写一个简单的员工信息增删改查程序,需求如下:
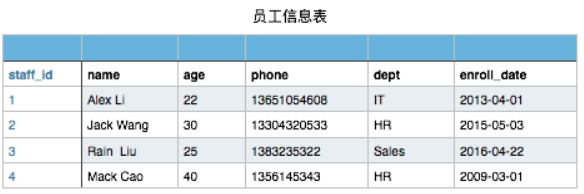
当然此表你在文件存储时可以这样表示
1,Alex Li,22,13651054608,IT,2013-04-01 2,Jack Wang,28,13451024608,HR,2015-01-07 3,Rain Wang,21,13451054608,IT,2017-04-01 4,Mack Qiao,44,15653354208,Sales,2016-02-01 5,Rachel Chen,23,13351024606,IT,2013-03-16 6,Eric Liu,19,18531054602,Marketing,2012-12-01 7,Chao Zhang,21,13235324334,Administration,2011-08-08 8,Kevin Chen,22,13151054603,Sales,2013-04-01 9,Shit Wen,20,13351024602,IT,2017-07-03 10,Shanshan Du,26,13698424612,Operation,2017-07-02
1.可进行模糊查询,语法至少支持下面3种查询语法:
find name,age from staff_table where age > 22 find * from staff_table where dept = "IT" find * from staff_table where enroll_date like "2013"
2.可创建新员工纪录,以phone做唯一键(即不允许表里有手机号重复的情况),staff_id需自增
语法: add staff_table Alex Li,25,134435344,IT,2015-10-29
3.可删除指定员工信息纪录,输入员工id,即可删除
语法: del from staff_table where id=3
4.可修改员工信息,语法如下:
UPDATE staff_table SET dept="Market" WHERE dept = "IT" 把所有dept=IT的纪录的dept改成Market UPDATE staff_table SET age=25 WHERE name = "Alex Li" 把name=Alex Li的纪录的年龄改成25
5.以上每条语名执行完毕后,要显示这条语句影响了多少条纪录。 比如查询语句 就显示 查询出了多少条、修改语句就显示修改了多少条等。
----------------------------------------------------------------
----------------------------------------------------------------
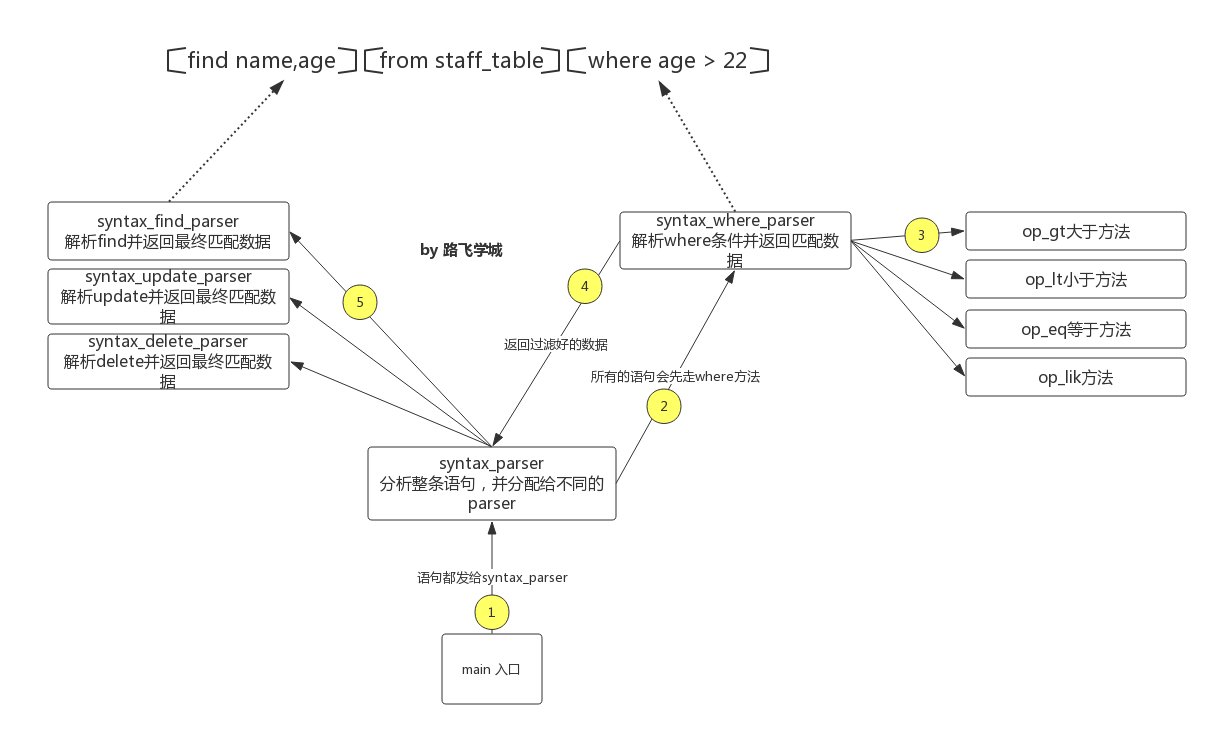
标准答案:


1 # _*_coding:utf-8_*_ 2 # created by Alex Li on 10/15/17 3 from tabulate import tabulate 4 import os 5 6 STAFF_DB = "staff.db" #因为不会变,所以是常量 7 COLUMN_ORDERS = ['id','name','age','phone','dept','enrolled_date'] 8 9 10 11 def load_db(): 12 """ 13 打开db文件,把文件里的数据的每列转换成一个列表 14 1,Alex Li,22,13651054608,IT,2013-04-01 15 16 :return: 17 """ 18 staff_data = { #把文件里的每列添加到下面这些列表里 19 'id':[], 20 'name':[], 21 'age':[], 22 'phone':[], 23 'dept':[], 24 'enrolled_date':[] 25 } 26 27 28 f = open(STAFF_DB,"r",encoding="utf-8") 29 30 for line in f: 31 staff_id,name,age,phone,dept,enrolled_date = line.strip().split(',') 32 staff_data['id'].append(staff_id) 33 staff_data['name'].append(name) 34 staff_data['age'].append(age) 35 staff_data['phone'].append(phone) 36 staff_data['dept'].append(dept) 37 staff_data['enrolled_date'].append(enrolled_date) 38 39 #print(staff_data) 40 f.close() 41 return staff_data 42 43 44 def save_db(): 45 """sync data back to db each time after editing""" 46 f = open("%s_tmp"%STAFF_DB, "w", encoding="utf-8") 47 48 for index,val in enumerate(STAFF_DATA[COLUMN_ORDERS[0]]): 49 row = [str(val)] 50 for col in COLUMN_ORDERS[1:]: 51 row.append(str(STAFF_DATA[col][index]) ) 52 53 raw_row = ",".join(row) 54 f.write(raw_row+" ") 55 f.close() 56 os.rename("%s_tmp"%STAFF_DB,STAFF_DB) 57 58 59 def print_log(msg,msg_type='info'): 60 if msg_type == 'error': 61 print("�33[31;1mError:%s�33[0m"%msg) 62 else: 63 print("�33[32;1mInfo:%s�33[0m"%msg) 64 65 66 def syntax_find(query_clause, matched_data): 67 """ 68 69 :param query_clause: eg. find age,name from staff_table 70 :param matched_data: where方法匹配到的数据 71 :return: 72 """ 73 74 filter_keys = query_clause.split('find')[1].split('from')[0] 75 columns = [i.strip() for i in filter_keys.split(',')] #要过滤出来的字段 76 if "*" in columns: 77 if len(columns) == 1: #只有find * from ...成立,*不能与其它字段同时出现 78 columns = COLUMN_ORDERS 79 else: 80 print_log("*不能同时与其它字段出现","error") 81 return False 82 if len(columns) == 1: 83 if not columns[0]: 84 print_log("语法错误,find和from之间必须跟字段名或*","error") 85 return False 86 filtered_data = [] 87 for index,val in enumerate(matched_data[columns[0]]): #拿要查找的多列的第一个元素,[name,age,dept],拿到name,到数据库匹配,然后按这一列的每个值 的索引到其它列表里依次找 88 row = [val,] 89 #if columns[1:]: #代表是多列过滤 90 for col in columns[1:]: 91 row.append(matched_data[col][index]) 92 #print("row",row) 93 filtered_data.append(row) 94 95 print(tabulate(filtered_data,headers=columns,tablefmt="grid")) 96 print_log("匹配到%s条纪录"%len(filtered_data)) 97 98 99 def syntax_add(query_clause, matched_data): 100 """ 101 sample: add staff Alex Li,25,134435344,IT,2015-10-29 102 :param query_clause: add staff Alex Li,25,134435344,IT,2015-10-29 103 :param matched_data: 104 :return: 105 """ 106 column_vals = [ col.strip() for col in query_clause.split("values")[1].split(',')] 107 #print('cols',column_vals) 108 if len(column_vals) == len(COLUMN_ORDERS[1:]): #不包含id,id是自增 109 110 #find max id first , and then plus one , becomes the id of this new record 111 init_staff_id = 0 112 for i in STAFF_DATA['id']: 113 if int(i) > init_staff_id: 114 init_staff_id = int(i) 115 116 init_staff_id += 1 #当前最大id再+1 117 STAFF_DATA['id'].append(init_staff_id) 118 for index,col in enumerate(COLUMN_ORDERS[1:]): 119 STAFF_DATA[col].append( column_vals[index] ) 120 121 else: 122 print_log("提供的字段数据不足,必须字段%s"%COLUMN_ORDERS[1:],'error') 123 124 print(tabulate(STAFF_DATA,headers=COLUMN_ORDERS)) 125 save_db() 126 print_log("成功添加1条纪录到staff_table表") 127 128 129 def syntax_update(query_clause, matched_data): 130 pass 131 132 133 def syntax_delete(query_clause, matched_data): 134 pass 135 136 def op_gt(q_name,q_condtion): 137 """ 138 find records q_name great than q_condtion 139 :param q_name: 查找条件key 140 :param q_condtion: 查找条件value 141 :return: 142 """ 143 matched_data = {} #把符合条件的数据都放这 144 for k in STAFF_DATA: 145 matched_data[k] = [] 146 147 q_condtion = float(q_condtion) 148 for index,i in enumerate(STAFF_DATA[q_name]): 149 if float(i) > q_condtion : 150 for k in matched_data: 151 matched_data[k].append( STAFF_DATA[k][index] ) #把匹配的数据都 添加到matched_data里 152 153 #print("matched:",matched_data) 154 155 return matched_data 156 157 def op_lt(): 158 """ 159 less than 160 :return: 161 """ 162 163 def op_eq(): 164 """ 165 equal 166 :return: 167 """ 168 169 def op_like(q_name,q_condtion): 170 """ 171 find records where q_name like q_condition 172 :param q_name: 查找条件key 173 :param q_condtion: 查找条件value 174 :return: 175 """ 176 matched_data = {} #把符合条件的数据都放这 177 for k in STAFF_DATA: 178 matched_data[k] = [] 179 180 for index,i in enumerate(STAFF_DATA[q_name]): 181 if q_condtion in i : 182 for k in matched_data: 183 matched_data[k].append( STAFF_DATA[k][index] ) #把匹配的数据都 添加到matched_data里 184 185 #print("matched:",matched_data) 186 187 return matched_data 188 189 def syntax_where(clause): 190 """ 191 解析where条件,并查询数据 192 :param clause: where条件 , eg. name=alex 193 :return: False or matched data dict 194 """ 195 196 query_data = {} #存储查询出来的结果 197 operators = {'>':op_gt, 198 '<':op_lt, 199 '=':op_eq, 200 'like':op_like} 201 query_condtion_matched = False #如果匹配语句都没匹配上 202 for op_key,op_func in operators.items(): 203 if op_key in clause: 204 q_name,q_condition = clause.split(op_key) 205 #print("query:",q_name,q_condition) 206 if q_name.strip() in STAFF_DATA: 207 matched_data = op_func(q_name.strip(),q_condition.strip()) #调用对应的方法 208 return matched_data 209 else: 210 print_log("字段'%s' 不存在!"%q_name,'error') 211 return False 212 213 if not query_condtion_matched: 214 print("�33[31;1mError:语句条件%s不支持�33[0m"%clause) 215 return False 216 217 218 219 220 221 222 223 def syntax_parser(cmd): 224 """ 225 解析语句 226 :return: 227 """ 228 syntax_list = { 229 'find':syntax_find, 230 'add':syntax_add, 231 'update':syntax_update, 232 'delete':syntax_delete, 233 } 234 if cmd.split()[0] in ['find','add','update','delete'] and "staff_table" in cmd : 235 236 if 'where' in cmd: 237 query_cmd,where_clause = cmd.split("where") 238 239 matched_data = syntax_where(where_clause.strip()) 240 if matched_data: #有匹配结果 241 action_name = cmd.split()[0] 242 syntax_list[action_name](query_cmd,matched_data) #调用对应的action方法 243 else: 244 syntax_list[cmd.split()[0]](cmd, STAFF_DATA) #没where,使用所有数据 245 246 247 else: 248 print_log('''语法错误! sample:[find/add/update/delete] name,age from [staff_table] where [id][>/</=/like][2]''','error') 249 250 251 def main(): 252 """ 253 程序主入口 254 :return: 255 """ 256 257 while True: 258 cmd = input("[staff db]:").strip() 259 if not cmd:continue 260 261 syntax_parser(cmd) 262 263 264 265 STAFF_DATA = load_db() 266 267 main()
