字符串介绍
-
想一想:
当打来浏览器登录某些网站的时候,需要输入密码,浏览器把密码传送到服务器后,服务器会对密码进行验证,其验证过程是把之前保存的密码与本次传递过去的密码进行对比,如果相等,那么就认为密码正确,否则就认为不对;服务器既然想要存储这些密码可以用数据库(比如MySQL),当然为了简单起见,咱们可以先找个变量把密码存储起来即可;那么怎样存储带有字母的密码呢?
-
答:
字符串
<1>python中字符串的格式
如下定义的变量a,存储的是数字类型的值
a = 100
如下定义的变量b,存储的是字符串类型的值
b = "hello itcast.cn" 或者 b = 'hello itcast.cn'
小总结:
- 双引号或者单引号中的数据,就是字符串
字符串输出
demo name = 'xiaoming' position = '讲师' address = '北京市昌平区建材城西路金燕龙办公楼1层' print('--------------------------------------------------') print("姓名:%s"%name) print("职位:%s"%position) print("公司地址:%s"%address) print('--------------------------------------------------') 结果: -------------------------------------------------- 姓名: xiaoming 职位: 讲师 公司地址: 北京市昌平区建材城西路金燕龙办公楼1层 --------------------------------------------------
字符串输入
之前在学习input的时候,通过它能够完成从键盘获取数据,然后保存到指定的变量中;
注意:input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
demo: userName = input('请输入用户名:') print("用户名为:%s"%userName) password = input('请输入密码:') print("密码为:%s"%password) 结果:(根据输入的不同结果也不同) 请输入用户名:dongGe 用户名为: dongGe 请输入密码:haohaoxuexitiantianxiangshang 密码为: haohaoxuexitiantianxiangshang

下标和切片
1. 下标索引
所谓“下标”,就是编号,就好比超市中的存储柜的编号,通过这个编号就能找到相应的存储空间
-
生活中的 "下标"
超市储物柜

高铁二等座

高铁一等座

- 字符串中"下标"的使用
列表与元组支持下标索引好理解,字符串实际上就是字符的数组,所以也支持下标索引。
如果有字符串:name = 'abcdef',在内存中的实际存储如下:
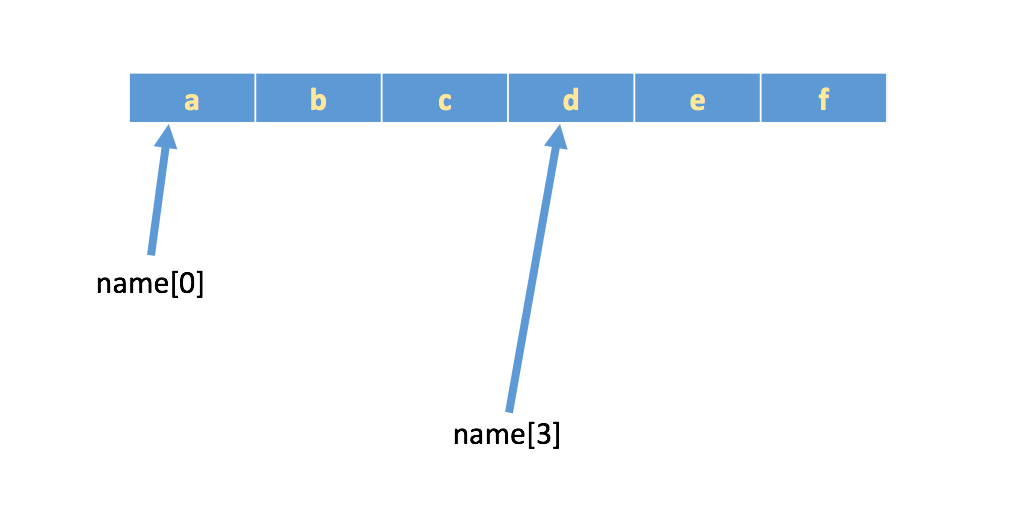
如果想取出部分字符,那么可以通过下标的方法,(注意python中下标从 0 开始)
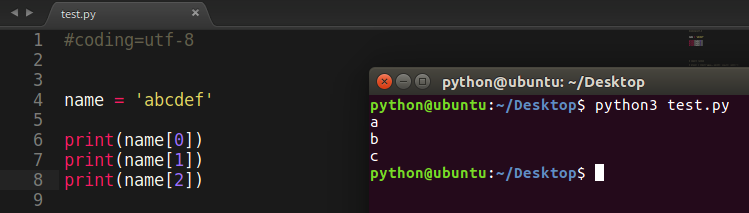
name = 'abcdef' print(name[0]) print(name[1]) print(name[2])
运行结果:
2. 切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长]
注意:选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。
我们以字符串为例讲解。
如果取出一部分,则可以在中括号[]中,使用:
name = 'abcdef' print(name[0:3]) # 取 下标0~2 的字符
运行结果:
name = 'abcdef' print(name[0:5]) # 取 下标为0~4 的字符
运行结果:

