《算法导论》读书笔记之第10章 基本数据结构
摘要
本章介绍了几种基本的数据结构,包括栈、队列、链表以及有根树,讨论了使用指针的简单数据结构来表示动态集合。本章的内容对于学过数据结构的人来说,没有什么难处,简单的总结一下。
1、栈和队列
栈和队列都是动态集合,元素的出入是规定好的。栈规定元素是先进后出(FILO),队列规定元素是先进先出(FIFO)。栈和队列的实现可以采用数组和链表进行实现。在标准模块库STL中有具体的应用,可以参考http://www.cplusplus.com/reference/。
栈的基本操作包括入栈push和出栈pop,栈有一个栈顶指针top,指向最新如栈的元素,入栈和出栈操作操作都是从栈顶端进行的。
队列的基本操作包括入队enqueue和出队dequeue,队列有队头head和队尾tail指针。元素总是从队头出,从队尾入。采用数组实现队列时候,为了合理利用空间,可以采用循环实现队列空间的有效利用。
关于栈和队列的基本操作如下图所示:
采用数组简单实现一下栈和队列,实现队列时候,长度为n的数组最多可以含有n-1个元素,循环利用,这样方便判断队列是空还是满。程序如下所示:
1 //stack.c
2
3 #include <stdio.h>
4 #include <stdlib.h>
5
6 typedef struct stack
7 {
8 int *s;
9 int stacksize;
10 int top;
11 }stack;
12
13 void init_stack(stack*s)
14 {
15 s->stacksize = 100;
16 s->s =(int*)malloc(sizeof(int)*s->stacksize);
17 s->top = -1;
18 }
19 int stack_empty(stack s)
20 {
21 return ((0 == s.stacksize) ? 1 : 0);
22 }
23
24 void push(stack *s,int x)
25 {
26 if(s->top == s->stacksize)
27 printf("up to overflow.
");
28 else
29 {
30 s->top++;
31 s->s[s->top] = x;
32 s->stacksize++;
33 }
34 }
35 void pop(stack *s)
36 {
37 if(0 == s->stacksize)
38 printf("down to overflow.
");
39 else
40 {
41 s->top--;
42 s->stacksize--;
43 }
44 }
45 int top(stack s)
46 {
47 return s.s[s.top];
48 }
49
50 int main()
51 {
52 stack s;
53 init_stack(&s);
54 push(&s,19);
55 push(&s,23);
56 push(&s,34);
57 push(&s,76);
58 push(&s,65);
59 printf("top is:%d
",top(s));
60 pop(&s);
61 printf("top is:%d
",top(s));
62 }
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 typedef struct queue
5 {
6 int *q;
7 int queuesize;
8 int head;
9 int tail;
10 }queue;
11
12 void enqueue(queue* q,int x)
13 {
14 if(((q->tail+1) % q->queuesize) == q->head)
15 {
16 printf("queue is full.
");
17 }
18 else
19 {
20 q->q[q->tail] = x;
21 q->tail = (q->tail+1) % q->queuesize;
22 }
23 }
24
25 int dequeue(queue* q,int *value)
26 {
27 if(q->tail == q->head)
28 return -1;
29 else
30 {
31 *value = q->q[q->head];
32 q->head = ((q->head++) % q->queuesize);
33 }
34 }
35 int main()
36 {
37
38 int value;
39 queue q;
40 q.queuesize=10;
41 q.q = (int*)malloc(sizeof(int)*q.queuesize);
42 q.head=0;
43 q.tail=0;
44 enqueue(&q,10);
45 enqueue(&q,30);
46 printf("head=%d tail=%d
",q.head,q.tail);
47 if(dequeue(&q,&value) == -1)
48 printf("queue is empty.
");
49 else
50 printf("value=%d
",value);
51 if(dequeue(&q,&value) == -1)
52 printf("queue is empty.
");
53 else
54 printf("value=%d
",value);
55 if(dequeue(&q,&value) == -1)
56 printf("queue is empty.
