20182307 2019-2020-1 《数据结构与面向对象程序设计》实验七报告
课程:《程序设计与数据结构》
班级: 1823
姓名: 陆彦杰
学号:20182307
实验教师:王志强
实验日期:2019年11月1日
必修/选修: 必修
目录
1.实验内容
- 定义一个Searching和Sorting类,并在类中实现linearSearch,SelectionSort方法,最后完成测试。
- 要求不少于10个测试用例,提交测试用例设计情况(正常,异常,边界,正序,逆序),用例数据中要包含自己学号的后四位
- 提交运行结果图。
- 重构你的代码
- 把Sorting.java Searching.java放入 cn.edu.besti.cs1823.(姓名首字母+四位学号) 包中(例如:cn.edu.besti.cs1823.G2301)
- 把测试代码放test包中
- 重新编译,运行代码,提交编译,运行的截图(IDEA,命令行两种)
- 参考http://www.cnblogs.com/maybe2030/p/4715035.html ,学习各种查找算法并在Searching中补充查找算法并测试
- 提交运行结果截图
- 补充实现课上讲过的排序方法:希尔排序,堆排序,二叉树排序等(至少3个)
- 测试实现的算法(正常,异常,边界)
- 提交运行结果截图(如果编写多个排序算法,即使其中三个排序程序有瑕疵,也可以酌情得满分)
- 编写Android程序对实现各种查找与排序算法进行测试
- 提交运行结果截图
- 推送代码到码云(选做,加分)
2. 实验过程及结果
定义Searching和Sorting类并分别测试
- 实验目的:编写并改进教材中的Searching类与Sorting类代码
- 实验思路:通过采用类似“哨兵”思想,提高线性查找效率,并设计测试各种情况下算法的运行结果
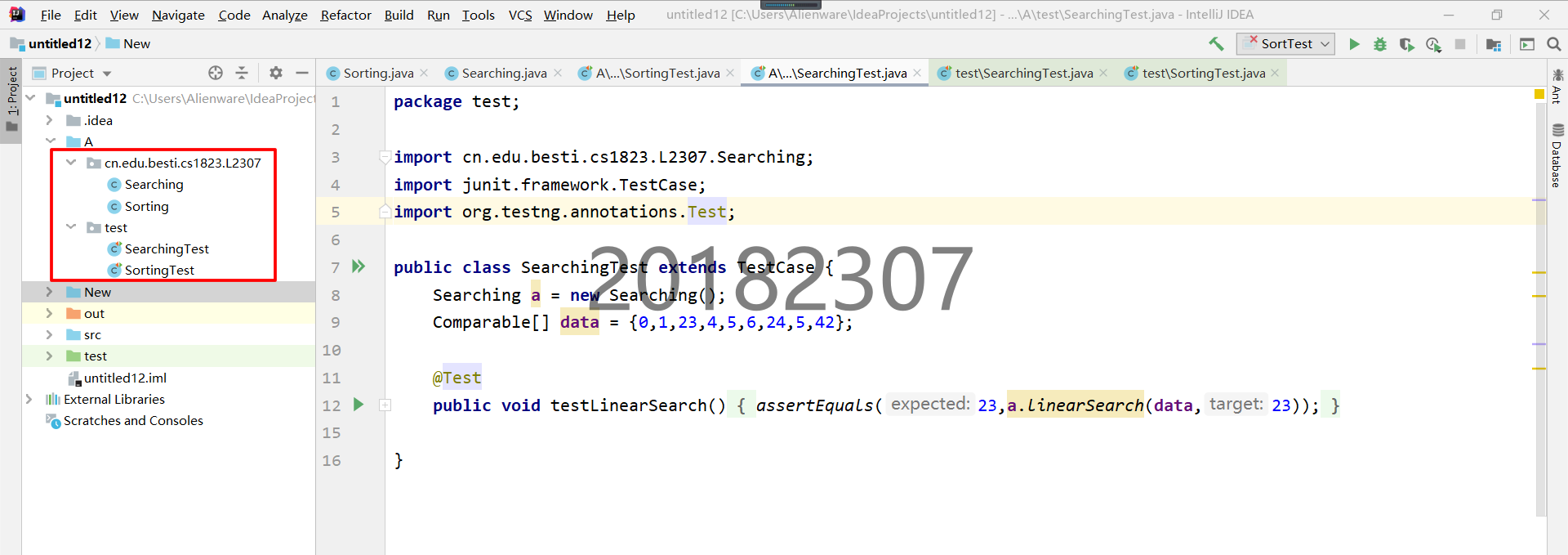
将两个程序放入不同的文件夹并用命令行运行
- 实验目的:学习移动文件目录的方法,主要学习命令行的操作
- 实验思路:改变文件目录可以在IDEA里直接鼠标操作,也可以用命令行操作。命令行编译、运行指令是之前Linux中学习的