name = 'abcdef' print(name[3:5]) # 取 下标为3、4 的字符
运行结果:

name = 'abcdef' print(name[2:]) # 取 下标为2开始到最后的字符
运行结果:

>>> a = "abcdef" >>> a[:3] 'abc' >>> a[::2] 'ace' >>> a[5:1:2] '' >>> a[1:5:2] 'bd' >>> a[::-2] 'fdb' >>> a[5:1:-2] 'fd'
试做:
- 给定一个字符串aStr, 请反转字符串
字符串常见操作
如有字符串mystr = 'hello world itcast and itcastcpp',以下是常见的操作
<1>find
检测 str 是否包含在 mystr中,如果是返回开始的索引值,否则返回-1
mystr.find(str, start=0, end=len(mystr))

<2>index
跟find()方法一样,只不过如果str不在 mystr中会报一个异常.
mystr.index(str, start=0, end=len(mystr)) 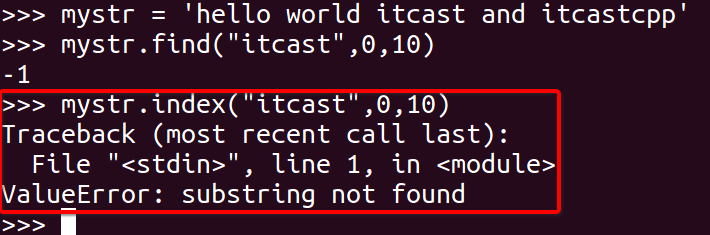
<3>count
返回 str在start和end之间 在 mystr里面出现的次数
mystr.count(str, start=0, end=len(mystr))
<4>replace
把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
mystr.replace(str1, str2, mystr.count(str1))

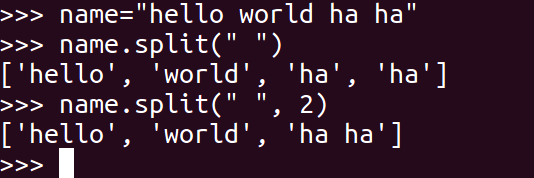
<5>split
以 str 为分隔符切片 mystr,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串
mystr.split(str=" ", 2)
<6>capitalize
把字符串的第一个字符大写
mystr.capitalize()

<7>title
把字符串的每个单词首字母大写
>>> a = "hello itcast" >>> a.title() 'Hello Itcast'
<8>startswith
检查字符串是否是以 obj 开头, 是则返回 True,否则返回 False
mystr.startswith(obj)

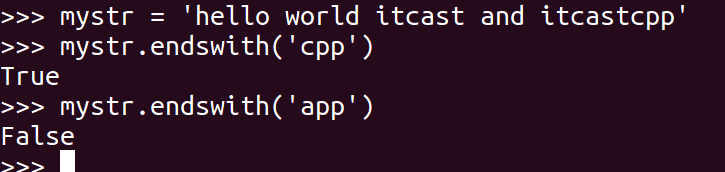
<9>endswith
检查字符串是否以obj结束,如果是返回True,否则返回 False.

mystr.endswith(obj)
<10>lower
转换 mystr 中所有大写字符为小写
mystr.lower()

<11>upper
转换 mystr 中的小写字母为大写
mystr.upper()

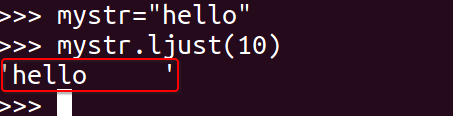
<12>ljust
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
mystr.ljust(width)
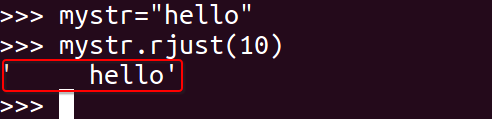
<13>rjust
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
mystr.rjust(width)
<14>center
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
mystr.center(width)

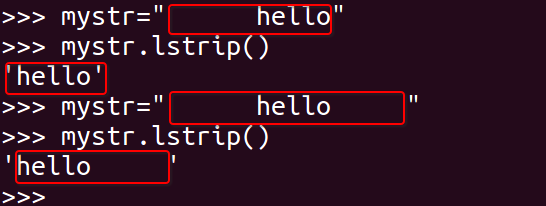
<15>lstrip
删除 mystr 左边的空白字符
mystr.lstrip()
<16>rstrip
删除 mystr 字符串末尾的空白字符
mystr.rstrip()

<17>strip
删除mystr字符串两端的空白字符
>>> a = " itcast " >>> a.strip() 'itcast'
<18>rfind
类似于 find()函数,不过是从右边开始查找
mystr.rfind(str, start=0,end=len(mystr) )

<19>rindex
类似于 index(),不过是从右边开始.
mystr.rindex( str, start=0,end=len(mystr))

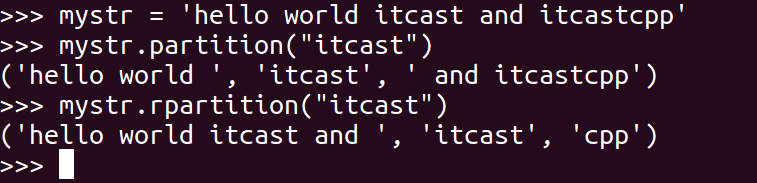
<20>partition
把mystr以str分割成三部分,str前,str和str后
mystr.partition(str)

<21>rpartition
类似于 partition()函数,不过是从右边开始.
mystr.rpartition(str)
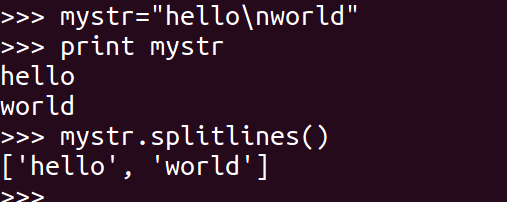
<22>splitlines
按照行分隔,返回一个包含各行作为元素的列表
mystr.splitlines()
<23>isalpha
如果 mystr 所有字符都是字母 则返回 True,否则返回 False
mystr.isalpha()

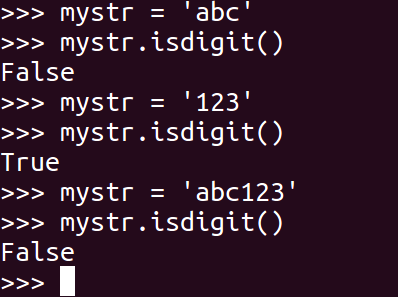
<24>isdigit
如果 mystr 只包含数字则返回 True 否则返回 False.
mystr.isdigit()
<25>isalnum
如果 mystr 所有字符都是字母或数字则返回 True,否则返回 False
mystr.isalnum()
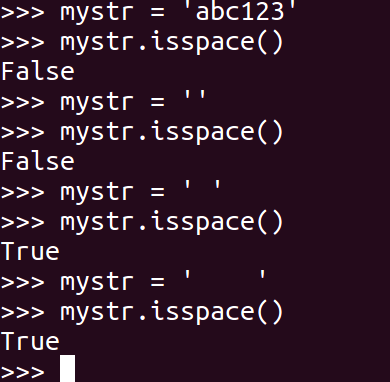
<26>isspace
如果 mystr 中只包含空格,则返回 True,否则返回 False.
mystr.isspace()
<27>join
mystr 中每个字符后面插入str,构造出一个新的字符串
mystr.join(str)
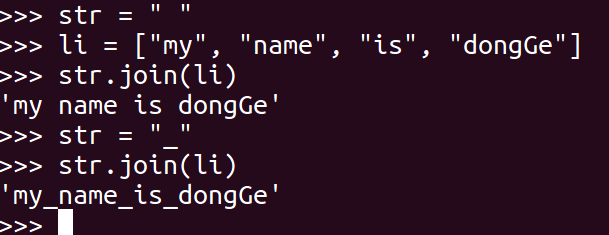
想一想
- 给定一个字符串aStr,返回使用空格或者' '分割后的倒数第二个子串

