1.why sharding?
我们都知道,信息行业发展日益迅速,积累下来的数据信息越来越多,互联网公司门要维护的数据日益庞大。设想一下,假如腾讯公司只用一个数据库的一张表格来存储所有qq注册用户的登录相关信息,毫不夸张的说,那好比就是一场灾难,腾讯少说都有好几个亿的用户,所有的信息都存储在一个数据库的一张表中,那么我们的sleect语句那得多么的消耗硬件资源,用户体验度那是相当的差的,基本上不能去运行了,那谁还去用qq,那怎么办呢,数据分割这时候就派上用场了,它根据数据的特性,将一张表单上的内容根据实际需求分割成多张表单,存储在不同的真实的服务器器上,能够做到指定用户访问指定的服务器,缩小表单,减小单个服务器的压力。其实这样做带来的好处还远不止缩小了表单的大小,来提高用户体验,其实,将数据分割,还可以减小锁表的概率,不会去锁整张表的内容,提高了表的可用率,当单台数据库服务器宕机了,也是是损坏了数据的一小部分,不会导致所有的数据都丢失,数据切割能带来这么多好处,何乐而不为呢?
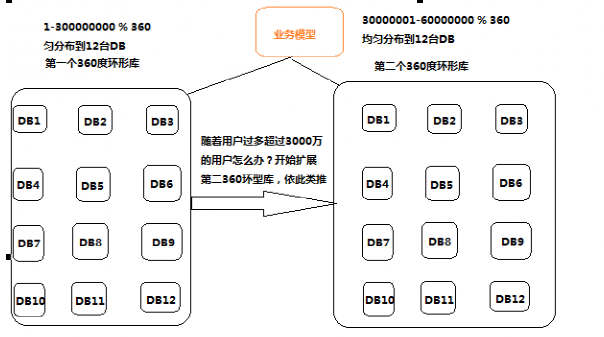
取模和用户量分布计算
取值说明: user_id % 360 这个取模值均匀的分布到这12台DB,
所有server的库名相同,表结构保持一致,
DB_Server1 0~30度 用户数量为:2583354
DB_Server2 31~60度 用户数量为:2500020
DB_Server3 61~90度 用户数量为:2500020
DB_Server4 91~120度 用户数量为:2500019
DB_Server5 121~150度 用户数量为:2499990
DB_Server6 151~180度 用户数量为:2499990
DB_Server7 181~210度 用户数量为:2499990
DB_Server8 211~240 度 用户数量为:2499990
DB_Server9 241~270 度 用户数量为:2499990
DB_Server10 271~300 度 用户数量为:2499990
DB_Server11 301~330 度 用户数量为:2499990
DB_Server12 331~360 度 用户数量为:2416657
DB架构图
当第一个360度环形库,用户量超过3000万怎么办???开始扩容第二个360度环形库
2.数据原型
数据原形:一个数据库,用来存储用户的编号,姓名,以及地址(当然,你可以有多个数据库作为数据原形,可以用到垂直分割进行处理,这里直接用一个数据库作为数据原型进行数据水平切割处理)因为仅仅是去实现水平分割,不做读写分离、也不配置双机热备,所以仅仅需要三台机器,两台独立的mysql服务器,一台amoeba代理服务器即可。
3.环境介绍
Mysql_server1--IP:192.168.1.135(服务器1)
Msyql_serrver2---IP:192.168.1.136(从服务器2)
Amoeba_server--IP:192.168.1.137(代理服务器)
4、设置Mysql_server1 Mysql_server2 设置Amoeba远程访问授权
(首先授权登录mysql服务器的用户,两台mysql服务器都要进行授权)
mysql-->grant all privileges on *.* to amoeba@'%' identified by 'amoeba';
mysql-->flush privileges;
5、创建测试表
(1)在Mysql_server1 和mysql_server2 上。注意:两边的表结构以及表名是一样的.
