高级语言分类
编译类:
编译是指在应用源程序执行之前,就将程序源代码“翻译”成目标代码(机器语言),因此其目标程序可以脱离其语言环境独立执行(编译后生成的可执行文件,是cpu可以理解的二进制的机器码组成的),使用比较方便,效率较高。但应用程序一旦需要修改,必须先修改源代码,再重新编译生成的新目标文件(*.obj)才能执行,只有目标文件而没有源代码,修改很不方便
编译后程序运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差。如C C++ Delphi等。
解释类:
执行方式类似于我们日常生活中的“同声翻译”,应用程序源代码一边由相应语言的解释器“翻译”成目标代码(机器语言),一边执行,因此效率比较低,而且不能生成可独立执行的可执行文件,应用程序不能脱离其解释器(想运行,必须先装上解释器)但这种方式比较灵活,可以动态调整,修改应用程序。
如Python java php ruby
编译型和解释型比较
编译型:
1.把源代码编译成机器语言的可执行程序
2.执行 可执行程序文件
优点:
1.程序执行时,不再需要源代码,不依赖语言环境,因为执行的是机器码文件
2.执行速度快,因为你的程序代码已经翻译成了是计算机可以直接理解的机器语言
缺点:
1.每次修改了源代码,需要重新编译,生成机器码文件
2.跨平台性不好,不同操作系统,调用底层的机器指令不同,需要不同平台生成不同的机器码文件
解释型:
1.用户调用解释器,执行源代码文件
2.解释器把源代码文件边解释成机器语言,边交给cpu执行
优点:
1.天生跨平台,因为解释器已经做好了对不同平台的交互处理,用户写的源代码不需要再考虑平台差异性。
2.随时修改,立刻见效,改完源代码后直接运行看效果
缺点:
1.运行效率低,所有的代码均需经过解释器边解释边执行,速度不编译型慢
2.代码是明文
总结:
机器语言
优点:最底层,速度快。缺点:最复杂,开发效率低。
汇编语言
优点:比较底层,速度快。缺点:复杂,开发效率低。
高级语言:
编译型语言执行速度快,不依赖语言环境运行,跨平台差。
解释型跨平台好,但是执行速度慢,依赖解释器运行。
变量:
定义:是被用来存储信息的,存储在内存里,方便被后面程序引用。
标记数据,存储数据
规范:变量名 = 变量值
1.变量名只能是字母、数字、或下划线任意组合
2.变量名第一个字符不能是数字
3.关键字不能声明为变量名
命名习惯:
驼峰体:StuName = 'abc'
下划线:number_of_students = 80
官方建议下划线
避免一下方式:1.中文 2.拼音 3.过长 4.词不达意
常量:Python中没有专门的语法代表常量,程序员约定俗称变量名全为大写。
数据类型
数字
int(整型) 32位机器上取值范围-2**31~2**31-1
64位机器上取值范围-2**63~2**63-1
long(长整型) 在python3里不再有long类型,全是int
除了int和long之外,还有float浮点型,复数型
字符串
在Python中,加了引号的字符都被认为是字符串
name = `abc` age = ``18`` msg = ```hello my friend```
单引号和双引号没有区别,某些情况注意区分
多行字符串必须用多引号
不加引号的被认为是变量 所以 name = jack python会认为是变量赋值,变量需要先声明再使用,所以会报错。
字符串拼接
相加 相加就是简单的拼接 相乘 就是复制自己多次,再拼接在一起
a = 'My name ' name = 'abc'
b = 'is python' print(name*3)
print(a+b) >> abcabcabc
>> My name is python
布尔类型
两个值 True真 False假
主要用于逻辑判断
格式化输出
1.通过%s占位符 s代表string d代表digit f代表float
name = input("Name:") age = input("Age:") job = input("Job:") hometown = input("HomeTown:") info = """ --------info of %s ------ Name:%s Age:%s Job:%s HomeTown:%s ------------end --------- """ % (name,name,age, job, hometown) print(info) 结果: Name:a Age:b Job:c HomeTown:d --------info of a ------ Name:a Age:b Job:c HomeTown:d ------------end ---------
注意!