列表介绍
想一想:
前面学习的字符串可以用来存储一串信息,那么想一想,怎样存储咱们班所有同学的名字呢?
定义100个变量,每个变量存放一个学生的姓名可行吗?有更好的办法吗?
答:
列表
<1>列表的格式
变量A的类型为列表
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
比C语言的数组强大的地方在于列表中的元素可以是不同类型的
testList = [1, 'a']
<2>打印列表
demo: namesList = ['xiaoWang','xiaoZhang','xiaoHua'] print(namesList[0]) print(namesList[1]) print(namesList[2]) 结果: xiaoWang xiaoZhang xiaoHua
列表的循环遍历
1. 使用for循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
demo: namesList = ['xiaoWang','xiaoZhang','xiaoHua'] for name in namesList: print(name) 结果: xiaoWang xiaoZhang xiaoHua
2. 使用while循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
demo: namesList = ['xiaoWang','xiaoZhang','xiaoHua'] length = len(namesList) i = 0 while i<length: print(namesList[i]) i+=1 结果: xiaoWang xiaoZhang xiaoHua
2. 使用while循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
demo: namesList = ['xiaoWang','xiaoZhang','xiaoHua'] length = len(namesList) i = 0 while i<length: print(namesList[i]) i+=1 结果: xiaoWang xiaoZhang xiaoHua
列表的相关操作
列表中存放的数据是可以进行修改的,比如"增"、"删"、"改""
<1>添加元素("增"append, extend, insert)
append
通过append可以向列表添加元素
demo:
#定义变量A,默认有3个元素 A = ['xiaoWang','xiaoZhang','xiaoHua'] print("-----添加之前,列表A的数据-----") for tempName in A: print(tempName) #提示、并添加元素 temp = input('请输入要添加的学生姓名:') A.append(temp) print("-----添加之后,列表A的数据-----") for tempName in A: print(tempName)
结果:

extend
通过extend可以将另一个集合中的元素逐一添加到列表中
>>> a = [1, 2] >>> b = [3, 4] >>> a.append(b) >>> a [1, 2, [3, 4]] >>> a.extend(b) >>> a [1, 2, [3, 4], 3, 4]
insert
insert(index, object) 在指定位置index前插入元素object
>>> a = [0, 1, 2] >>> a.insert(1, 3) >>> a [0, 3, 1, 2]
<2>修改元素("改")
修改元素的时候,要通过下标来确定要修改的是哪个元素,然后才能进行修改
demo:
#定义变量A,默认有3个元素 A = ['xiaoWang','xiaoZhang','xiaoHua'] print("-----修改之前,列表A的数据-----") for tempName in A: print(tempName) #修改元素 A[1] = 'xiaoLu' print("-----修改之后,列表A的数据-----") for tempName in A: print(tempName)
结果:
-----修改之前,列表A的数据----- xiaoWang xiaoZhang xiaoHua -----修改之后,列表A的数据----- xiaoWang xiaoLu xiaoHua
<3>查找元素("查"in, not in, index, count)
所谓的查找,就是看看指定的元素是否存在
in, not in
python中查找的常用方法为:
- in(存在),如果存在那么结果为true,否则为false
- not in(不存在),如果不存在那么结果为true,否则false
demo
#待查找的列表 nameList = ['xiaoWang','xiaoZhang','xiaoHua'] #获取用户要查找的名字 findName = input('请输入要查找的姓名:') #查找是否存在 if findName in nameList: print('在字典中找到了相同的名字') else: print('没有找到')
结果1:(找到)

结果2:(没有找到)

