卡机情况
2.任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。
这会导致整体数据吞吐量的降低。
解决:
在这个方案中recv()更多的是起到检测“操作是否完成”的作用,实际操作系统提供了更为高效的检测“操作是否完成“作用的接口,
例如select()多路复用模式,可以一次检测多个连接是否活跃。
1 # -*- coding:utf-8 -*- 2 import socket 3 4 server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 5 server.bind(('127.0.0.1',8080)) 6 server.listen(5) 7 server.setblocking(False) 8 9 rlist = [] 10 wlist = [] 11 while True: 12 try: 13 conn,addr = server.accept() 14 rlist.append(conn) 15 print(rlist) 16 except BlockingIOError: 17 del_rlist = [] 18 for sock in rlist: 19 try: 20 data = sock.recv(1024) 21 if not data: 22 sock.close() 23 del_rlist.append(sock) 24 wlist.append((sock,data.upper())) 25 except BlockingIOError: 26 continue 27 except Exception: 28 sock.close() 29 del_rlist.append(sock) 30 31 del_wlist = [] 32 for item in wlist: 33 try: 34 sock = item[0] 35 data = item[1] 36 sock.send(data) 37 del_wlist.append(item) 38 except BlockingIOError: 39 pass 40 41 for item in del_wlist: 42 wlist.remove(item) 43 for sock in del_rlist: 44 rlist.remove(sock) 45 46 server.close()
1 # -*- coding:utf-8 -*- 2 import socket 3 c = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 c.connect(('127.0.0.1',8080)) 5 while True: 6 msg = input('>>>:').strip() 7 if not msg:continue 8 c.send(msg.encode('utf-8')) 9 data = c.recv(1024) 10 print(data.decode('utf-8'))
7.多路复用IO:(事件驱动IO) (event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。
它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程
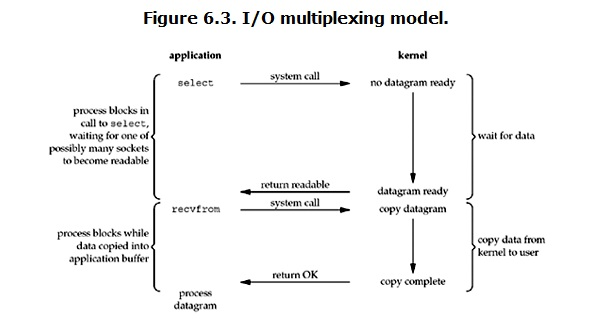
强调:
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。
select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。
只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,不适用于单个连接
分析:
用户进程创建socket对象,拷贝监听的fd到内核空间,每一个fd会对应一张系统文件表,内核空间的fd响应到数据后,
就会发送信号给用户进程数据已到;
用户进程再发送系统调用,比如(accept)将内核空间的数据copy到用户空间,同时作为接受数据端内核空间的数据清除,
这样重新监听时fd再有新的数据又可以响应到了(发送端因为基于TCP协议所以需要收到应答后才会清除)。
优点:
相比其他模型,使用select() 的事件驱动模型只用单线程(进程)执行,占用资源少,不消耗太多 CPU,同时能够为多客户端提供服务。
如果试图建立一个简单的事件驱动的服务器程序,这个模型有一定的参考价值。
缺点:
首先select()接口并不是实现“事件驱动”的最好选择。因为当需要探测的句柄值较大时,select()接口本身需要消耗大量时间去轮询各个句柄。
很多操作系统提供了更为高效的接口,如linux提供了epoll,BSD提供了kqueue,Solaris提供了/dev/poll,…。
如果需要实现更高效的服务器程序,类似epoll这样的接口更被推荐。遗憾的是不同的操作系统特供的epoll接口有很大差异,
所以使用类似于epoll的接口实现具有较好跨平台能力的服务器会比较困难。
其次,该模型将事件探测和事件响应夹杂在一起,一旦事件响应的执行体庞大,则对整个模型是灾难性的。
总结:
select 列表循环,效率低
poll 可接收得列表数据多,效率也不高
epoll 效率最高得 异步操作+回调函数
windows 不支持
linux 支持
selectors 模块 自动根据操作系统选择
了解:select poll epoll
io复用:一个进程可以同时对多个客户请求进行服务.
io复用的“介质”是进程(准确的说复用的是select和poll,因为进程也是靠调用select和poll来实现的)
io复用中的三个API:select、poll和epoll
但select,poll,epoll本质上都是同步I/O
异步I/O的实现会负责把数据从内核拷贝到用户空间
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用 epoll_wait
不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在 epoll_wait中
进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的 时候只要判断一下就绪链表
是否为空就行了,这节省了大量的CPU时间,这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要 一次拷贝,
而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内
部定义的等待队列),这也能节省不少的开销。
详解:select poll epoll:
IO复用:为了解释这个名词,首先来理解下复用这个概念,复用也就是共用的意思,这样理解还是有些抽象,
为此,咱们来理解下复用在通信领域的使用,在通信领域中为了充分利用网络连接的物理介质,
往往在同一条网络链路上采用时分复用或频分复用的技术使其在同一链路上传输多路信号,到这里我们就基本上理解了复用的含义,
即公用某个“介质”来尽可能多的做同一类(性质)的事,那IO复用的“介质”是什么呢?为此我们首先来看看服务器编程的模型,
客户端发来的请求服务端会产生一个进程来对其进行服务,每当来一个客户请求就产生一个进程来服务,然而进程不可能无限制的产生,
因此为了解决大量客户端访问的问题,引入了IO复用技术,即:一个进程可以同时对多个客户请求进行服务。
也就是说IO复用的“介质”是进程(准确的说复用的是select和poll,因为进程也是靠调用select和poll来实现的),
复用一个进程(select和poll)来对多个IO进行服务,虽然客户端发来的IO是并发的但是IO所需的读写数据多数情况下是没有准备好的,
因此就可以利用一个函数(select和poll)来监听IO所需的这些数据的状态,一旦IO有数据可以进行读写了,进程就来对这样的IO进行服务。
理解完IO复用后,我们在来看下实现IO复用中的三个API(select、poll和epoll)的区别和联系
select,poll,epoll都是IO多路复用的机制,I/O多路复用就是通过一种机制,可以监视多个描述符,一旦某个描述符就绪(
一般是读就绪或者写就绪),能够通知应用程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,
因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,
异步I/O的实现会负责把数据从内核拷贝到用户空间。三者的原型如下所示:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
1.select的第一个参数nfds为fdset集合中最大描述符值加1,fdset是一个位数组,其大小限制为__FD_SETSIZE(1024),
位数组的每一位代表其对应的描述符是否需要被检查。第二三四参数表示需要关注读、写、错误事件的文件描述符位数组,
这些参数既是输入参数也是输出参数,可能会被内核修改用于标示哪些描述符上发生了关注的事件,
所以每次调用select前都需要重新初始化fdset。timeout参数为超时时间,该结构会被内核修改,其值为超时剩余的时间。
select的调用步骤如下:
(1)使用copy_from_user从用户空间拷贝fdset到内核空间
(2)注册回调函数__pollwait
(3)遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll
或者datagram_poll)
(4)以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
(5)__pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll 来说,
其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数据
(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。
(6)poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
(7)如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是 current)
进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout 指定),
还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
(8)把fd_set从内核空间拷贝到用户空间。
总结下select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
2. poll与select不同,通过一个pollfd数组向内核传递需要关注的事件,故没有描述符个数的限制,pollfd中的events字段和revents分别
用于标示关注的事件和发生的事件,故pollfd数组只需要被初始化一次。
poll的实现机制与select类似,其对应内核中的sys_poll,只不过poll向内核传递pollfd数组,然后对pollfd中的每个描述符进行poll,
相比处理fdset来说,poll效率更高。poll返回后,需要对pollfd中的每个元素检查其revents值,来得指事件是否发生。
3.直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,
那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,
而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,
这样便彻底省掉了这些文件描述符在系统调用时复制的开销。另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,
进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,
一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll 和select和
poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函 数,
epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注 册要监听的事件类型;
epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定 EPOLL_CTL_ADD),
会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝 一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在 epoll_ctl时把
current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调 函数,
而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd
(利用 schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,
在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用 epoll_wait
不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在 epoll_wait中
进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的 时候只要判断一下就绪链表
是否为空就行了,这节省了大量的CPU时间,这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要 一次拷贝,
而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内
部定义的等待队列),这也能节省不少的开销。
