从linux源码看socket(tcp)的timeout
前言
网络编程中超时时间是一个重要但又容易被忽略的问题,对其的设置需要仔细斟酌。在经历了数次物理机宕机之后,笔者详细的考察了在网络编程(tcp)中的各种超时设置,于是就有了本篇博文。本文大部分讨论的是socket设置为block的情况,即setNonblock(false),仅在最后提及了nonblock socket(本文基于linux 2.6.32-431内核)。
connectTimeout
在讨论connectTimeout之前,让我们先看下java和C语言对于socket connect调用的函数签名:
java:
// 函数调用中携带有超时时间
public void connect(SocketAddress endpoint, int timeout) ;
C语言:
// 函数调用中并不携带超时时间
int connect(int sockfd, const struct sockaddr * sockaddr, socklen_t socklent)
操作系统提供的connect系统调用并没有提供timeout的参数设置而java却有,我们先考察一下原生系统调用的超时策略。
connect系统调用
我们观察一下此系统调用的kernel源码,调用栈如下所示:
connect[用户态]
|->SYSCALL_DEFINE3(connect)[内核态]
|->sock->ops->connect
由于我们考察的是tcp的connect,其socket的内部结构如下图所示:
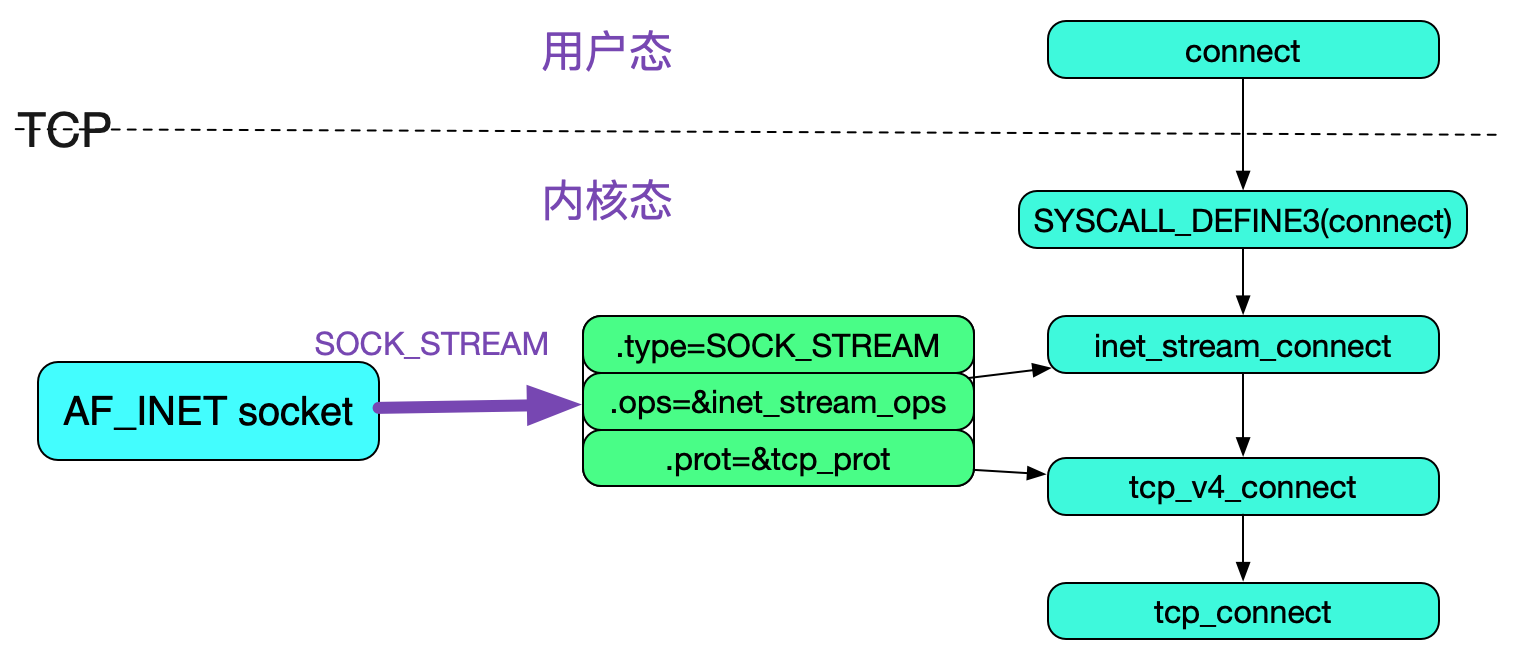
最终调用的是tcp_connect,代码如下所示:
int tcp_connect(struct sock *sk) {
......