说明:
in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在
index, count
index和count与字符串中的用法相同
>>> a = ['a', 'b', 'c', 'a', 'b'] >>> a.index('a', 1, 3) # 注意是左闭右开区间 Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 'a' is not in list >>> a.index('a', 1, 4) 3 >>> a.count('b') 2 >>> a.count('d') 0
<4>删除元素("删"del, pop, remove)
类比现实生活中,如果某位同学调班了,那么就应该把这个条走后的学生的姓名删除掉;在开发中经常会用到删除这种功能。
列表元素的常用删除方法有:
- del:根据下标进行删除
- pop:删除最后一个元素
- remove:根据元素的值进行删除
demo:(del)
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] print('------删除之前------') for tempName in movieName: print(tempName) del movieName[2] print('------删除之后------') for tempName in movieName: print(tempName)
结果:
------删除之前------ 加勒比海盗 骇客帝国 第一滴血 指环王 霍比特人 速度与激情demo:(pop) 加勒比海盗 骇客帝国 指环王 霍比特人 速度与激情
demo:(pop)
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] print('------删除之前------') for tempName in movieName: print(tempName) movieName.pop() print('------删除之后------') for tempName in movieName: print(tempName)
结果:
------删除之前------ 加勒比海盗 骇客帝国 第一滴血 指环王 霍比特人 速度与激情 ------删除之后------ 加勒比海盗 骇客帝国 第一滴血 指环王 霍比特人
demo:(remove)
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情'] print('------删除之前------') for tempName in movieName: print(tempName) movieName.remove('指环王') print('------删除之后------') for tempName in movieName: print(tempName)
结果:
------删除之前------ 加勒比海盗 骇客帝国 第一滴血 指环王 霍比特人 速度与激情 ------删除之后------ 加勒比海盗 骇客帝国 第一滴血 霍比特人 速度与激情
<5>排序(sort, reverse)
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
reverse方法是将list逆置。
>>> a = [1, 4, 2, 3] >>> a [1, 4, 2, 3] >>> a.reverse() >>> a [3, 2, 4, 1] >>> a.sort() >>> a [1, 2, 3, 4] >>> a.sort(reverse=True) >>> a [4, 3, 2, 1]
列表的嵌套
1. 列表嵌套
类似while循环的嵌套,列表也是支持嵌套的
一个列表中的元素又是一个列表,那么这就是列表的嵌套
schoolNames = [['北京大学','清华大学'], ['南开大学','天津大学','天津师范大学'], ['山东大学','中国海洋大学']]
2. 应用
一个学校,有3个办公室,现在有8位老师等待工位的分配,请编写程序,完成随机的分配
#encoding=utf-8 import random # 定义一个列表用来保存3个办公室 offices = [[],[],[]] # 定义一个列表用来存储8位老师的名字 names = ['A','B','C','D','E','F','G','H'] i = 0 for name in names: index = random.randint(0,2) offices[index].append(name) i = 1 for tempNames in offices: print('办公室%d的人数为:%d'%(i,len(tempNames))) i+=1 for name in tempNames: print("%s"%name,end='') print(" ") print("-"*20)
运行结果如下:

元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
>>> aTuple = ('et',77,99.9) >>> aTuple ('et',77,99.9)
<1>访问元组
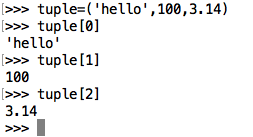
<2>修改元组

说明: python中不允许修改元组的数据,包括不能删除其中的元素。
<3>元组的内置函数count, index
index和count与字符串和列表中的用法相同
>>> a = ('a', 'b', 'c', 'a', 'b') >>> a.index('a', 1, 3) # 注意是左闭右开区间 Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: tuple.index(x): x not in tuple >>> a.index('a', 1, 4) 3 >>> a.count('b') 2 >>> a.count('d') 0
字典介绍
想一想:
如果有列表
nameList = ['xiaoZhang', 'xiaoWang', 'xiaoLi'];
需要对"xiaoWang"这个名字写错了,通过代码修改:
nameList[1] = 'xiaoxiaoWang'
如果列表的顺序发生了变化,如下
nameList = ['xiaoWang', 'xiaoZhang', 'xiaoLi'];
此时就需要修改下标,才能完成名字的修改
nameList[0] = 'xiaoxiaoWang'
有没有方法,既能存储多个数据,还能在访问元素的很方便就能够定位到需要的那个元素呢?
答:
字典
另一个场景:
学生信息列表,每个学生信息包括学号、姓名、年龄等,如何从中找到某个学生的信息?
>>> studens = [[1001, "王宝强", 24], [1002, "马蓉", 23], [1005, "宋喆",24], ...]
循环遍历? No!
<1>生活中的字典