创建test表
create table test (
user_id integer unsigned not null,
user_name varchar(45),
user_address varchar(100),
primary key (user_id)
)engine=innodb; ·
Query OK, 0 rows affected (0.01 sec
6.amoeba.xml相关配置(安装amoeba略,见前一篇mysql的读写分离)
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:configuration SYSTEM "amoeba.dtd">
<amoeba:configuration xmlns:amoeba="">http://amoeba.meidusa.com/">
<!--
amoeba开放接口相关配置
-->
<server>
<!-- proxy server绑定的端口 -->
<property name="port">9006</property>
<!-- proxy server绑定的IP -->
<property name="ipAddress">192.168.1.137</property>
<!-- proxy server net IO Read thread size -->
<property name="readThreadPoolSize">20</property>
<!-- proxy server client process thread size -->
<property name="clientSideThreadPoolSize">30</property>
<!-- mysql server data packet process thread size -->
<property name="serverSideThreadPoolSize">30</property>
<!-- socket Send and receive BufferSize(unit:K) -->
<property name="netBufferSize">128</property>
<!-- Enable/disable TCP_NODELAY (disable/enable Nagle's algorithm). -->
<property name="tcpNoDelay">true</property>
<!-- 对外验证的用户名 -->
<property name="user">amoeba</property>
<!-- 对外验证的密码 -->
<property name="password">aixocm</property>
<!-- query timeout( default: 60 second , TimeUnit:second) -->
<property name="queryTimeout">60</property>
</server>
<!--
每个ConnectionManager都将作为一个线程启动。
manager负责Connection IO读写/死亡检测
-->
<connectionManagerList>
<connectionManager name="defaultManager" class="com.meidusa.amoeba.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.amoeba.net.AuthingableConnectionManager</property>
<!--
default value is avaliable Processors
<property name="processors">5</property>
-->
</connectionManager>
</connectionManagerList>
<dbServerList>
<!--
一台mysqlServer 需要配置一个pool,
如果多台 平等的mysql需要进行loadBalance,
平台已经提供一个具有负载均衡能力的objectPool:com.meidusa.amoeba.mysql.server.MultipleServerPool
简单的配置是属性加上 virtual="true",该Pool 不允许配置factoryConfig
或者自己写一个ObjectPool。
-->
<!--
mysql服务器授权相关设置
-->
<dbServer name="server1">
<!-- PoolableObjectFactory实现类 -->
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">defaultManager</property>
<!-- 真实mysql数据库端口 -->
<property name="port">3306</property>
<!-- 真实mysql数据库IP -->
<property name="ipAddress">192.168.1.135</property>
<property name="schema">test</property>
<!-- 用于登陆mysql的用户名 -->
<property name="user">amoeba</property>
<!-- 用于登陆mysql的密码 -->
<property name="password">amoeba</property>
</factoryConfig>
<!-- ObjectPool实现类 -->
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">200</property>
<property name="maxIdle">200</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<!--
mysql服务器授权相关设置
-->
<dbServer name="server2">
<!-- PoolableObjectFactory实现类 -->
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="manager">defaultManager</property>
<!-- 真实mysql数据库端口 -->
<property name="port">3306</property>
<!-- 真实mysql数据库IP -->
<property name="ipAddress">192.168.1.136</property>
<property name="schema">test</property>
<!-- 用于登陆mysql的用户名 -->
<property name="user">amoeba</property>
<!-- 用于登陆mysql的密码 -->
<property name="password">amoeba</property>
</factoryConfig>
<!-- ObjectPool实现类 -->
<poolConfig class="com.meidusa.amoeba.net.poolable.PoolableObjectPool">
<property name="maxActive">200</property>
<property name="maxIdle">200</property>
