public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { //accept String line = value.toString(); //split String[] words = line.split(" "); //loop for(String w : words){ //send context.write(new Text(w), new LongWritable(1)); } } }
Mapper这里继承的时候泛型限定了4个类型<LongWritable, Text, Text, LongWritable>,分别是输入的key,value,输出的key,value的类型,LongWritable是hadoop中long的序列化类,Text是String的序列化类。
map函数中,Mapper从文档中得到偏移量(本程序不用,不管他)在key中,每行的值在value中,然后从value中用空格分开得到每个词,然后现在得到的每个词都是一次的,所以给content中添加<单词,1>,保存在content中,传给reduce。
Reduce的代码:
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //define a counter long counter = 0; //loop for(LongWritable l : values){ counter += l.get(); } //write context.write(key, new LongWritable(counter)); } }
Reduce继承的时候,限定的<Text, LongWritable, Text, LongWritable>是输入的<key,value>和输出的<key,value>,输入必须和Mapper的输出一样,输出自己定义,我们定义的是输出单词和它的次数。
Mapper的输出传到Reduce的时候,中间会有一个过程(框架自动干的活,这就是框架的好处了),他会把Mapper输出的键值对中key相同的键值对合并,比如<hadoop,1>和<hadoop,1>会因为key都是hadoop二合并变成<hadoop,[1,1]>,如果再有一个<hadoop,1>,就会合并成<hadoop,[1,1,1]>。
所以在reduce函数中,对每一个key对应的value迭代,每次得到一个次数(我们都设定的1),累加起来就是这个单词的次数了。
然后,每个MapReduce程序都是一个job,需要开启。
运行类(都有注释就不解释了):
public class WCRun { public static void main(String[] args) { try { //下边4行代码设置job的基础信息,setJarByClass就是设置当前运行的main所在的class文件 Configuration conf = new Configuration(); Job job =Job.getInstance(conf); job.setJarByClass(WCRun.class); job.setJobName("wordcount"); //设置Mapper和Reduce的class文件是哪个 job.setMapperClass(WCMapper.class); job.setReducerClass(WCReducer.class); //设置输出的key和value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //设置输入也就是从文件中得到键值对的方法,也就是我们之所以得到的是偏移量和一行文本,就是这个决定的 job.setInputFormatClass(TextInputFormat.class); //设置输出的格式,同输入,不过内容是我们自己定义的 job.setOutputFormatClass(TextOutputFormat.class); //得到输入路径和输出路径,这里用参数,注意输出目录不能存在 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //启动job并等待运行结果 job.waitForCompletion(true); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
!!!再次提醒,输出目录不能存在!!!
运行的话,可以配置本地模式,可以集群运行,我们用集群跑一跑。
首先吧整个程序打包成jar包,项目-->export-->java,jar
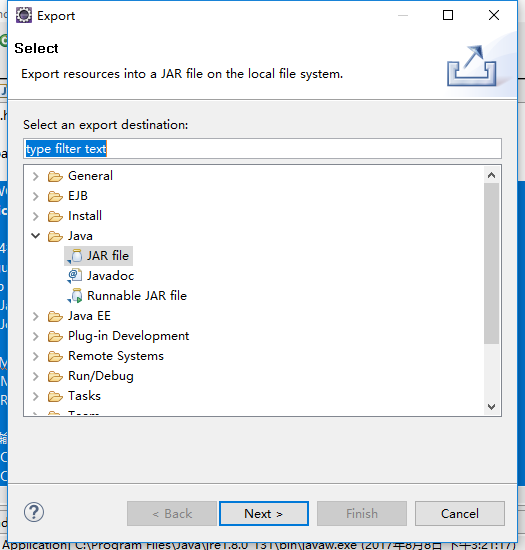
然后把jar文件上传到我们的集群上。
在hdfs里建一个输入文件夹,找一个文档放进去,输出的目录一定不要建(重要的事说三遍)。

然后运行, 指令是 hadoop jar 你的程序的jar包 程序的main在的类 输入文件夹 输出文件夹
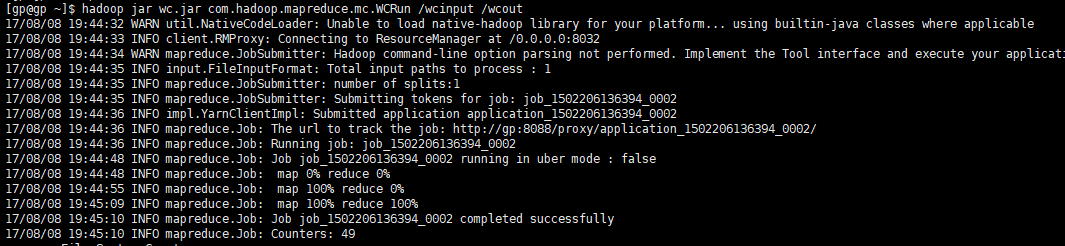
程序运行成功,进入wcout看一看

有两个文件,第一个表示我们成功了,第二个就是结果文件,吧第二个文件get到本地打开看一看
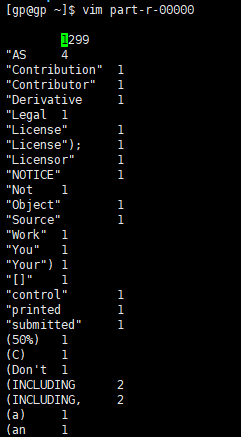
统计的结果,大功告成。
ps:都是学hadoop的新手,欢迎评论留言交流,一起进步。