<2>软件开发中的字典
变量info为字典类型:
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
说明:
- 字典和列表一样,也能够存储多个数据
- 列表中找某个元素时,是根据下标进行的
- 字典中找某个元素时,是根据'名字'(就是冒号:前面的那个值,例如上面代码中的'name'、'id'、'sex')
- 字典的每个元素由2部分组成,键:值。例如 'name':'班长' ,'name'为键,'班长'为值<3>根据键访问值
<3>根据键访问值
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
print(info['name'])
print(info['address'])
结果:
班长
地球亚洲中国北京
若访问不存在的键,则会报错:
>>> info['age'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'age'
在我们不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值:
>>> age = info.get('age') >>> age #'age'键不存在,所以age为None >>> type(age) <type 'NoneType'> >>> age = info.get('age', 18) # 若info中不存在'age'这个键,就返回默认值18 >>> age 18
字典的常见操作1
<1>修改元素
字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改
demo:
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
newId = input('请输入新的学号')
info['id'] = int(newId)
print('修改之后的id为%d:'%info['id'])
结果:

<2>添加元素
demo:访问不存在的元素
info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'}
print('id为:%d'%info['id'])
结果:

如果在使用 变量名['键'] = 数据 时,这个“键”在字典中,不存在,那么就会新增这个元素
demo:添加新的元素
info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'}
# print('id为:%d'%info['id'])#程序会终端运行,因为访问了不存在的键
newId = input('请输入新的学号')
info['id'] = newId
print('添加之后的id为:%d'%info['id'])
结果:
请输入新的学号188
添加之后的id为: 188
<3>删除元素
对字典进行删除操作,有一下几种:
- del
- clear()
demo:del删除指定的元素
info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'}
print('删除前,%s'%info['name'])
del info['name']
print('删除后,%s'%info['name'])
结果

demo:del删除整个字典
info = {'name':'monitor', 'sex':'f', 'address':'China'}
print('删除前,%s'%info)
del info
print('删除后,%s'%info)
结果

demo:clear清空整个字典
info = {'name':'monitor', 'sex':'f', 'address':'China'}
print('清空前,%s'%info)
info.clear()
print('清空后,%s'%info)
结果

字典的常见操作2
<1>len()
测量字典中,键值对的个数

<2>keys
返回一个包含字典所有KEY的列表

<3>values
返回一个包含字典所有value的列表

<3>values
返回一个包含字典所有value的列表

<4>items
返回一个包含所有(键,值)元祖的列表

<5>has_key
dict.has_key(key)如果key在字典中,返回True,否则返回False

遍历
通过for ... in ...:的语法结构,我们可以遍历字符串、列表、元组、字典等数据结构。
注意python语法的缩进
字符串遍历
>>> a_str = "hello itcast" >>> for char in a_str: ... print(char,end=' ') ... h e l l o i t c a s t
列表遍历
>>> a_list = [1, 2, 3, 4, 5] >>> for num in a_list: ... print(num,end=' ') ... 1 2 3 4 5
元组遍历
>>> a_turple = (1, 2, 3, 4, 5) >>> for num in a_turple: ... print(num,end=" ") 1 2 3 4 5
字典遍历
<1> 遍历字典的key(键)

<2> 遍历字典的value(值)

<3> 遍历字典的项(元素)

<4> 遍历字典的key-value(键值对)

