使用前步骤:
1.Beautiful Soup目前已经被移植到bs4,所以导入Beautiful Soup时先安装bs4库。
2.安装lxml库:如果不使用此库,就会使用Python默认的解析器,而lxml具有功能更加强大、速度更快的特点。
爬取:http://www.cntour.cn/
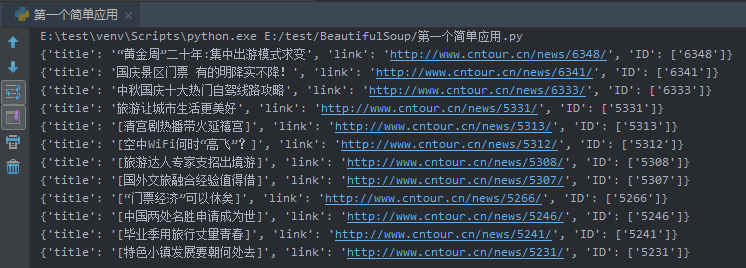
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:XXC import requests from bs4 import BeautifulSoup import re url="http://www.cntour.cn/" #需要爬取的网址 strhtml = requests.get(url); #使用GET方式,获取网页数据 soup = BeautifulSoup(strhtml.text,'lxml') #HTML文档将被转换成Unicode # 编码格式,然后BeautifulSoup选择最适合的解析器来解析文档,此处指定 # lxml解析器,解析后转换成属性结构,每个节点都是Python对象,保存在变量soup中 data = soup.select('#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a') #采用select选择器定位数据 for item in data: #数据清洗和组织数据 result = { 'title':item.get_text(), #获得a标签的文本内内容 'link':item.get('href'), #获得a标签的href属性 'ID':re.findall('d+',item.get('href')) #使用正则匹配其中的数字,d匹配数字,+匹配一个字符一次或多次 } print(result)
结果: