日常Bug排查-消息不消费
前言
日常Bug排查系列都是一些简单Bug排查,笔者将在这里介绍一些排查Bug的简单技巧,同时顺便积累素材_。
Bug现场
某天下午,在笔者研究某个问题正high的时候。开发突然找到笔者,线上某个系统突然消费不了queue了。Queue不消费也算是日常问题了。淡定的先把流量切到另一个机房,让问题先恢复再说。
消息累积
然后就是看不消费的queue到哪去了,打开mq(消息中间件)控制台,全部累积到mq上了。

同时开发对笔者反映,只有这个queueu积累了,其它queue还是能正常消费的。
出问题时间点
这时笔者还得到了一个关键信息,此问题是DBA对其关联的数据库进行操作后才发生的。当时由于操作灌入的数据库过大,导致数据库主从切换,漂了VIP。从时间点判断,这个应该是问题的诱因。
jstack
既然卡住了,那么老办法,jstack一下,看看我们的mq消费线程在干嘛:
ActiveMQ Session Task-1234
at java.net.SocketInputStream.socketRead0
......
at com.mysql.jdbc.MysqlIO.readFully
......
at org.apache.activemq.ActiveMQMessageConsumer.dispatch
......
很明显的,都卡在MysqlIO.readFully也就是数据库读取上,再也不往下走了。
没配超时
这就肯定是没配超时了,排查了下他们的配置,确实没配。之前系统梳理过好多次,但没想到还是有这种漏网之鱼。这个问题分析本身是很简单的。不过在这里笔者想多聊一下,为什么数据主从切换会形成这样的现象。
mha切换
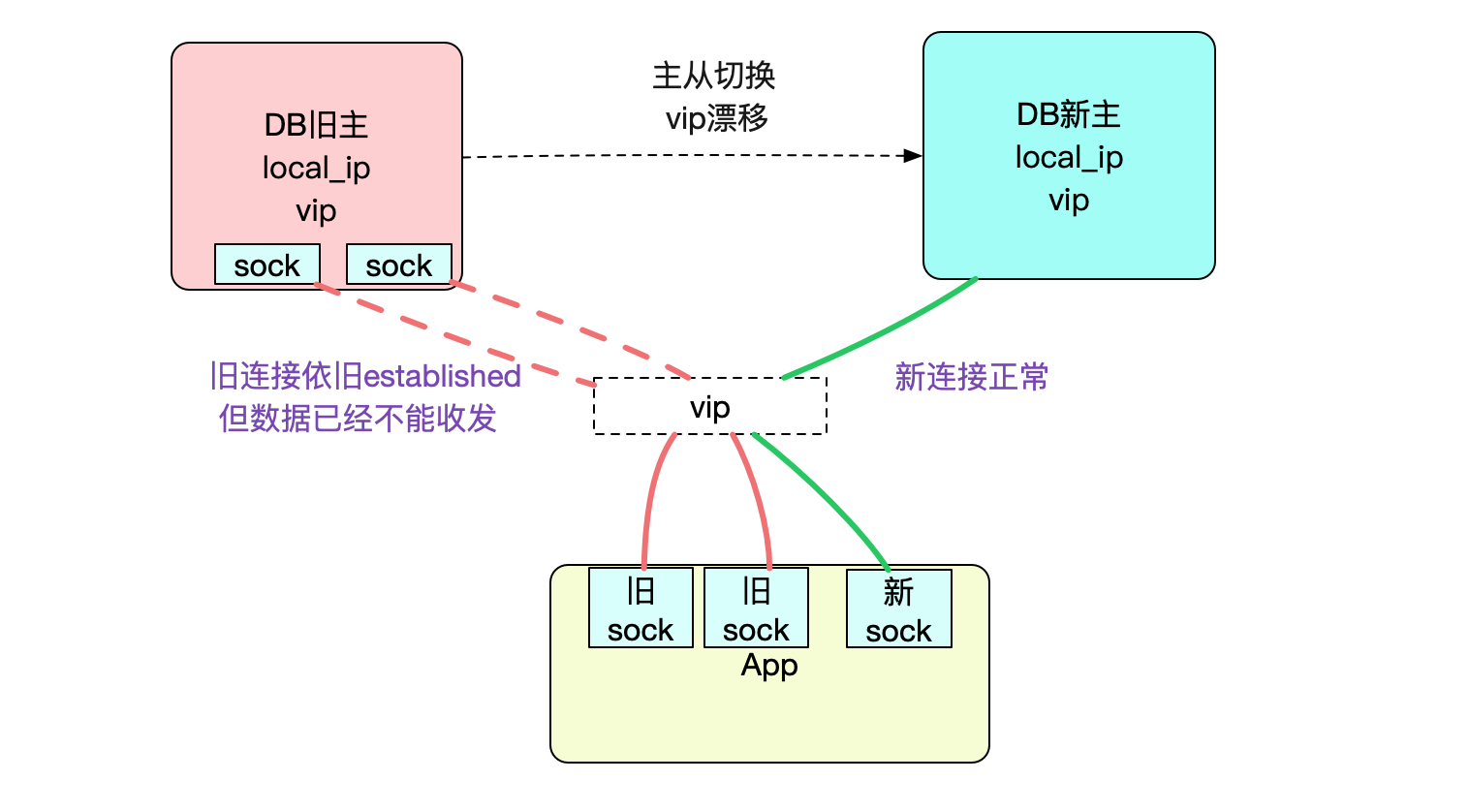
如图所示,mha切换逻辑是将vip从DB旧主上摘掉,然后将vip挂到DB新主上面。为了观察这种行为,笔者写了个python程序进行测试。观察得知,在vip被摘掉的那一刻,双方的通信已经不正常了。但是tcp连接状态依旧是ESTABLISHED。
为什么tcp状态依旧ESTABLISHED
因为ip摘掉并不会让已经存在的socket立马感知,那么socket什么时候能够感知到我们这个连接已经gg了呢。在当前这个场景下,应用没设置socket超时,会有这几种可能:
- 如果这时候App正在发请求给此五元组
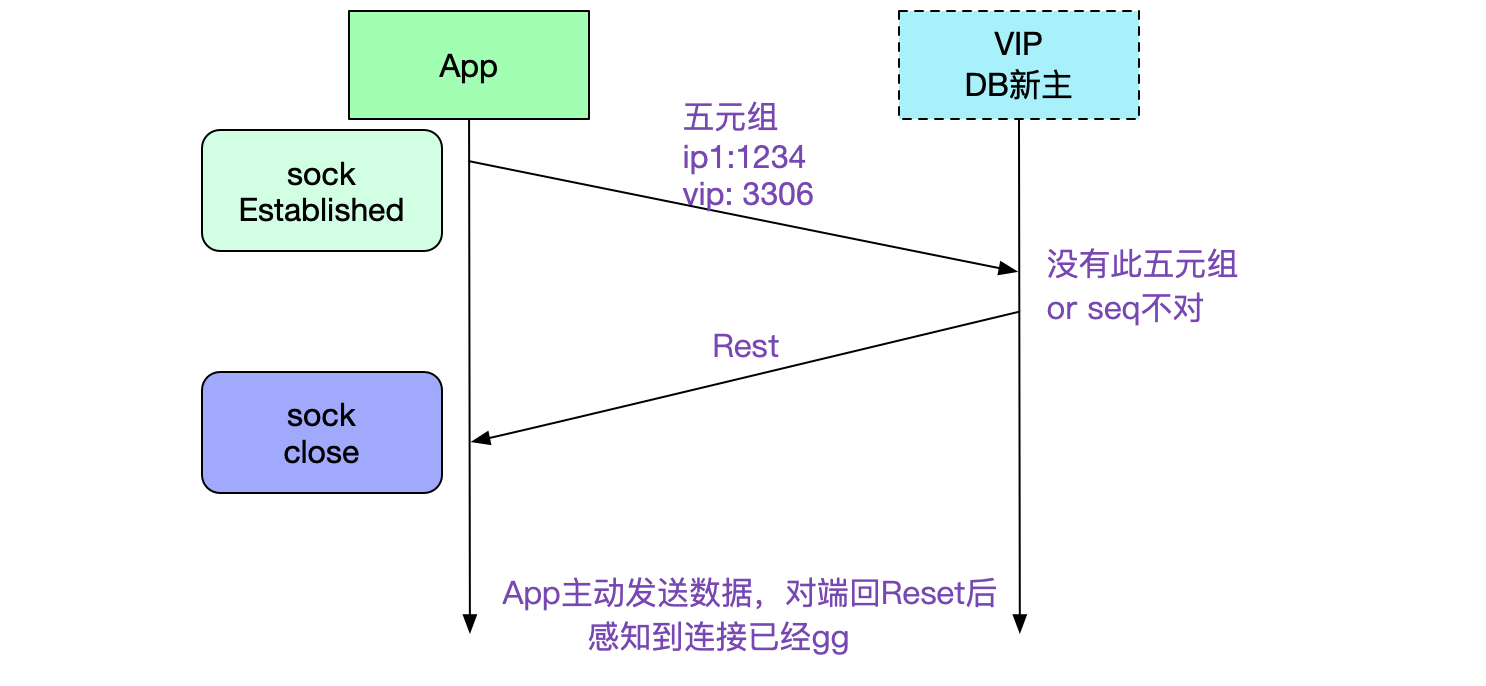
- 如果DB正在写回请求给此五元组
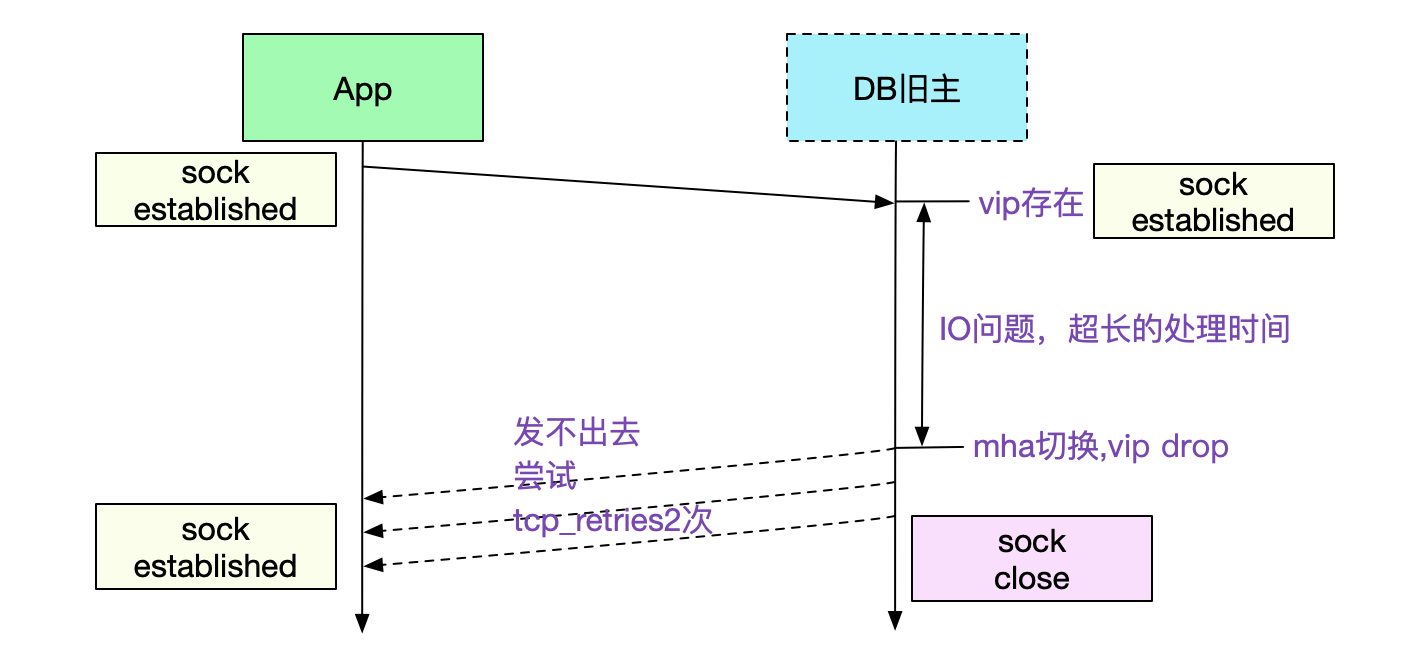