<property name="minIdle">10</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
</dbServerList>
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleConfig">${amoeba.home}/conf/rule.xml</property>
<property name="functionConfig">${amoeba.home}/conf/functionMap.xml</property>
<property name="ruleFunctionConfig">${amoeba.home}/conf/ruleFunctionMap.xml</property>
<property name="LRUMapSize">1500</property>
<property name="defaultPool">server1</property>
<!--
;默认地址池一定要开启
<property name="writePool">master</property>
<property name="readPool">slave</property>
<property name="needParse">true</property>
-->
</queryRouter>
</amoeba:configuration>
7.rule.xml相关配置
基于user_id的水平分割,360水平分割法,前提user_id是连续的。
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:rule SYSTEM "rule.dtd">
<amoeba:rule xmlns:amoeba="">http://amoeba.meidusa.com/">
<tableRule name="test" schema="test" defaultPools="server1,server2">
<rule name="rule1">
<parameters>user_id</parameters>
<expression><![CDATA[
user_id % 360 >=0 and user_id % 360 <=180 ;分成两份,(1-180)+360并且小于5000000存在一个数据库
]]></expression>
<defaultPools>server1</defaultPools>
<readPools>server1</readPools>
<writePools>server1</writePools>
</rule>
<rule name="rule2">
<parameters>user_id</parameters>
<expression><![CDATA[
user_id % 360 >=181 and user_id % 360 <=360 (181-360)+360并且小于5000000存在于一个数据库
]]></expression>
<defaultPools>server2</defaultPools>
<writePools>server2</writePools>
<readPools>server2</readPools>
</rule>
<!--
<rule name="rule4">
<parameters>ID</parameters>
<expression><![CDATA[ ID > 20000000 ]]></expression>
<defaultPools>server3</defaultPools>
</rule>
<rule name="rule3">
<parameters>ID,CREATE_TIME</parameters>
<expression><![CDATA[ID>4 or CREATE_TIME between to_date('2008-11-12 00:00:00.0000') and to_date('2008-12-10 00:00:00.0000') ]]></expression>
<defaultPools>server3</defaultPools>
</rule>
-->
</tableRule>
</amoeba:rule>
8.启动服务
#:nohup bash -x amoeba &
这样的启动方法是为了方便查看启动的过程,会生成nohup.out的文件记录启动过程
重新启动服务需要先杀死已经启动的服务再重新启动服务
ps -ef|grep amoeba|awk '{print $2}'|xargs kill -9
9、插入测试数据
在Amoeba Server登录:
# mysql -uamoeba -paixocm -h 192.168.1.137 -P 9006
mysql->use test;
mysql->insert into test(user_id,user_name,user_address) values('1','user1','China');
特别提示,一定要将表的数组名带上,特别是用来作为水平分割的数组名,如果不接上,分割失败,会在两个服务器上全部插入数据。
mysql->insert into test(user_id,user_name,user_address) values('2','user1','China');
mysql->insert into test(user_id,user_name,user_address) values('3','user1','China');
mysql->insert into test(user_id,user_name,user_address) values('181','user1','China');
mysql->insert into test(user_id,user_name,user_address) values('182','user1','China');
mysql->insert into test(user_id,user_name,user_address) values('183','user1','China');
mysql_server1查看,user_id在1-180数据全部写入了server1
mysql_server2查看,user_id在181-360数据全部写入了server2
10.总结:
(1)、amoeba 是根据 sql 解析来进行水平切分的, 需要把切分的关键字段(这里是user_id),加入到insert sql 语句 中。否则 切分规则无效。无效后,会在 server1, server2 均都插入数据。
(2)、amoeba插入数据的时候必须先use dbname(比如要先use test库名,或者查询带上库名和表名,test.t_user) 否则插入数据会默认插到server1上面
(3)、在rule.xml 指定的ID范围,在插入数据user_id的时候。不能超过这个范围,否则分片无效,
比如定义的ID范围为:
1-500000号
insert into zyalvin(user_id,user_name,user_address)values('5000001','user1','China'); 如果插入ID超过5000000,变成了5000001的话那么这个数据将同时写到server1和server2 导致分片无效。