");
57 else
58 printf("value=%d
",value);
59 printf("head=%d tail=%d
",q.head,q.tail);
60 enqueue(&q,10);
61 exit(0);
62 }
测试结果如下所示:


问题:
(1)说明如何用两个栈实现一个队列,并分析有关队列操作的运行时间。
解答:栈中的元素是先进后出,而队列中的元素是先进先出。现有栈s1和s2,s1中存放队列中的结果,s2辅助转换s1为队列。入队列操操作:当一个元素入队列时,先判断s1是否为空,如果为空则新元素直接入s1,如果非空则将s1中所有元素出栈并存放到s2中,然后在将元素入s1中,最后将s2中所有元素出栈并入s1中。此时s1中存放的即是队列入队的顺序。出队操作:如果s1为空,则说明队列为空,非空则s1出栈即可。入队过程需要在s1和s2来回交换,运行时间为O(n),出队操作直接是s1出栈运行时间为O(1)。举例说明转换过程,如下图示:
我采用C++语言实现整程序如下:
1 #include <iostream>
2 #include <stack>
3 #include <cstdlib>
4 using namespace std;
5
6 template <class T>
7 class MyQueue
8 {
9 public:
10 MyQueue();
11 ~MyQueue();
12 void enqueue(const T& data);
13 int queue_empty() const;
14 T dequeue();
15 private:
16 stack<T>s1;
17 stack<T>s2;
18 };
19
20 template<class T>
21 MyQueue<T>::MyQueue()
22 {
23
24 }
25 template<class T>
26 MyQueue<T>::~MyQueue()
27 {
28
29 }
30 template<class T>
31 void MyQueue<T>::enqueue(const T& data)
32 {
33 if(s1.empty())
34 s1.push(data);
35 else
36 {
37 while(!s1.empty(d))
38 {
39 s2.push(s1.top());
40 s1.pop();
41 }
42 s1.push(data);
43 }
44 while(!s2.empty())
45 {
46 s1.push(s2.top());
47 s2.pop();
48 }
49 }
50 template<class T>
51 int MyQueue<T>::queue_empty() const
52 {
53 return (s1.empty());
54 }
55 template<class T>
56 T MyQueue<T>::dequeue()
57 {
58 T ret;
59 if(!s1.empty())
60 {
61 ret = s1.top();
62 s1.pop();
63 }
64 return ret;
65
66 }
67
68 int main()
69 {
70 MyQueue<int> myqueue;
71 myqueue.enqueue(10);
72 myqueue.enqueue(20);
73 myqueue.enqueue(30);
74 cout<< myqueue.dequeue()<<endl;
75 myqueue.enqueue(40);
76 cout<< myqueue.dequeue()<<endl;
77 cout<< myqueue.dequeue()<<endl;
78 myqueue.enqueue(50);
79 cout<< myqueue.dequeue()<<endl;
80 cout<< myqueue.dequeue()<<endl;
81 exit(0);
82 }
(2)说明如何用两个队列实现一个栈,并分析有关栈操作的运行时间。
解答:类似上面的题目,队列是先进先出,而栈是先进后出。现有队列q1和q2,q1中存放的是栈的结果,q2辅助q1转换为栈。入栈操作:当一个元素如栈时,先判断q1是否为空,如果为空则该元素之间入队列q1,如果非空则将q1中的所有元素出队并入到q2中,然后将该元素入q1中,最后将q2中所有元素出队并入q1中。此时q1中存放的就是栈的如栈顺序。出栈操作:如果q1为空,则栈为空,否则直接q1出队操作。入栈操作需要在队列q1和q2直接来来回交换,运行时间为O(n),出栈操作是队列q1出队操作,运行时间为O(1)。我用C++语言实现完整程序如下:
1 #include <iostream>
2 #include <stack>
3 #include <cstdlib>
4 using namespace std;
5
6 template <class T>
7 class MyQueue
8 {
9 public:
10 MyQueue();
11 ~MyQueue();
12 void enqueue(const T& data);
13 int queue_empty() const;
14 T dequeue();
15 private:
16 stack<T>s1;
17 stack<T>s2;
18 };
19
20 template<class T>
21 MyQueue<T>::MyQueue()
22 {
23
24 }
25 template<class T>
26 MyQueue<T>::~MyQueue()
27 {
28
29 }
30 template<class T>
31 void MyQueue<T>::enqueue(const T& data)
32 {
33 if(s1.empty())
34 s1.push(data);
35 else
36 {
37 while(!s1.empty(d))
38 {
39 s2.push(s1.top());
40 s1.pop();
41 }
42 s1.push(data);
43 }
44 while(!s2.empty())
45 {
46 s1.push(s2.top());
47 s2.pop();
48 }
49 }
50 template<class T>
51 int MyQueue<T>::queue_empty() const
52 {
53 return (s1.empty());
54 }
55 template<class T>
56 T MyQueue<T>::dequeue()
57 {
58 T ret;
59 if(!s1.empty())
60 {
61 ret = s1.top();
62 s1.pop();
63 }
64 return ret;
65
66 }
67
68 int main()
69 {
70 MyQueue<int> myqueue;
71 myqueue.enqueue(10);
72 myqueue.enqueue(20);
73 myqueue.enqueue(30);
74 cout<< myqueue.dequeue()<<endl;
75 myqueue.enqueue(40);
76 cout<< myqueue.dequeue()<<endl;
77 cout<< myqueue.dequeue()<<endl;
78 myqueue.enqueue(50);
79 cout<< myqueue.dequeue()<<endl;
80 cout<< myqueue.dequeue()<<endl;
81 exit(0);
82 }
2、链表
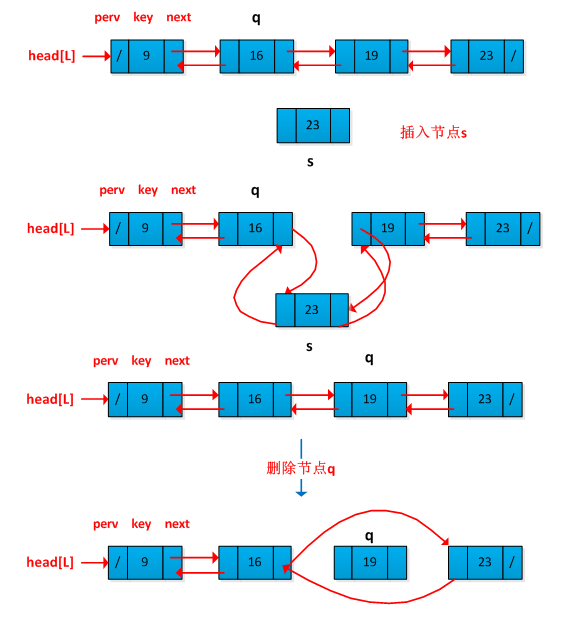
链表与数组的区别是链表中的元素顺序是有各对象中的指针决定的,相邻元素之间在物理内存上不一定相邻。采用链表可以灵活地表示动态集合。链表有单链表和双链表及循环链表。书中着重介绍了双链表的概念及操作,双链表L的每一个元素是一个对象,每个对象包含一个关键字和两个指针:next和prev。链表的操作包括插入一个节点、删除一个节点和查找一个节点,重点来说一下双向链表的插入和删除节点操作,图例如下:
链表是最基本的数据结构,凡是学计算机的必须的掌握的,在面试的时候经常被问到,关于链表的实现,百度一下就知道了。在此可以讨论一下与链表相关的练习题。
(1)在单链表上插入一个元素,要求时间复杂度为O(1)。
解答:一般情况在链表中插入一元素是在末尾插入的,这样需要从头遍历一次链表,找到末尾,时间为O(n)。要在O(1)时间插入一个新节点,可以考虑每次在头节点后面插入,即每次插入的节点成为链表的第一个节点。
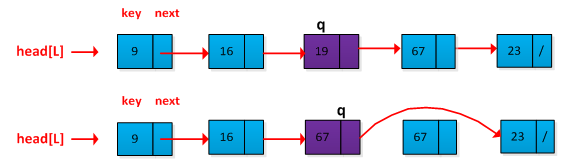
(2)在单链表上删除一个给定的节点p,要求时间复杂度为O(1)。