// 发送SYN
err = tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
...
/* Timer for repeating the SYN until an answer. */
// 由于是刚建立连接,所以其rto是TCP_TIMEOUT_INIT
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
return 0;
}
又上面代码可知,在tcp_connect设置了重传定时器之后return回了tcp_v4_connect再return到inet_stream_connect。我们继续考察:
int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags)
{
......
// tcp_v4_connect=>tcp_connect
err = sk->sk_prot->connect(sk, uaddr, addr_len);
// 这边用的是sk->sk_sndtimeo
timeo = sock_sndtimeo(sk, flags & O_NONBLOCK);
......
inet_wait_for_connect(sk, timeo));
......
out:
release_sock(sk);
return err;
sock_error:
err = sock_error(sk) ? : -ECONNABORTED;
sock->state = SS_UNCONNECTED;
if (sk->sk_prot->disconnect(sk, flags))
sock->state = SS_DISCONNECTING;
goto out
}
由上面代码可见,可以采用设置SO_SNDTIMEO来控制connect系统调用的超时,如下所示:
setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len);
不设置SO_SNDTIMEO
如果不设置SO_SNDTIMEO,那么会由tcp重传定时器在重传超过设置的时候后超时,如下图所示:

这个syn重传的次数由:
cat /proc/sys/net/ipv4/tcp_syn_retries 笔者机器上是5
来决定。那么我们就来看一下这个重传到底是多长时间:
tcp_connect中:
// 设置的初始超时时间为icsk_rto=TCP_TIMEOUT_INIT为1s
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
其重传定时器的回掉函数为tcp_retransmit_timer:
void tcp_retransmit_timer(struct sock *sk)
{
......
// 检测是否超时
if (tcp_write_timeout(sk))
goto out;
......
// icsk_rto = icsk_rto * 2,由于syn阶段,所以isck_rto不会由于网络传输而改变
// 重传的时候会以1,2,4,8指数递增
icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
// 重设timer
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, icsk->icsk_rto, TCP_RTO_MAX);
out:;
}
而计算tcp_write_timeout的逻辑则是在这篇blog中已经详细描述过,
https://my.oschina.net/alchemystar/blog/1936433
只不过在connect时刻,重传的计算以TCP_TIMEOUT_INIT为单位进行计算。而ESTABLISHED(read/write)时刻,重传以TCP_RTO_MIN进行计算。那么根据这段重传逻辑,我们就可以计算出不同tcp_syn_retries最终表现的超时时间。如下图所示:
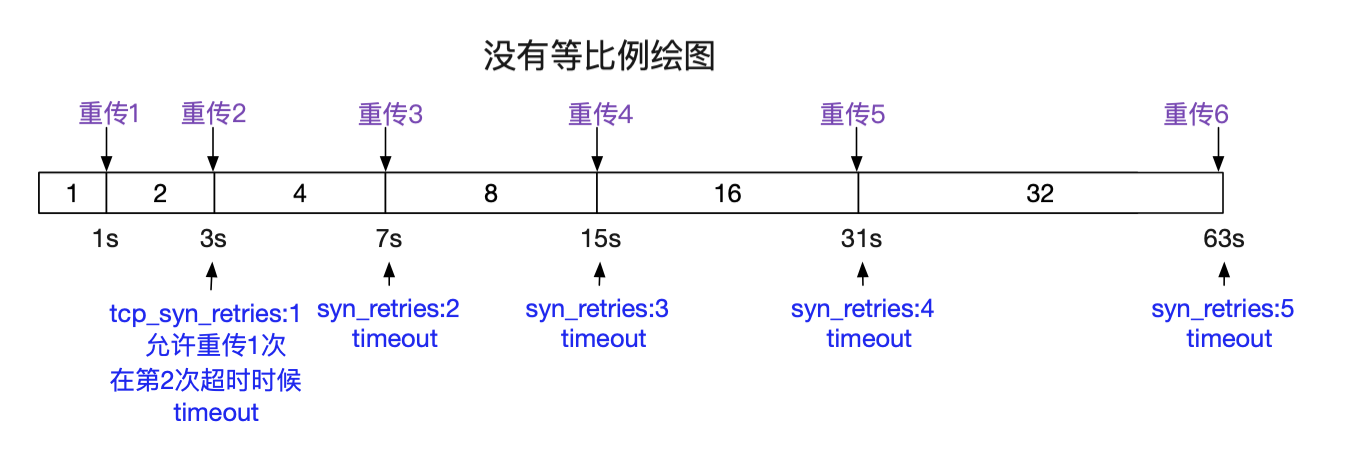
那么整理下表格,对于系统调用,connect的超时时间为:
| tcp_syn_retries | timeout |
|---|---|
| 1 | min(so_sndtimeo,3s) |
| 2 | min(so_sndtimeo,7s) |
| 3 | min(so_sndtimeo,15s) |
| 4 | min(so_sndtimeo,31s) |
| 5 | min(so_sndtimeo,63s) |
上述超时时间和笔者的实测一致。
kernel代码版本细微变化
值得注意的是,linux本身官方发布的2.6.32源码对于tcp_syn_retries2的解释和RFC并不一致(至少笔者阅读的代码如此,这个细微的变化困扰了笔者好久,笔者下载了和机器对应的内核版本后才发现代码改了)。而redhat发布的2.6.32-431已经修复了这个问题(不清楚具体哪个小版本修改的),并将初始RTO设置为1s(官方2.6.32为3s)。这也是,不同内核小版本上的实验会有不同的connect timeout表现的原因(有的抓包到的重传SYN时间间隔为3,6,12......)。以下为代码对比:
========================>linux 内核版本2.6.32-431<========================
#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ)) /* RFC2988bis initial RTO value */
static inline bool retransmits_timed_out(struct sock *sk,
unsigned int boundary,
unsigned int timeout,
bool syn_set)
{
......
unsigned int rto_base = syn_set ? TCP_TIMEOUT_INIT : TCP_RTO_MIN;
......
timeout = ((2 << boundary) - 1) * rto_base;
......
}
========================>linux 内核版本2.6.32.63<========================
#define TCP_TIMEOUT_INIT ((unsigned)(3*HZ)) /* RFC 1122 initial RTO value */
static inline bool retransmits_timed_out(struct sock *sk,
unsigned int boundary
{
......
timeout = ((2 << boundary) - 1) * TCP_RTO_MIN;
......
}
另外,tcp_syn_retries重传次数可以在单个socket中通过setsockopt设置。
JAVA connect API
现在我们考察下java的connect api,其connect最终调用下面的代码:
Java_java_net_PlainSocketImpl_socketConnect(...){
if (timeout <= 0) {
......
connect_rv = NET_Connect(fd, (struct sockaddr *)&him, len);
.....
}else{
// 如果timeout > 0 ,则设置为nonblock模式
SET_NONBLOCKING(fd);
/* no need to use NET_Connect as non-blocking */
connect_rv = connect(fd, (struct sockaddr *)&him, len);
/*
* 这边用系统调用select来模拟阻塞调用超时
*/
while (1) {
......
struct timeval t;
t.tv_sec = timeout / 1000;
t.tv_usec = (timeout % 1000) * 1000;
connect_rv = NET_Select(fd+1, 0, &wr, &ex, &t);
......
}
......
// 重新设置为阻塞模式
SET_BLOCKING(fd);
......
}
}
其和connect系统调用的不同点是,在timeout为0的时候,走默认的系统调用不设置超时时间的逻辑。在timeout>0时,将socket设置为非阻塞,然后用select系统调用去模拟超时,而没有走linux本身的超时逻辑,如下图所示:

由于没有java并没有设置so_sndtimeo的选项,所以在timeout为0的时候,直接就通过重传次数来控制超时时间。而在调用connect时设置了timeout(不为0)的时候,超时时间如下表格所示:
| tcp_syn_retries | timeout |
|---|---|
| 1 | min(timeout,3s) |
| 2 | min(timeout,7s) |
| 3 | min(timeout,15s) |
| 4 | min(timeout,31s) |
| 5 | min(timeout,63s) |
socketTimeout
write系统调用的超时时间
socket的write系统调用最后调用的是tcp_sendmsg,源码如下所示:
int tcp_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size){
......
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
......
while (--iovlen >= 0) {
......
// 此种情况是buffer不够了
if (copy <= 0) {
new_segment:
......
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
skb = sk_stream_alloc_skb(sk, select_size(sk),sk->sk_allocation);
if (!skb)
goto wait_for_memory;
}
......
}
......
// 这边等待write buffer有空间
wait_for_sndbuf:
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
wait_for_memory:
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH);
// 这边等待timeo长的时间
if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
goto do_error;
......
out:
// 如果拷贝了数据,则返回
if (copied)
tcp_push(sk, flags, mss_now, tp->nonagle);
TCP_CHECK_TIMER(sk);
release_sock(sk);
return copied;
out_err:
// error的处理
err = sk_stream_error(sk, flags, err);
TCP_CHECK_TIMER(sk);
release_sock(sk);
return err;
}
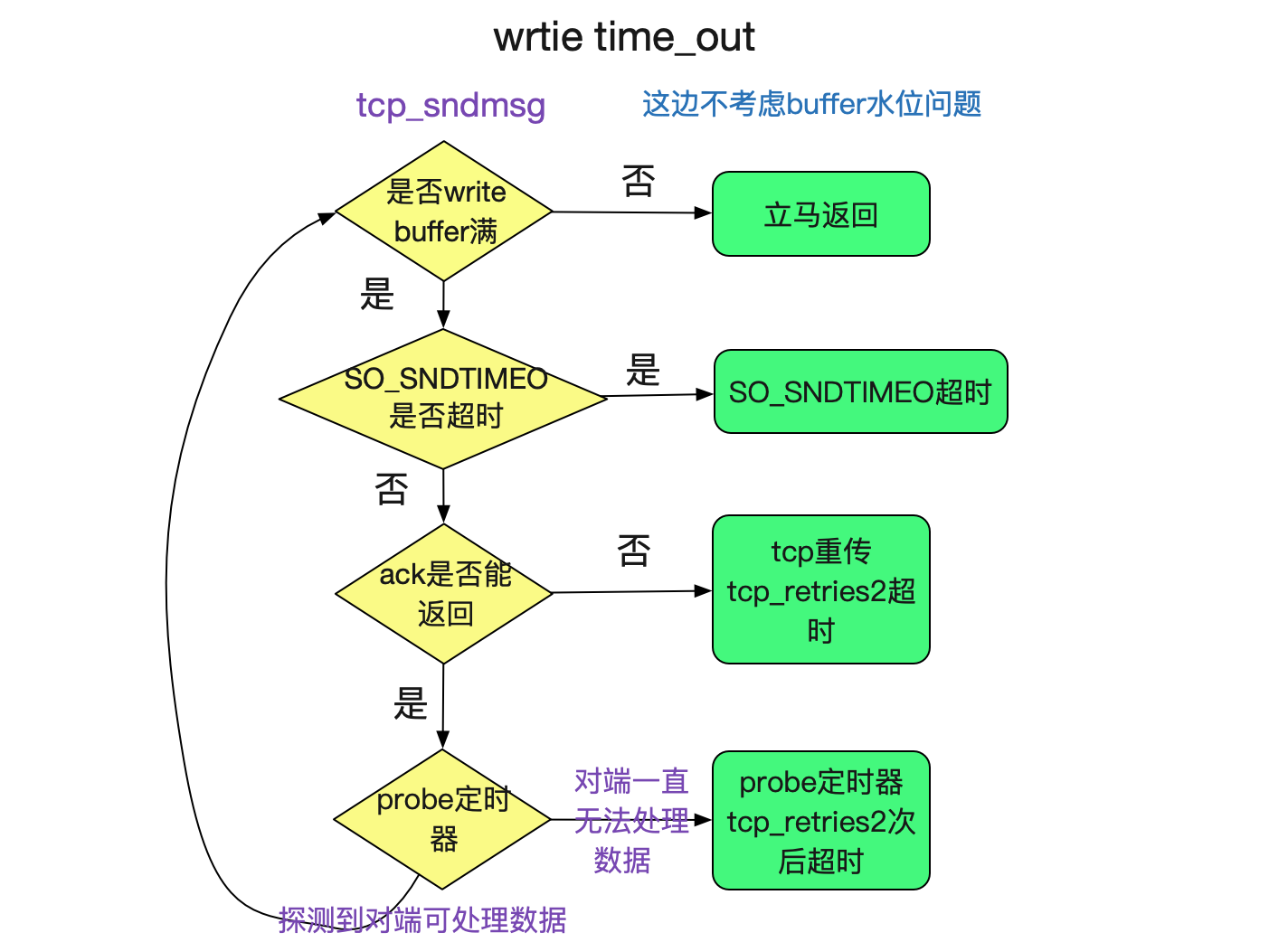
从上面的内核代码看出,如果socket的write buffer依旧有空间的时候,会立马返回,并不会有timeout。但是write buffer不够的时候,会等待SO_SNDTIMEO的时间(nonblock时候为0)。但是如果SO_SNDTIMEO没有设置的时候,默认初始化为MAX_SCHEDULE_TIMEOUT,可以认为其超时时间为无限。那么其超时时间会有另一个条件来决定,我们看下sk_stream_wait_memory的源码:
int sk_stream_wait_memory(struct sock *sk, long *timeo_p){
// 等待socket shutdown或者socket出现err
sk_wait_event(sk, ¤t_timeo, sk->sk_err ||
(sk->sk_shutdown & SEND_SHUTDOWN) ||
(sk_stream_memory_free(sk) &&
!vm_wait));
}
在write等待的时候,如果出现socket被shutdown或者socket出现错误的时候,则会跳出wait进而返回错误。在不考虑对端shutdown的情况下,出现sk_err的时间其实就是其write的timeout时间,那么我们看下什么时候出现sk->sk_err。
SO_SNDTIMEO不设置,write buffer满之后ack一直不返回的情况(例如,物理机宕机)
物理机宕机后,tcp发送msg的时候,ack不会返回,则会在重传定时器tcp_retransmit_timer到期后timeout,其重传到期时间通过tcp_retries2以及TCP_RTO_MIN计算出来。其源码可见笔者的blog:
https://my.oschina.net/alchemystar/blog/1936433
tcp_retries2的设置位置为:
cat /proc/sys/net/ipv4/tcp_retries2 笔者机器上是5,默认是15
SO_SNDTIMEO不设置,write buffer满之后对端不消费,导致buffer一直满的情况
和上面ack超时有些许不一样的是,一个逻辑是用TCP_RTO_MIN通过tcp_retries2计算出来的时间。另一个是真的通过重传超过tcp_retries2次数来time_out,两者的区别和rto的动态计算有关。但是可以大致认为是一致的。
上述逻辑如下图所示:
write_timeout表格
| tcp_retries2 | buffer未满 | buffer满 |
|---|---|---|
| 5 | 立即返回 | min(SO_SNDTIMEO,(25.6s-51.2s)根据动态rto定 |
| 15 | 立即返回 | min(SO_SNDTIMEO,(924.6s-1044.6s)根据动态rto定 |
java的SocketOutputStream的sockWrite0超时时间
java的sockWrite0没有设置超时时间的地方,同时也没有设置过SO_SNDTIMEOUT,其直接调用了系统调用,所以其超时时间和write系统调用保持一致。
readTimeout
ReadTimeout可能是最容易导致问题的地方。我们先看下系统调用的源码:
read系统调用
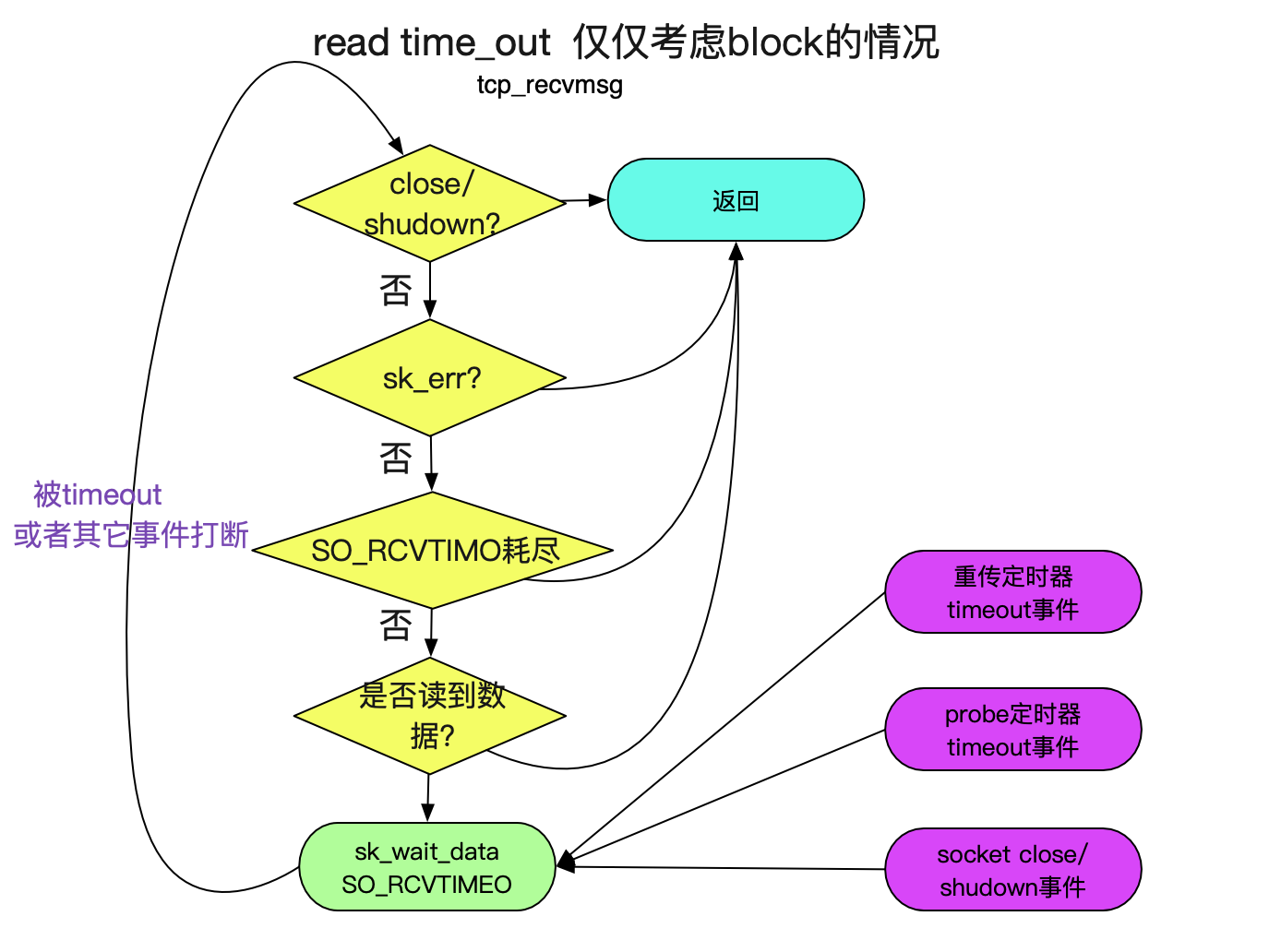
socket的read系统调用最终调用的是tcp_recvmsg, 其源码如下:
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
......
// 这边timeo=SO_RCVTIMEO
timeo = sock_rcvtimeo(sk, nonblock);
......
do{
......
// 下面这一堆判断表明,如果出现错误,或者已经被CLOSE/SHUTDOWN则跳出循环
if(copied) {
if (sk->sk_err ||
sk->sk_state == TCP_CLOSE ||
(sk->sk_shutdown & RCV_SHUTDOWN) ||
!timeo ||
signal_pending(current))
break;
} else {
if (sock_flag(sk, SOCK_DONE))
break;
if (sk->sk_err) {
copied = sock_error(sk);
break;
}
// 如果socket shudown跳出
if (sk->sk_shutdown & RCV_SHUTDOWN)
break;
// 如果socket close跳出
if (sk->sk_state == TCP_CLOSE) {
if (!sock_flag(sk, SOCK_DONE)) {
/* This occurs when user tries to read
* from never connected socket.
*/
copied = -ENOTCONN;
break;
}
break;
}
.......
}
.......
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else /* 如果没有读到target自己数(和水位有关,可以暂认为是1),则等待SO_RCVTIMEO的时间 */
sk_wait_data(sk, &timeo);
} while (len > 0);
......
}
上面的逻辑如下图所示:
重传以及探测定时器timeout事件的触发时机如下图所示:

如果内核层面ack正常返回而且对端窗口不为0,仅仅应用层不返回任何数据,那么就会无限等待,直到对端有数据或者socket close/shutdown为止,如下图所示:
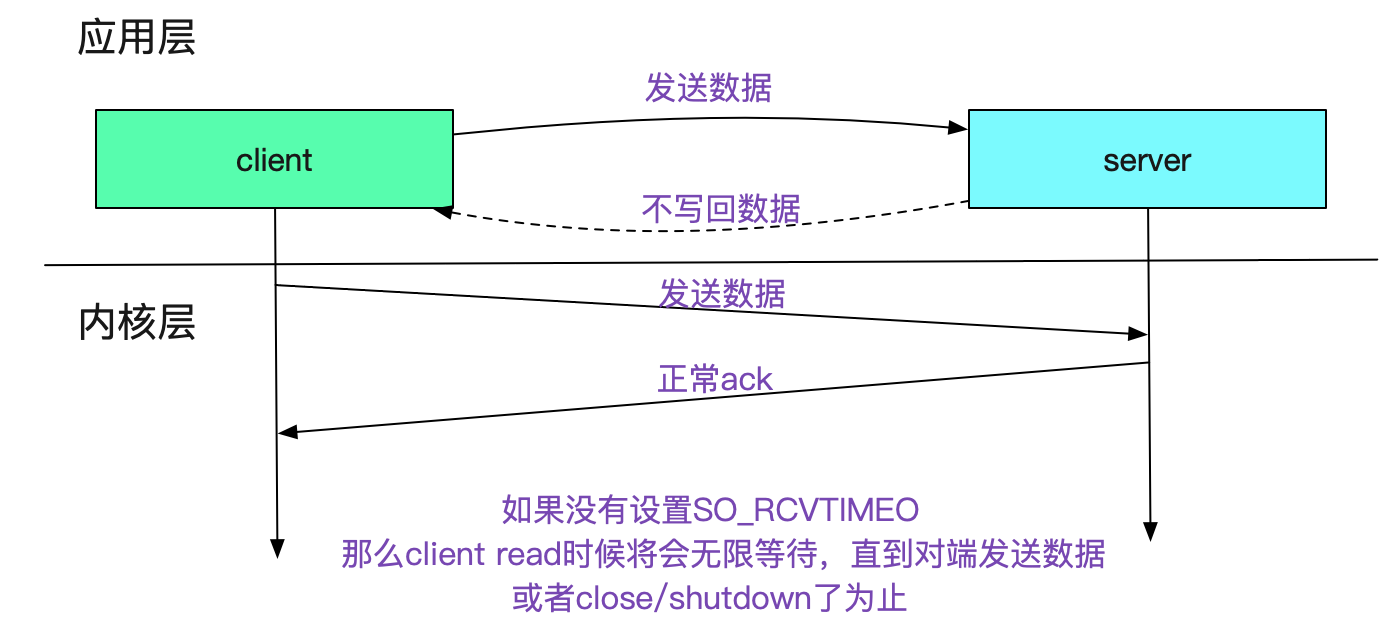
很多应用就是基于这个无限超时来设计的,例如activemq的消费者逻辑。
java的SocketInputStream的sockRead0超时时间
java的超时时间由SO_TIMOUT决定,而linux的socket并没有这个选项。其sockRead0和上面的java connect一样,在SO_TIMEOUT>0的时候依旧是由nonblock socket模拟,在此就不再赘述了。
ReadTimeout超时表格
C系统调用:
| tcp_retries2 | 对端无响应 | 对端内核响应正常 |
|---|---|---|
| 5 | min(SO_RCVTIMEO,(25.6s-51.2s)根据动态rto定 | SO_RCVTIMEO==0?无限,SO_RCVTIMEO) |
| 15 | min(SO_RCVTIMEO,(924.6s-1044.6s)根据动态rto定 | SO_RCVTIMEO==0?无限,SO_RCVTIMEO) |
Java系统调用
| tcp_retries2 | 对端无响应 | 对端内核响应正常 |
|---|---|---|