我的答案:
1 # -*- coding:utf-8 -*- 2 import os 3 4 staff_db = 'staff_table.txt' 5 staff = 'staff_table' 6 staff_order = ['id', 'name', 'age', 'phone', 'dept', 'enroll_date'] 7 8 9 def print_search(list_data): 10 if len(list_data) != 0: 11 print('影响了�33[1;31m%s�33[0m条记录'% len(list_data)) 12 for i in list_data: 13 print(i) 14 else: 15 print("没有对应得数据!") 16 17 18 def syntax_update(con_sen,common_data): 19 # update 修改语句 20 if len(common_data) == 0: 21 print('没有记录') 22 return common_data 23 else: 24 index_num = 0 25 id_data = [] 26 new_data = [] 27 for index, i in enumerate(staff_order): 28 if i == con_sen[0].strip(): 29 index_num = index 30 break 31 for index, i in enumerate(common_data): 32 id_data.append(i.split(',')[0]) 33 f = open(staff_db, 'r+', encoding='utf-8') 34 f_new = open('staff_table_new.txt', 'w', encoding='utf-8') 35 for line in f: 36 temp_li =line.split(',') 37 if temp_li[0] in id_data: 38 if con_sen[1].strip().isdigit(): 39 temp_li[index_num] = con_sen[1].strip() 40 else: 41 temp_li[index_num] = eval(con_sen[1].strip()) 42 line = ','.join(temp_li) 43 new_data.append(line.strip()) 44 f_new.write(line) 45 f.close() 46 f_new.close() 47 48 os.replace(f_new.name, f.name) 49 return new_data 50 51 52 def syntax_add(add_data): 53 # add 语句增加 54 f = open(staff_db, 'r+', encoding='utf-8') 55 id_data, phone, new_list = [], [], [] 56 for index, line in enumerate(f): 57 id_data.append(line.split(',')[0]) 58 phone.append(line.split(',')[3]) 59 if add_data[2] in phone: 60 print('phone已存在') 61 else: 62 data = str(int(id_data[-1])+1) + ','+ ','.join(add_data) 63 new_list.append(data) 64 f.write(data+' ') 65 f.close() 66 return new_list 67 68 69 def syntax_delete(common_data): 70 # del 语句删除 71 if len(common_data) == 0: 72 print('没有该条记录'.center(20,'-')) 73 return common_data 74 else: 75 str_data = '' 76 f = open(staff_db, 'r+', encoding='utf-8') 77 for line in f: 78 if line.split(',')[0] == common_data[0].split(',')[0]: 79 continue 80 else: 81 str_data += line 82 f.seek(0) 83 f.truncate() 84 f.write(str_data) 85 f.close() 86 print('已从文件中删除'.center(20, '-')) 87 return common_data 88 89 90 def syntax_find(con_sen,common_data): 91 # find 语句查找 92 if '*' in con_sen.split('find')[1]: 93 return common_data 94 sen = con_sen.split('find')[1].split(',') 95 li = [] 96 for index, i in enumerate(staff_order): 97 for j in sen: 98 if j.strip() == i: 99 li.append(index) 100 new_data = [] 101 for i in common_data: 102 str_data = '' 103 for index, j in enumerate(i.split(',')): 104 for k in li: 105 if k == index: 106 str_data += j + ',' 107 break 108 new_data.append(str_data[:-1]) 109 return new_data 110 111 112 def syntax_where(common_data, con_sentence): 113 # 查找语句分配 114 if con_sentence == '': 115 add_data = common_data.split(',') 116 return syntax_add(add_data) 117 else: 118 if 'from' in con_sentence: 119 con_sen = con_sentence.split('from') 120 if con_sen[1].strip() == staff: 121 if 'find' in con_sen[0]: 122 return syntax_find(con_sen[0],common_data) 123 elif 'del' in con_sen[0]: 124 return syntax_delete(common_data) 125 else: 126 print('输入的语句有问题') 127 return [] 128 elif 'set' in con_sentence and 'update' in con_sentence: 129 con_sen = con_sentence.split('set') 130 if 'staff_table' in con_sen[0]: 131 return syntax_update(con_sen[1].split('='), common_data) 132 else: 133 print('输入的语句有问题') 134 return [] 135 else: 136 print('输入的语句有问题') 137 return [] 138 139 140 def common_op(where_data): 141 # > < = like 公共方法 142 list_where_data = [] 143 con_where = [] 144 index_num = 0 145 op = ['>', '<', '=', 'like'] 146 for index, i in enumerate(op): 147 if i in where_data: 148 list_where_data = where_data.split(i) 149 index_num = index 150 break 151 f = open(staff_db, 'r', encoding='utf-8') 152 for index, i in enumerate(staff_order): 153 if i == list_where_data[0].strip(): 154 for line in f: 155 data = line.strip().split(',') 156 if index_num == 0: 157 if eval(data[index].strip()) > eval(list_where_data[1].strip()): 158 con_where.append(line.strip()) 159 elif index_num == 1: 160 if eval(data[index].strip()) < eval(list_where_data[1].strip()): 161 con_where.append(line.strip()) 162 elif index_num == 2: 163 if data[index].strip().isdigit(): # 判断原有的内容是否是整数类型 164 if eval(data[index].strip()) == eval(list_where_data[1].strip()): 165 con_where.append(line.strip()) 166 else: 167 if data[index].strip().lower() == eval(list_where_data[1].strip().lower()): 168 con_where.append(line.strip()) 169 elif index_num == 3: 170 if data[index].strip().split('-')[0].strip() == eval(list_where_data[1].strip()): 171 con_where.append(line.strip()) 172 break 173 f.close() 174 return con_where 175 176 177 def syntax_parser(cmd): 178 if 'add' in cmd: 179 print_search(syntax_where(cmd.split(staff)[1], '')) 180 elif 'where' in cmd: 181 con_sentence, data = cmd.split('where') 182 print_search(syntax_where(common_op(data), con_sentence)) 183 184 185 def main(): 186 while True: 187 cmd = input('输入语句>>>:').strip().lower() 188 if not cmd: 189 continue 190 syntax_parser(cmd) 191 192 193 if __name__ == '__main__': 194 main()