解答:一般情况删除一个节点时候,我们需要找到该节点p的前驱节点q,需要对链表进行遍历,运行时间为O(n-1)。我们可以考虑先将q的后继节点s的值替换q节点值,然后删除s即可。如下图删除节点q的操作过程:
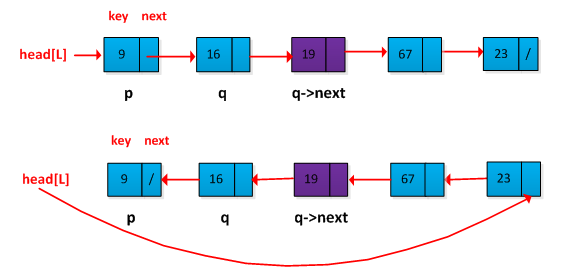
(3)单链表逆置,不允许额外分配存储空间,不允许递归,可以使用临时变量,执行时间为O(n)。
解答:这个题目在面试笔试中经常碰到,基本思想上将指针逆置。如下图所示:
(4)遍历单链表一次,找出链表中间节点。
解答:定义两个指针p和q,初始都指向链表头节点。然后开始向后遍历,p每次移动2步,q移动一步,当p到达末尾的时候,p正好到达了中间位置。
(5)用一个单链表L实现一个栈,要求push和pop的操作时间为O(1)。
解答:根据栈中元素先进后出的特点,可以在链表的头部进行插入和删除操作。
(6)用一个单链表L实现一个队列,要求enqueue和dequeue的操作时间为O(1)。
解答:队列中的元素是先进先出,在单链表结构中增加一个尾指针,数据从尾部插入,从头部删除。
3、有根树的表示
采用链表数据结构来表示树,书中先降二叉树的链表表示法,然后拓展到分支数无限制的有根数。先来看看二叉树的链表表示方法,用域p、left和right来存储指向二叉树T中的父亲、左孩子和右孩子的指针。如下图所示:

对于分支数目无限制的有根树,采用左孩子、右兄弟的表示方法。这样表示的树的每个节点都包含有一个父亲指针p,另外两个指针:
(1)left_child指向节点的最左孩子。
(2)right_sibling指向节点紧右边的兄弟。
《算法导论》读书笔记之第10章 基本数据结构之二叉树
摘要
书中第10章10.4小节介绍了有根树,简单介绍了二叉树和分支数目无限制的有根树的存储结构,而没有关于二叉树的遍历过程。为此对二叉树做个简单的总结,介绍一下二叉树基本概念、性质、二叉树的存储结构和遍历过程,主要包括先根遍历、中根遍历、后根遍历和层次遍历。
1、二叉树的定义
二叉树(Binary Tree)是一种特殊的树型结构,每个节点至多有两棵子树,且二叉树的子树有左右之分,次序不能颠倒。
由定义可知,二叉树中不存在度(结点拥有的子树数目)大于2的节点。二叉树形状如下下图所示:
2、二叉树的性质
(1)在二叉树中的第i层上至多有2^(i-1)个结点(i>=1)。备注:^表示此方
(2)深度为k的二叉树至多有2^k-1个节点(k>=1)。
(3)对任何一棵二叉树T,如果其终端结点数目为n0,度为2的节点数目为n2,则n0=n2+1。
满二叉树:深度为k且具有2^k-1个结点的二叉树。即满二叉树中的每一层上的结点数都是最大的结点数。
完全二叉树:深度为k具有n个结点的二叉树,当且仅当每一个结点与深度为k的满二叉树中的编号从1至n的结点一一对应。
可以得到一般结论:满二叉树和完全二叉树是两种特殊形态的二叉树,满二叉树肯定是完全二叉树,但完全二叉树不不一定是满二叉树。
举例如下图是所示:

(4)具有n个节点的完全二叉树的深度为log2n + 1。
3、二叉树的存储结构
可以采用顺序存储数组和链式存储二叉链表两种方法来存储二叉树。经常使用的二叉链表方法,因为其非常灵活,方便二叉树的操作。二叉树的二叉链表存储结构如下所示:

1 typedef struct binary_tree_node
2 {
3 int elem;
4 struct binary_tree_node *left;
5 struct binary_tree_node *right;
6 }binary_tree_node,*binary_tree;
举例说明二叉链表存储过程,如下图所示:

从图中可以看出:在还有n个结点的二叉链表中有n+1个空链域。
4、遍历二叉树
遍历二叉树是按照指定的路径方式访问书中每个结点一次,且仅访问一次。由二叉树的定义,我们知道二叉数是由根结点、左子树和右子树三部分构成的。通常遍历二叉树是从左向右进行,因此可以得到如下最基本的三种遍历方法:
(1)先根遍历(先序遍历):如果二叉树为空,进行空操作;否则,先访问根节点,然后先根遍历左子树,最后先根遍历右子树。采用递归形式实现代码如下:
1 void preorder_traverse_recursive(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 printf("%d ",root->elem);