想一想,如何实现带下标索引的遍历
>>> chars = ['a', 'b', 'c', 'd'] >>> i = 0 >>> for chr in chars: ... print("%d %s"%(i, chr)) ... i += 1 ... 0 a 1 b 2 c 3 d
enumerate()
>>> chars = ['a', 'b', 'c', 'd'] >>> for i, chr in enumerate(chars): ... print i, chr ... 0 a 1 b 2 c 3 d
公共方法
运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | 'Hi!' * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 复制 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
+
>>> "hello " + "itcast" 'hello itcast' >>> [1, 2] + [3, 4] [1, 2, 3, 4] >>> ('a', 'b') + ('c', 'd') ('a', 'b', 'c', 'd')
*
>>> 'ab'*4 'ababab' >>> [1, 2]*4 [1, 2, 1, 2, 1, 2, 1, 2] >>> ('a', 'b')*4 ('a', 'b', 'a', 'b', 'a', 'b', 'a', 'b')
in
>>> 'itc' in 'hello itcast' True >>> 3 in [1, 2] False >>> 4 in (1, 2, 3, 4) True >>> "name" in {"name":"Delron", "age":24} True
注意,in在对字典操作时,判断的是字典的键
python内置函数
Python包含了以下内置函数
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | cmp(item1, item2) | 比较两个值 |
| 2 | len(item) | 计算容器中元素个数 |
| 3 | max(item) | 返回容器中元素最大值 |
| 4 | min(item) | 返回容器中元素最小值 |
| 5 | del(item) | 删除变量 |
cmp
>>> cmp("hello", "itcast") -1 >>> cmp("itcast", "hello") 1 >>> cmp("itcast", "itcast") 0 >>> cmp([1, 2], [3, 4]) -1 >>> cmp([1, 2], [1, 1]) 1 >>> cmp([1, 2], [1, 2, 3]) -1 >>> cmp({"a":1}, {"b":1}) -1 >>> cmp({"a":2}, {"a":1}) 1 >>> cmp({"a":2}, {"a":2, "b":1}) -1
注意:cmp在比较字典数据时,先比较键,再比较值。
len
>>> len("hello itcast") 12 >>> len([1, 2, 3, 4]) 4 >>> len((3,4)) 2 >>> len({"a":1, "b":2}) 2
注意:len在操作字典数据时,返回的是键值对个数。
max
>>> max("hello itcast") 't' >>> max([1,4,522,3,4]) 522 >>> max({"a":1, "b":2}) 'b' >>> max({"a":10, "b":2}) 'b' >>> max({"c":10, "b":2}) 'c'
del
del有两种用法,一种是del加空格,另一种是del()
>>> a = 1 >>> a 1 >>> del a >>> a Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'a' is not defined >>> a = ['a', 'b'] >>> del a[0] >>> a ['b'] >>> del(a) >>> a Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'a' is not defined
多维列表/元祖访问的示例
>>> tuple1 = [(2,3),(4,5)] >>> tuple1[0] (2, 3) >>> tuple1[0][0] 2 >>> tuple1[0][2] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: tuple index out of range >>> tuple1[0][1] 3 >>> tuple1[2][2] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range >>> tuple2 = tuple1+[(3)] >>> tuple2 [(2, 3), (4, 5), 3] >>> tuple2[2] 3 >>> tuple2[2][0] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'int' object is not subscriptable
引用
想一想
>>> a = 1 >>> b = a >>> b 1 >>> a = 2 >>> a 2
请问此时b的值为多少?
>>> a = [1, 2] >>> b = a >>> b [1, 2] >>> a.append(3) >>> a [1, 2, 3]
请问此时b的值又是多少?
引用
在python中,值是靠引用来传递来的。
我们可以用id()来判断两个变量是否为同一个值的引用。 我们可以将id值理解为那块内存的地址标示。
>>> a = 1 >>> b = a >>> id(a) 13033816 >>> id(b) # 注意两个变量的id值相同 13033816 >>> a = 2 >>> id(a) # 注意a的id值已经变了 13033792 >>> id(b) # b的id值依旧 13033816
>>> a = [1, 2] >>> b = a >>> id(a) 139935018544808 >>> id(b) 139935018544808 >>> a.append(3) >>> a [1, 2, 3] >>> id(a) 139935018544808 >>> id(b) # 注意a与b始终指向同一个地址 139935018544808

可变类型与不可变类型
可变类型,值可以改变:
- 列表 list
- 字典 dict
不可变类型,值不可以改变:
- 数值类型 int, long, bool, float
- 字符串 str
- 元组 tuple
怎样交换两个变量的值?
想一想
1. 编程实现对一个元素全为数字的列表,求最大值、最小值
2. 编写程序,完成以下要求:
- 统计字符串中,各个字符的个数
- 比如:"hello world" 字符串统计的结果为: h:1 e:1 l:3 o:2 d:1 r:1 w:1
3. 编写程序,完成以下要求:
- 完成一个路径的组装
- 先提示用户多次输入路径,最后显示一个完成的路径,比如
/home/python/ftp/share
4. 编写程序,完成“名片管理器”项目
- 需要完成的基本功能:
- 添加名片
- 删除名片
- 修改名片
- 查询名片
- 退出系统
- 程序运行后,除非选择退出系统,否则重复执行功能