input()方法输入的默认都是str
如果使用占位符%d则会报错
需要进行转换
age = int(input("Age:")) 转化为int类型
运算符
运算按种类可分为算术运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算。
算术运算
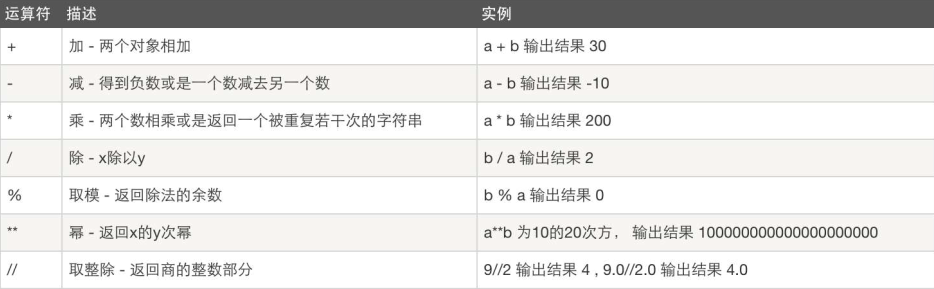
%取模 常用于区分奇偶数
比较运算
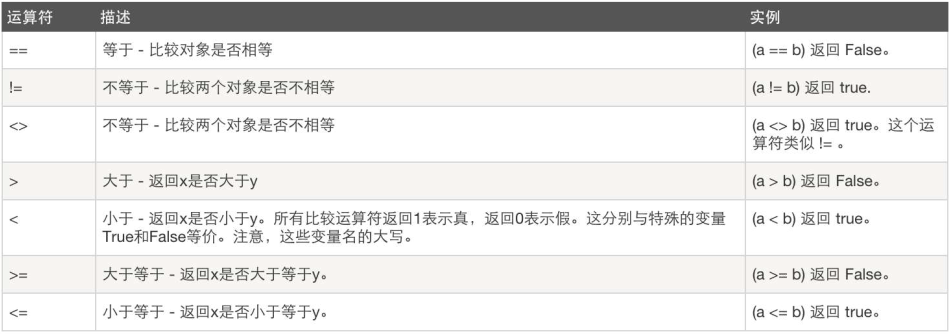
<> python3已经不用
赋值运算
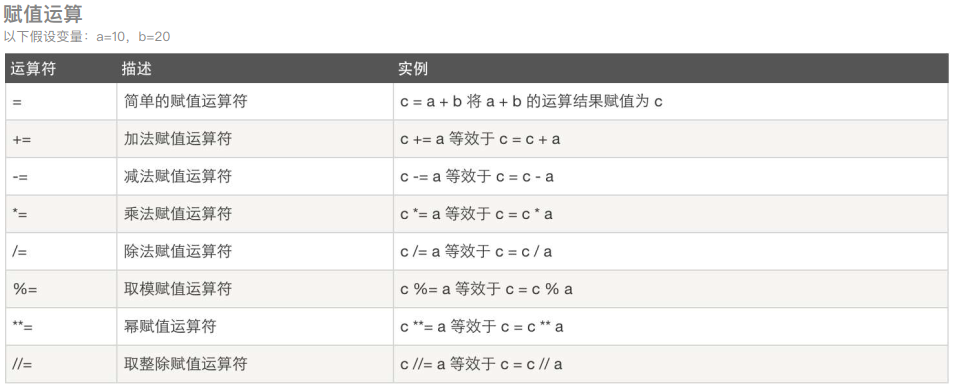
逻辑运算

流程控制
单分支
if 条件:
满足条件后要执行的代码
双分支
if 条件:
满足条件执行代码
else:
if条件不满足走这里
多分支
if 条件:
满足条件执行代码
elif 条件:
上面不满足走这个
elif 条件:
上面不满足走这个
else:
上面都不满足走这个
小知识点:pass方法
while循环
loop
while True:
执行
死循环:
count = 0
while True:
print(count)
count+=1
循环中止语句
break:用于完全结束一个循环,跳出循环体执行循环后面的语句
count = 0 while count <= 100: print("loop",count) if count == 5: break count+=1 print("--------------------")
结果:
loop 0
loop 1
loop 2
loop 3
loop 4
loop 5
--------------------
continue:终止本次循环,接着继续执行后面的循环
count = 0 while count <= 100: count += 1 if count>5 and count<95: continue print("loop",count) print("--------------------") 结果: loop 1 loop 2 loop 3 loop 4 loop 5 loop 95 loop 96 loop 97 loop 98 loop 99 loop 100 loop 101 --------------------
练习 猜年纪,3次机会,猜完问需不需要再玩
思路:嵌套循环
#第一种方法 AGE = 26 while True: count = 0 while count < 3: user_guess = int(input("请输入年龄>>")) if user_guess == AGE: print("Bingo!") break elif user_guess < AGE: print("try bigger!") else: print("try smaller!") count += 1 chose = input("还想玩吗?输入Y或N:") if chose == "Y": continue else: break
思路:修改标识符
#第二种方法 AGE = 26 count = 0 while count < 3: user_guess = int(input("请输入年龄>>")) if user_guess == AGE: print("Bingo!") break elif user_guess < AGE: print("try bigger!") else: print("try smaller!") count += 1 if count == 3: chose = input("还想玩吗?输入Y或N:") if chose == "Y" or chose == "y": count = 0 continue else: break
while ...else 语句
其他语言else一般只与if 搭配,python可以和while搭配
while后面的else作用是指,当while循环正常执行完,中间没有被break终止的话,就会执行else后面的语句
实际作用是 提供了一种简便的方法检测循环是否正常,是否中间有没有被终止过。
count = 0 while count <= 5: print("loop",count) if count == 3: break count+=1 else: print("loop is done...") #结果: loop 0 loop 1 loop 2 loop 3