javac *与java *命令

补全算法:斐波那契、二叉树、分块
- 实验目的:学习并实现斐波那契、二叉树、分块三种查找算法
- 实验思路:由于之前已经学习了大部分的查找算法,需要新学习的就是这三种算法。
- 斐波那契查找:二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。实现的代码如下:
public static boolean FibonacciSearch(int[] table, int keyWord) {
//确定需要的斐波那契数
int i = 0;
while (getFibonacci(i) - 1 == table.length) {
i++;
}
//开始查找
int low = 0;
int height = table.length - 1;
while (low <= height) {
int mid = low + getFibonacci(i - 1);
if (table[mid] == keyWord) {
return true;
} else if (table[mid] > keyWord) {
height = mid - 1;
i--;
} else if (table[mid] < keyWord) {
low = mid + 1;
i -= 2;
}
}
return false;
}
public static int getFibonacci(int n) {
int res = 0;
if (n == 0) {
res = 0;
} else if (n == 1) {
res = 1;
} else {
int first = 0;
int second = 1;
for (int i = 2; i <= n; i++) {
res = first + second;
first = second;
second = res;
}
}
return res;
}
- 二叉树查找:二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,然后在就行和每个节点的父节点比较大小,查找最适合的范围。算法中需要频繁用到递归思想,需要注意基本情形的设置,避免无穷递归。
- 分块查找:将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序"。要做到块与块之间有序,可以自己手动设置界限,来将元素分块。

补充实现排序方法:希尔、堆、二叉树
- 实验目的:学习并实现希尔、堆、二叉树三种排序算法
- 实验思路:
- 希尔排序:把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止
- 堆排序:堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点
- 二叉树排序:
- 希尔排序:把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止
Android实现各种排序与查找算法
3. 实验过程中遇到的问题和解决过程
-
问题1:测试添加树的节点的方法时,发现节点数与预期不符
- 原因分析:该方法是添加节点的方法,所以如果每一次都用同一个对象去调用该方法的话,节点会不断添加,而不是每次从零开始构建
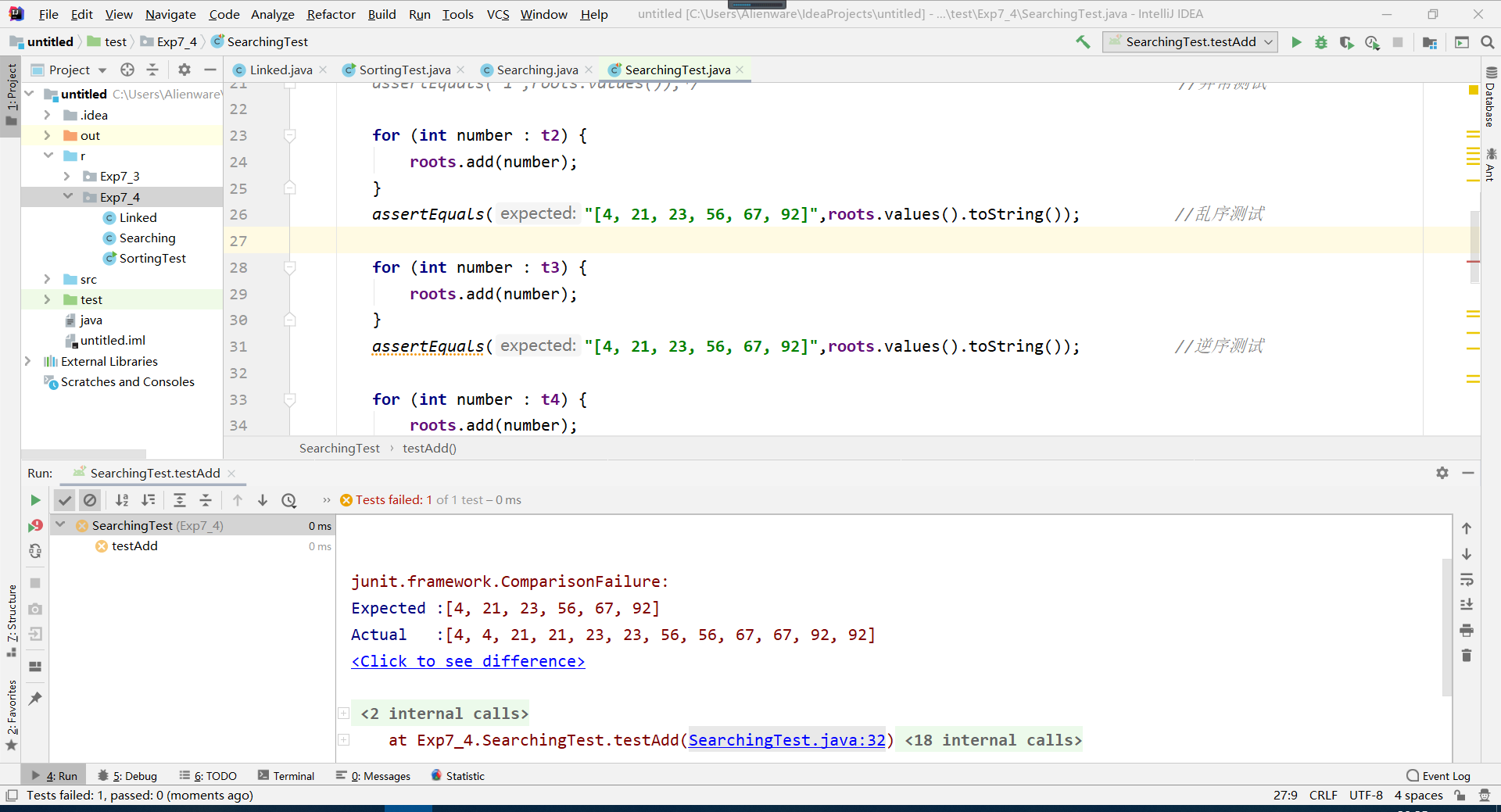
- 解决方案:实例化多个对象来调用该方法
-
问题2:使用命令行编译SearchTest主方法时,无法识别该程序中调用的Searching类
- 原因分析:命令行编译时只能编译一个程序,而主方法如果调用了其他类,此时是不能一起被编译的,所以无法执行
- 解决方案:直接在根目录下用
javac *.java编译所有文件
-
问题3:递归实现二分法查找时,递归无法结束
- 原因分析:任何递归定义必须有一个非递归部分,它决定了递归结束的时机。而我的程序中,mid这个反复传入递归中的变量的值始终没有改动,它导致了我的程序在每一次递归时都不会出现任何变化,自然形成了“无穷递归”问题。
- 解决方案:修改代码,让mid的值在递归前发生变化。

其他(感悟、思考等)
- 本次实验学习并实现了众多的排序及查找算法,其中让我感到困难的是二叉树的构建与查找。作为一种复杂的数据结构,我还需要更多的练习来熟悉掌握它,特别是左右子树的定义,与它其中普遍设计的递归思想。