6 preorder_traverse_recursive(root->left);
7 preorder_traverse_recursive(root->right);
8 }
9 }
具体过程如下图所示:

(2)中根遍历(中序遍历):如果二叉树为空,进行空操作;否则,先中根遍历左子树,然后访问根结点,最后中根遍历右子树。递归过程实现代码如下:
1 void inorder_traverse_recursive(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 inorder_traverse_recursive(root->left);
6 printf("%d ",root->elem);
7 inorder_traverse_recursive(root->right);
8 }
9 }
具体过程如下图所示:

(3)后根遍历(后序遍历):如果二叉树为空,进行空操作;否则,先后根遍历左子树,然后后根遍历右子树,最后访问根结点。递归实现代码如下:
1 void postorder_traverse_recursive(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 postorder_traverse_recursive(root->left);
6 postorder_traverse_recursive(root->right);
7 printf("%d ",root->elem);
8 }
9 }
具体过程如下图所示:

写一个完整的程序练习二叉树的三种遍历,采用递归形式创建二叉树,然后以递归的形式遍历二叉树,后面会接着讨论如何使用非递归形式实现这三种遍历,程序采用C语言实现,完整程序如下:
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 //the structure of binary tree
5 typedef struct binary_tree_node
6 {
7 int elem;
8 struct binary_tree_node *left;
9 struct binary_tree_node *right;
10 }binary_tree_node,*binary_tree;
11
12 void init_binary_tree(binary_tree *root);
13 void create_binary_tree(binary_tree *root);
14
15 //previous root
16 void preorder_traverse_recursive(binary_tree root);
17 //inorder root
18 void inorder_traverse_recursive(binary_tree root);
19 //post order root
20 void postorder_traverse_recursive(binary_tree root);
21
22 int main()
23 {
24 binary_tree root;
25 init_binary_tree(&root);
26 create_binary_tree(&root);
27 preorder_traverse_recursive(root);
28 inorder_traverse_recursive(root);
29 postorder_traverse_recursive(root);
30 exit(0);
31 }
32
33 void init_binary_tree(binary_tree *root)
34 {
35 *root = NULL;
36 }
37
38 void create_binary_tree(binary_tree* root)
39 {
40 int elem;
41 printf("Enter the node value(0 is end): ");
42 scanf("%d",&elem);
43 if(elem == 0)
44 *root = NULL;
45 else
46 {
47 *root = (binary_tree)malloc(sizeof(binary_tree_node));
48 if(NULL == root)
49 {
50 printf("malloc error.