由上面两种情况,我们可以知道哪方作出发送动作,哪方就能够通过reset或者尝试次数过多来感知到这个连接已经gg了。
很明显的,由于我们的应用正卡在socket read,表明我们的App应用并没有发送数据,而是在等待MySQL的返回,那么在不设置超时的情况下,App怎么感知到连接实际上已经不好了呢。
tcp保活定时器
由于应用不做发送动作,那这时就轮到我们的tcp保活定时器tcp_keepalive出马了。linux下默认的内核参数为:
/proc/sys/net/ipv4/tcp_keepalive_time 7200 两小时
/proc/sys/net/ipv4/tcp_keepalive_probes 9 探测9次
/proc/sys/net/ipv4/tcp_keepalive_intvl 75s 每次探测间隔75s
tcp保活定时器默认在7200s也就是两小时后开启,探测9次,每次间隔75s,如果有明确失败或者9次都没返回则判定连接gg。
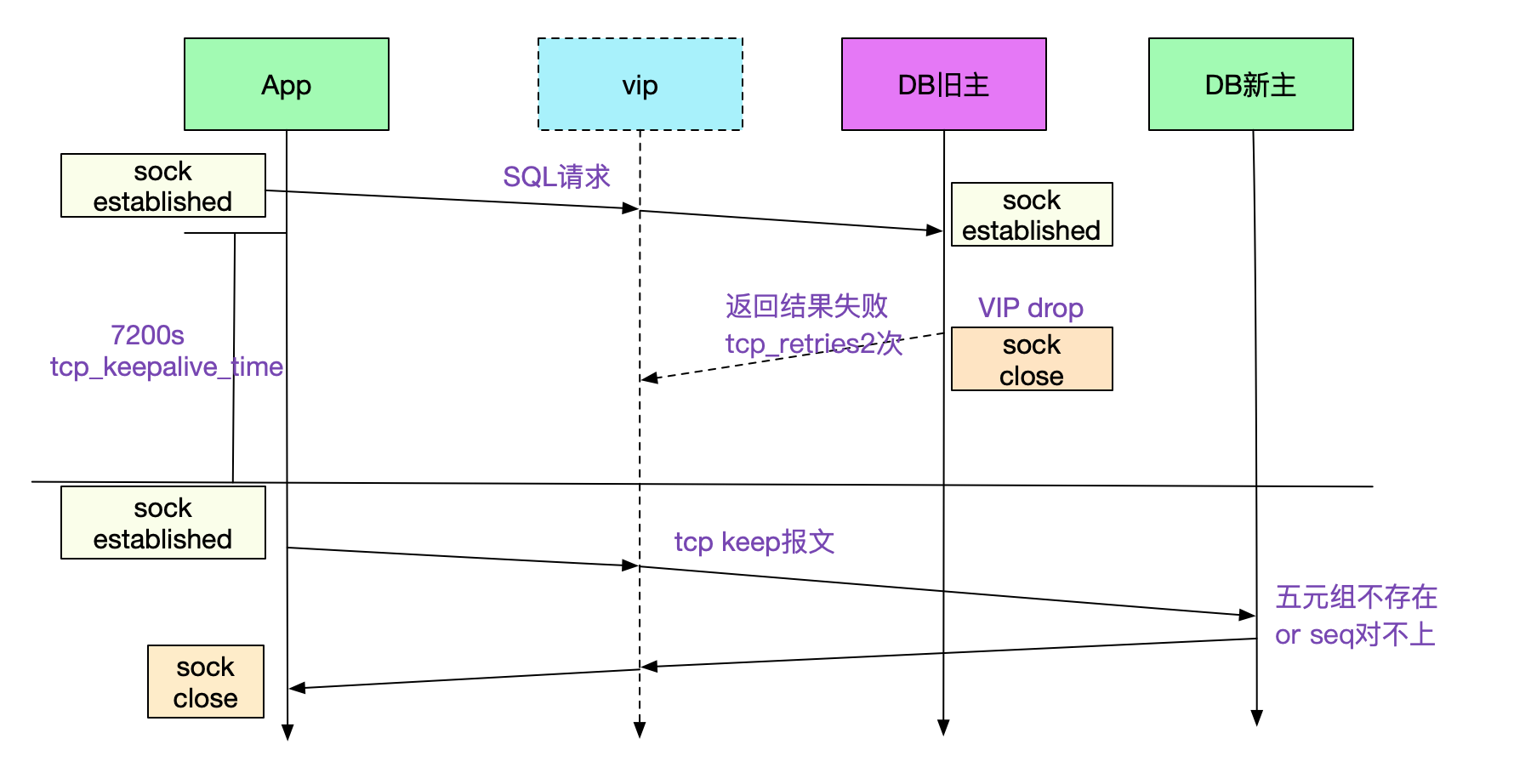
在我们的这个场景中,应用会在两个小时后开始保活,在第一次探测的时候对端发送reset从而应用感知到连接gg。这时候,应用才返回。也就是说,不设置超时时间,遇到这种情况,应用的线程要卡2小时!
如果是DB进程宕or重启
如果不是mha切换,而是DB进程重启或者宕的话,由于Linux内核没宕还存在着。内核会自动将DB进程所属的socket进行close也就是发FIN报文回去。那么应用就可以立马从socket read系统调用中返回了。
物理机宕机
物理机宕机而不漂VIP,应用在不设置超时的时候。如果是发送数据阶段,则tcp_reties2次重试后从socket read系统调用返回。如果不发送数据,和上面的描述基本一样,2个小时后开启保活定时器。唯一不同的是,这次是需要探活9次,所以需要会多花11分钟左右的时间感知。
线下演练为什么不出问题
VIP漂移这种操作,我们在线下演练过,当时应用很快就切换完了。为什么到了线上就会卡住呢?这是因为,线下没有加上IO hang住导致SQL处理时间过长这一条件。SQL很快就返回了,所以我们线下的线程只有很小的概率卡在socket read上面。况且有几十个线程在消费,卡一两个无关大局。
而在我们这次上面,由于SQL处理时间超长,所以基本所有的线程都在VIP漂移的那一刻执行socket read即等待数据库返回阶段,就导致所有线程全部hang住等。这时候只能等待tcp_keepalive或者重启了。
总结
要保证高可用,任何远程调用都需要设置超时。否则就会导致应用长时间无法响应这样的现象。