1 # -*- coding:utf-8 -*- 2 import socket 3 import select 4 5 server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 6 server.bind(('127.0.0.1',8080)) 7 server.listen(5) 8 server.setblocking(False) 9 print('start...') 10 11 rlist = [server,] 12 wlist = [] 13 wdata = {} 14 15 while True: 16 rl,wl,xl = select.select(rlist,wlist,[],0.5) 17 print(wl) 18 for sock in rl: 19 if sock == server: 20 conn,addr = sock.accept() 21 rlist.append(conn) 22 else: 23 try: 24 data = sock.recv(1024) 25 if not data: 26 sock.close() 27 rlist.remove(sock) 28 wlist.append(sock) 29 wdata[sock]=data.upper() 30 except Exception: 31 sock.close() 32 rlist.remove(sock) 33 for sock in wl: 34 sock.send(wdata[sock]) 35 wlist.remove(sock) 36 wdata.pop(sock)
1 # -*- coding:utf-8 -*- 2 import socket 3 client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 client.connect(('127.0.0.1',8080)) 5 while True: 6 msg = input(">>>:").strip() 7 if not msg:continue 8 client.send(msg.encode('utf-8')) 9 data = client.recv(1024) 10 print(data.decode('utf-8'))
selectors 模块
1 # -*- coding:utf-8 -*- 2 from socket import * 3 import selectors 4 5 sel=selectors.DefaultSelector() 6 def accept(server_fileobj,mask): 7 conn,addr=server_fileobj.accept() 8 sel.register(conn,selectors.EVENT_READ,read) 9 10 def read(conn,mask): 11 try: 12 data=conn.recv(1024) 13 if not data: 14 print('closing',conn) 15 sel.unregister(conn) 16 conn.close() 17 return 18 conn.send(data.upper()+b'_SB') 19 except Exception: 20 print('closing', conn) 21 sel.unregister(conn) 22 conn.close() 23 24 server_fileobj=socket(AF_INET,SOCK_STREAM) 25 server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) 26 server_fileobj.bind(('127.0.0.1',8080)) 27 server_fileobj.listen(5) 28 server_fileobj.setblocking(False) #设置socket的接口为非阻塞 29 sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄 30 #server_fileobj,并且绑定了一个回调函数accept 31 32 while True: 33 events=sel.select() #检测所有的fileobj,是否有完成wait data的 34 for sel_obj,mask in events: 35 callback=sel_obj.data #callback=accpet 36 callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1)
1 # -*- coding:utf-8 -*- 2 import socket 3 client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 client.connect(('127.0.0.1',8080)) 5 while True: 6 msg = input(">>>:").strip() 7 if not msg:continue 8 client.send(msg.encode('utf-8')) 9 data = client.recv(1024) 10 print(data.decode('utf-8'))
8.异步IO: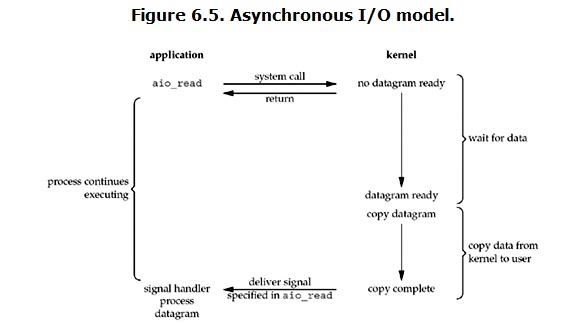
说明:
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,
首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,
当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
讲网络爬虫时会用到:异步io
9.阻塞IO,非阻塞IO,同步IO,异步IO区别:

blocking io: 会一直block住对应得进程直到操作完成
non-blockingo: 在kernel还准备数据得情况下会立刻返回
synchronous io: 做”IO operation”的时候会将process阻塞;”IO operation”是指真实的IO操作
blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO这一类.
asynchronous io: 当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,
告诉进程说IO完成。在这整个过程中,进程完全没有被block。异步io的实现会负责把数据从内核拷贝到用户空间。
总结:
non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,
但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。
而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。
在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
10.socketserver 模块:
socketserver内部使用IO多路复用以及“多线程”和“多进程”,从而实现并发处理多个客户端请求的socket服务端
ThreadingTCPServer的使用方法:
1、创建一个继承socketserver.BaseRequestHandler的类
2、类中必须重写一个名为handler的方法
3、实例化一个服务器类,传入服务器的地址和请求处理程序类
4、调用serve_forever()事件循环监听
1 import socketserver 2 3 class Handler(socketserver.BaseRequestHandler): # 必须继承BaseRequestHandler 4 def handle(self): # 必须有handle方法 5 print('new connection:',self.client_address) 6 while True: 7 try: 8 data = self.request.recv(1024) 9 if not data:break 10 print('client data:',data.decode()) 11 self.request.send(data.upper()) 12 except Exception as e: 13 print(e) 14 break 15 16 if __name__ == "__main__": 17 server = socketserver.ThreadingTCPServer(('127.0.0.1',8080),Handler) # 实例化对象,实现多线程的socket 18 server.serve_forever() # 事件监听,并调用handler方法
1 # -*- coding:utf-8 -*- 2 import socket 3 client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 client.connect(('127.0.0.1',8080)) 5 while True: 6 msg = input(">>>:").strip() 7 if not msg:continue 8 client.send(msg.encode('utf-8')) 9 data = client.recv(1024) 10 print(data.decode('utf-8'))