");
51 exit(-1);
52 }
53 (*root)->elem = elem;
54 printf("Creating the left child node.
");
55 create_binary_tree(&((*root)->left));
56 printf("Createing the right child node.
");
57 create_binary_tree(&((*root)->right));
58 }
59 }
60
61 void preorder_traverse_recursive(binary_tree root)
62 {
63 if(NULL != root)
64 {
65 printf("%d ",root->elem);
66 preorder_traverse_recursive(root->left);
67 preorder_traverse_recursive(root->right);
68 }
69 }
70
71 void inorder_traverse_recursive(binary_tree root)
72 {
73 if(NULL != root)
74 {
75 inorder_traverse_recursive(root->left);
76 printf("%d ",root->elem);
77 inorder_traverse_recursive(root->right);
78 }
79 }
80
81 void postorder_traverse_recursive(binary_tree root)
82 {
83 if(NULL != root)
84 {
85 postorder_traverse_recursive(root->left);
86 postorder_traverse_recursive(root->right);
87 printf("%d ",root->elem);
88 }
89 }
程序测试结果如下:

现在来讨论一下如何采用非递归实现这以上三种遍历。将递归形式转换为非递归形式,引入了额外的辅助结构栈。另外在讨论一次二叉树的层次遍历,可以借助队列进行实现。具体讨论如下:
(1)先根遍历非递归实现
先根遍历要求顺序是根左右,可以借助栈s来实现。先将根root入栈,然后循环判断s是否为空,非空则将结点出栈,记为节点p,然后依次先将结点p的右子树结点入栈,然后将结点p的左子树结点入栈,循环操作直到栈中所有元素都出栈为止,出栈顺序即是先根遍历的结果。采用C++中模板库stack实现先根遍历如下:
1 void preorder_traverse(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 stack<binary_tree_node*> s;
6 binary_tree_node *ptmpnode;
7 s.push(root);
8 while(!s.empty())
9 {
10 ptmpnode = s.top();
11 cout<<ptmpnode->elem<<" ";
12 s.pop();
13 if(NULL != ptmpnode->right)
14 s.push(ptmpnode->right);
15 if(NULL != ptmpnode->left)
16 s.push(ptmpnode->left);
17
18 }
19 }
20 }
(2)中根遍历非递归实现
中根遍历要求顺序是左根右,借助栈s实现。先将根root入栈,接着从根root开始查找最左的子孩子结点直到为空为止,然后将空节点出栈,再将左子树节点出栈遍历,然后判断该左子树的右子树节点入栈。循环此过程,直到栈为空为止。此时需要注意的是入栈过程中空结点也入栈了,用以判断左孩子是否结束和左孩子是否有右孩子结点。采用C++中模板库stack实现先根遍历如下:
1 void inorder_traverse(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 stack<binary_tree_node*> s;
6 binary_tree_node *ptmpnode;
7 s.push(root);
8 while(!s.empty())
9 {
10 ptmpnode = s.top();
11 while(NULL != ptmpnode)
12 {
13 s.push(ptmpnode->left);
14 ptmpnode = s.top();
15 }
16 s.pop();//空结点出栈
17 if(!s.empty())
18 {
19 ptmpnode = s.top();
20 cout<<ptmpnode->elem<<" ";
21 s.pop();
22 //右子树结点如栈
23 s.push(ptmpnode->right);
24 }
25 }
26 }
27 }
另外一种简洁的实现方法如下:
1 void inorder_traverse_two(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 stack<binary_tree_node*> s;
6 binary_tree_node *ptmpnode;
7 ptmpnode = root;
8 while(NULL != ptmpnode || !s.empty())
9 {
10 //将左子树结点入栈
11 if(NULL != ptmpnode)
12 {
13 s.push(ptmpnode);
14 ptmpnode = ptmpnode->left;
15 }
16 else
17 {
18 //出栈遍历
19 ptmpnode = s.top();
20 s.pop();
21 cout<<ptmpnode->elem<<" ";
22 //右子树结点
23 ptmpnode = ptmpnode->right;
24 }
25 }
26 }
27 }
(3)后根遍历递归实现