| 5 | min(SO_TIMEOUT,(25.6s-51.2s)根据动态rto定 | SO_TIMEOUT==0?无限,SO_RCVTIMEO |
| 15 | min(SO_TIMEOUT,(924.6s-1044.6s)根据动态rto定 | SO_TIMEOUT==0?无限,SO_RCVTIMEO |
对端物理机宕机之后的timeout
对端物理机宕机后还依旧有数据发送
对端物理机宕机时对端内核也gg了(不会发出任何包通知宕机),那么本端发送任何数据给对端都不会有响应。其超时时间就由上面讨论的
min(设置的socket超时[例如SO_TIMEOUT],内核内部的定时器超时来决定)。
对端物理机宕机后没有数据发送,但在read等待
这时候如果设置了超时时间timeout,则在timeout后返回。但是,如果仅仅是在read等待,由于底层没有数据交互,那么其无法知道对端是否宕机,所以会一直等待。但是,内核会在一个socket两个小时都没有数据交互情况下(可设置)启动keepalive定时器来探测对端的socket。如下图所示:

大概是2小时11分钟之后会超时返回。keepalive的设置由内核参数指定:
cat /proc/sys/net/ipv4/tcp_keepalive_time 7200 即两个小时后开始探测
cat /proc/sys/net/ipv4/tcp_keepalive_intvl 75 即每次探测间隔为75s
cat /proc/sys/net/ipv4/tcp_keepalve_probes 9 即一共探测9次
可以在setsockops中对单独的socket指定是否启用keepalive定时器(java也可以)。
对端物理机宕机后没有数据发送,也没有read等待
和上面同理,也是在keepalive定时器超时之后,将连接close。所以我们可以看到一个不活跃的socket在对端物理机突然宕机之后,依旧是ESTABLISHED状态,过很长一段时间之后才会关闭。
进程宕后的超时
如果仅仅是对端进程宕机的话(进程所在内核会close其所拥有的所有socket),由于fin包的发送,本端内核可以立刻知道当前socket的状态。如果socket是阻塞的,那么将会在当前或者下一次write/read系统调用的时候返回给应用层相应的错误。如果是nonblock,那么会在select/epoll中触发出对应的事件通知应用层去处理。
如果fin包没发送到对端,那么在下一次write/read的时候内核会发送reset包作为回应。
nonblock
设置为nonblock=true后,由于read/write都是立刻返回,且通过select/epoll等处理重传超时/probe超时/keep alive超时/socket close等事件,所以根据应用层代码决定其超时特性。定时器超时事件发生的时间如上面几小节所述,和是否nonblock无关。nonblock的编程模式可以让应用层对这些事件做出响应。
总结
网络编程中超时时间是个重要但又容易被忽略的问题,这个问题只有在遇到物理机宕机等平时遇不到的现象时候才会凸显。笔者在经历数次物理机宕机之后才好好的研究了一番,希望本篇文章可以对读者在以后遇到类似超时问题时有所帮助。
公众号
关注笔者公众号,获取更多干货文章:
