在进行数据访问时,如果没有索引,那么数据库必须进行全表扫描来查找所需的数据,通过在一个或者多个列上创建索引,可以提高对数据的访问速度,索引也是减少磁盘I/O的方法。
索引特性
索引是一个schema对象,它在逻辑和物理上独立于所关联的对象的数据,因此,索引能够在不影响表的情况下进行删除或者创建。
对于单行数据,索引是通向它的快速访问路径,它只影响执行速度,给定一个已被索引的数据,索引直接指向包含该值的数据行的位置。
索引创建后,数据库自动的维护和使用它,数据库也会自动的反映数据的变化,比如在所有相关的索引中添加、更新和删除行,而不需要用户进行额外的操作。即使插入了新行,索引数据的检索性能几乎保持不变,但是,由于数据库对索引的更新,表上有过多索引会降低DML的性能。
索引有下面的属性:
- 可用性(Usability)
索引分为usable或者unusable,默认为usable。unusable索引不会被DML操作维护,并且被优化器忽略。unusable索引能够改善批量加载的性能。可以使索引unusable,然后rebuild它,而不是删除一个索引,然后重新创建它。unusable索引和索引分区不会占用空间,当改变一个usable索引为unusable时,数据库将会删除它的索引段。
- 可见性(Visibility)
索引也可分为visible或者invisible,默认是visible。invisible索引会被DML操作维护,默认不会被优化器使用。将一个索引置为invisible是使索引unusable或者删除的一种替代方法。在不影响整个应用程序的情况下,删除索引之前测试索引的删除或者临时的使用索引,采用invisible索引是尤其有用的方法。
主键和唯一键可以自动的创建索引,而外键需要手动创建索引。
索引类型
Oracle数据库提供了如下索引:
- B-tree索引(B-tree indexes)
B-tree索引是标准的索引类型,有以下子类型:
Index-organized tables:索引组织表与堆组织表不同,因为数据本身是做引;
Reverse key indexes:索引键的字节被反转;
Descending indexes:将某一特定列或一些列按降序存储数据;
B-tree cluster indexes:该类型的索引用于表簇键,不是指向一行,而是指向包含与簇键相关的包含多行的块。
- 位图和位图连接索引(Bitmap and bitmap join indexes)
在位图索引中,一个索引条目(index entry)使用位图指向多行,相反,B-tree索引指向单行,位图连接索引是连接两个或更多表的位图索 引;
- 基于函数的索引(Function-based indexes)
该类型的索引包含要么是函数转换的列,例如upper函数,或者包含在表达式中。B-tree 索引和位图索引可以基于函数。
- 应用域索引(Application domain indexes)
该类型的索引是由用户在特定的应用程序域中创建的,物理索引不需要使用传统的索引结构,它可以像表一样存储在数据库中,或者像文件一样存储在外部。
下面分别讲解以上索引:
B-tree索引(B-tree indexes)
B-tree,简称为平衡树,是最常见的数据库索引类型。B-tree是被分成范围的值的一个有序列表,通过将一行或行范围和键值相关联,B-tree提供了优秀的检索性能,包括精确匹配和范围搜索。
下面展示B-tree索引的内部结构,如图:
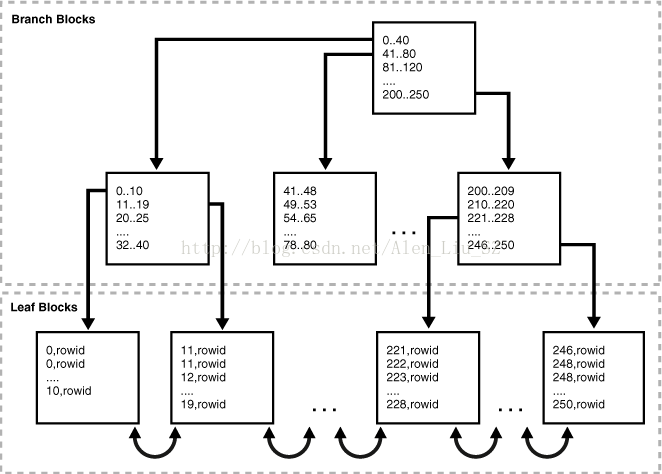
分支块和叶子块(Branch Blocks and Leaf Blocks)
B-tree索引有两种块类型,分别是用于搜索的分支块和存储值的叶子块。B-tree索引的上层分支块包含指向低层索引块的索引数据。在上图中,根分支块有一个条目0-40,它指向下一分支层的最左侧块,该分支块包含如0-10和11-19的条目,每一个条目指向包含落到范围的键值的叶子块。
由于所有的叶子块自动保持在相同的深度,B-tree索引是平衡的。因此,从索引中的任何地方检索任何记录花费的时间几乎相同。索引的高度是从根块到叶子块所需要的块数,分支层的高度是索引的高度减1,在上图中,索引的高度是3,分支层的高度是2。
分支块存放在两个键之间做分支决策所需的最小键的前缀,这种技术使数据库能够在每一个分支块上尽可能多的匹配数据,分支块包含一个指针指向包含键的子块,键和指针的数量受限于块的大小。
叶子块包含每个索引的数据值和用来定位实际行的相对应的rowid,每个条目按照(key,rowid)排序,在叶子块中,键和rowid链接到它的左和右兄弟条目,叶子块自身也是双向链接的,比如上图中的最左侧叶子块(0-11)链接到第二个叶子块(11-19)。
带字符数据的列中的索引基于数据库字符集的字符的二进制值。
索引扫描(Index Scans)
在索引扫描中,数据库通过使用SQL语句指定的索引列值遍历索引来检索一行数据。如果数据库扫描索引来查找一个值,那么它将在n次I/O中找到该值,其中n是B-tree的高度,这就是Oracle数据库索引的基本原理。
如果SQL语句只访问被索引的列,那么数据库直接从索引中读这些值,而不是从表读取。如果语句访问除索引的列之外的列,那么数据库就使用rowid来查找表中的行。通常,数据库通过交替读取索引块和数据块来检索表数据。
全索引扫描(Full Index Scan)
在全索引扫描中,数据库按顺序读取整个索引。如果SQL语句中的谓词(where语句)引用索引中的列,在某些情况下不指定谓词,那么则可以使用全索引扫描,全索引扫描消除了排序,因为数据已经按索引建排序了。
快速全索引扫描(Fast Full Index Scan)
快速全索引扫描是一个全索引扫描,数据库访问索引本身的数据,而不用访问表,数据库读取索引块并没有特别的顺序。
当满足下面的条件时,快速全索引扫描可以替代全表扫描:
- 索引必须包含查询所需的所有列;
- 查询结果集中不能出现NULL值;
索引范围扫描(Index Range Scan)
范围扫描是一个有序扫描,满足下面的特性:
- 索引的一个或多个前导列在查询条件中指定;
- 0、1或更多的值可以作为索引建;
索引唯一扫描(Index Unique Scan)
和索引范围扫描相比,索引唯一扫描必须具有与索引键相关的0个或1个rowid。当谓词引用一个唯一索引键时,数据库执行唯一扫描,一旦查到到第一条记录,索引唯一扫描就停止,因为不会再有第二条记录满足条件。
索引跳跃扫描(Index Skip Scan)
索引跳跃扫描使用复合索引的逻辑子索引。如果复合索引的前导列有更少的不同值,并且该索引的非前导列有许多不同的值,那么使用索引跳跃扫描将会有意想不到的好处。
索引聚簇因子(Index Clustering Factor)
聚簇因子是衡量与索引值相关的行的顺序,在行存储中越有序,则聚簇因子越小。
通过索引来粗略的衡量需要读取整个表的I/O的数量,使用聚簇因子是有用的:
- 如果聚簇因子较高,那么在一个大的索引范围扫描期间Oracle数据库会产生相对较高的I/O的数量,index entry指向随机的表块,那么为了检索由索引指向的数据,数据库需要一次又一次重复的读取同样的数据块;
- 如果聚簇因子较小,那么在一个大的索引范围扫描期间,Oracle数据库会产生相对较低的I/O数量,在一个范围内的索引键倾向于指向同一个数据块,这样数据库就不必一次又一次的重复读取相同的数据块。
反向键索引(Reverse Key Indexes)
反向键索引是一种B-tree索引,它在保持列顺序的同时,物理上反转每个索引键的字节。例如,如果索引键是20,如果这两个字节用标准索引以十六进制存储为C1,15,那么反向键索引存储为15,C1。
反向键解决了B-tree索引右侧叶子块的争用的问题,该问题在RAC数据库多个实例多次修改相同的数据块时尤为突出。
升序和降序索引(Ascending and Descending Indexes)
在升序索引中,Oracle数据库按升序存储数据。默认情况下,字符数据由值的每个字节所包含的二进制值排序,数字数据按照从小到大排序,日期按照从早到晚排序。
降序索引通过在create index语句中指定desc创建,此时,索引按照一个指定的列或多个列以降序的方式存储数据。当查询按某些列升序,并且其他列按照降序排序时,这种情况可以使用降序索引。
位图索引(Bitmap Indexes)
在位图索引中,数据库为每个索引键存储一个位图。在传统的B-tree索引中,一个索引条目(index entry)指向一行,而在位图索引中,每个索引键存储指向多行的指针。
位图索引主要为数据仓库或引用许多列的即席查询环境设计,使用位图索引的情况包括:
- 被索引的列具有低基数(cardinality),也就说,与表的行数相比,不同值的数量很小;
- 被索引的表要么是只读的,要么不会被DML做重大修改;
位图中的每个位对应一个可能的rowid,如果设置了位,则对应rowid的行包含键值。映射函数将位位转换为一个实际的rowid,因此,位图索引提供了与B-tree索引同样的功能,虽然它使用了不同的内部呈现机制。
如果更新单个行的索引列,那么数据库会锁定索引键条目,而不是映射到更新行的各个位,因为一个键指向许多行,在被索引的数据进行DML操作通常会锁定所有这些行,处于这个原因,位图索引不适用于OLTP应用程序。
位图连接索引(Bitmap Join Indexes)
位图连接索引是两个或多个表连接的位图索引,对于表列的每个值,索引在索引表中存储相应行的rowid。相反,在单个表上创建标准的位图索引。
在此不对位图连接索引做过多的介绍,更多关于它的内容可参阅官网。
基于函数的索引(Function-Based Indexes)
可以基于函数或者表达式在一个或者多列创建基于函数的索引,基于函数的索引可以是B-tree索引,也可以是位图索引。
应用程序域索引(Application Domain Indexes)
在此不做过多的介绍,更多关于它的内容可参阅官网。
索引存储(Index Storage)
Oracle数据库在索引段(index segment)中存储索引数据。索引段的表空间可以是用户的默认表空间,也可以在创建索引(create index)时指定一个表空间,为便于管理,把索引和表存放到不同的表空间。
参考:官方文档