后根遍历要求访问顺序是左右根,采用辅助栈实现时,需要一个标记,判断结点是否访问了,因为右子树是通过跟结点的信息得到的。实现过程是先将根结点及其左子树入栈,并初始标记为0,表示没有访问,然后通过判断栈是否为空和标记的值是否为1来判断是否访问元素。
参考:http://www.cnblogs.com/hicjiajia/archive/2010/08/27/1810055.html
采用C++模板库stack具体实现程序如下:
1 void postorder_traverse(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 stack<binary_tree_node*> s;
6 binary_tree_node *ptmpnode;
7 int flags[100];
8 ptmpnode = root;
9 while(NULL != ptmpnode || !s.empty())
10 {
11 //将结点左子树结点入栈
12 while(NULL != ptmpnode)
13 {
14 s.push(ptmpnode);
15 flags[s.size()] = 0; //标记未访问
16 ptmpnode=ptmpnode->left;
17 }
18 //输出访问的结点
19 while(!s.empty() && flags[s.size()] == 1)
20 {
21 ptmpnode = s.top();
22 s.pop();
23 cout<<ptmpnode->elem<<" ";
24 }
25 //从右子树开始遍历
26 if(!s.empty())
27 {
28 ptmpnode = s.top();
29 flags[s.size()] = 1; //登记访问了
30 ptmpnode = ptmpnode->right;
31 }
32 else
33 break;
34 }
35 }
36 }
(4)层次遍历实现
层次遍历要求从根向下、从左向右进行访问,可以采用队列实现。先将根入队,然后队列进程出队操作访问结点p,再将结点p的左子树和右子树结点入队,循环执行此过程直到队列为空。出队顺序即是层次遍历结果。采用C++的模板库queue实现如下:
1 void levelorder_traverse(binary_tree root)
2 {
3 if(NULL != root)
4 {
5 queue<binary_tree_node*> q;
6 binary_tree_node *ptmpnode;
7 q.push(root);
8 while(!q.empty())
9 {
10 ptmpnode = q.front();
11 q.pop();
12 cout<<ptmpnode->elem<<" ";
13 if(NULL != ptmpnode->left)
14 q.push(ptmpnode->left);
15 if(NULL != ptmpnode->right)
16 q.push(ptmpnode->right);
17 }
18 }
19 }
综合上面的分析过程写个完整的程序测试二叉树遍历的非递归实现,采用C++语言,借助stack和queue实现,完整程序如下所示:
1 #include <iostream>
2 #include <stack>
3 #include <queue>
4 #include <cstdlib>
5 using namespace std;
6
7 typedef struct binary_tree_node
8 {
9 int elem;
10 struct binary_tree_node *left;
11 struct binary_tree_node *right;
12 }binary_tree_node,*binary_tree;
13
14 void init_binary_tree(binary_tree *root);
15 void create_binary_tree(binary_tree *root);
16 void preorder_traverse(binary_tree root);
17 void inorder_traverse(binary_tree root);
18 void inorder_traverse_two(binary_tree root);
19 void postorder_traverse(binary_tree root);
20 void levelorder_traverse(binary_tree root);
21
22 int main()
23 {
24 binary_tree root;
25 create_binary_tree(&root);
26 cout<<"preodrer traverse: ";
27 preorder_traverse(root);
28 cout<<"
inodrer traverse: ";
29 inorder_traverse_two(root);
30 cout<<"
postodrer traverse: ";
31 postorder_traverse(root);
32 cout<<"
leverorder traverse: ";
33 levelorder_traverse(root);
34 exit(0);
35 }
36
37 void init_binary_tree(binary_tree *root)
38 {
39 *root = NULL;
40 }
41
42 void create_binary_tree(binary_tree* root)
43 {
44 int elem;
45 cout<<"Enter the node value(0 is end): ";
46 cin>>elem;
47 if(elem == 0)
48 *root = NULL;
49 else
50 {
51 *root = (binary_tree)malloc(sizeof(binary_tree_node));
52 if(NULL == root)
53 {
54 cout<<"malloc error.
";
55 exit(-1);
56 }
57 (*root)->elem = elem;
58 cout<<"Creating the left child node.
";
59 create_binary_tree(&((*root)->left));
60 cout<<"Createing the right child node.
";
61 create_binary_tree(&((*root)->right));
62 }
63 }
64
65 void preorder_traverse(binary_tree root)
66 {
67 if(NULL != root)
68 {
69 stack<binary_tree_node*> s;
70 binary_tree_node *ptmpnode;
71 s.push(root);
72 while(!s.empty())
73 {
74 ptmpnode = s.top();
75 cout<<ptmpnode->elem<<" ";
76 s.pop();
77 if(NULL != ptmpnode->right)
78 s.push(ptmpnode->right);
79 if(NULL != ptmpnode->left)
80 s.push(ptmpnode->left);
81
82 }
83 }
84 }
85 void inorder_traverse(binary_tree root)
86 {
87 if(NULL != root)
88 {
89 stack<binary_tree_node*> s;
90 binary_tree_node *ptmpnode;
91 s.push(root);
92 while(!s.empty())
93 {
94 ptmpnode = s.top();
95 while(NULL != ptmpnode)
96 {
97 s.push(ptmpnode->left);
98 ptmpnode = s.top();
99 }
100 s.pop();
101 if(!s.empty())
102 {
103 ptmpnode = s.top();
104 cout<<ptmpnode->elem<<" ";
105 s.pop();
106 s.push(ptmpnode->right);
107 }
108 }
109 }
110 }
111
112 void inorder_traverse_two(binary_tree root)
113 {
114 if(NULL != root)
115 {
116 stack<binary_tree_node*> s;
117 binary_tree_node *ptmpnode;
118 ptmpnode = root;
119 while(NULL != ptmpnode || !s.empty())
120 {
121 //将左子树结点入栈
122 if(NULL != ptmpnode)
123 {
124 s.push(ptmpnode);
125 ptmpnode = ptmpnode->left;
126 }
127 else
128 {
129 //出栈遍历
130 ptmpnode = s.top();
131 s.pop();
132 cout<<ptmpnode->elem<<" ";
133 //右子树结点
134 ptmpnode = ptmpnode->right;
135 }
136 }
137 }
138 }
139
140 void postorder_traverse(binary_tree root)
141 {
142 if(NULL != root)
143 {
144 stack<binary_tree_node*> s;
145 binary_tree_node *ptmpnode;
146 int flags[100];
147 ptmpnode = root;
148 while(NULL != ptmpnode || !s.empty())
149 {
150 //将结点左子树结点入栈
151 while(NULL != ptmpnode)
152 {
153 s.push(ptmpnode);
154 flags[s.size()] = 0; //标记未访问
155 ptmpnode=ptmpnode->left;
156 }
157 //输出访问的结点
158 while(!s.empty() && flags[s.size()] == 1)
159 {
160 ptmpnode = s.top();
161 s.pop();
162 cout<<ptmpnode->elem<<" ";
163 }
164 //从右子树开始遍历
165 if(!s.empty())
166 {
167 ptmpnode = s.top();
168 flags[s.size()] = 1; //登记访问了
169 ptmpnode = ptmpnode->right;
170 }
171 else
172 break;
173 }
174 }
175 }
176 void levelorder_traverse(binary_tree root)
177 {
178 if(NULL != root)
179 {
180 queue<binary_tree_node*> q;
181 binary_tree_node *ptmpnode;
182 q.push(root);
183 while(!q.empty())
184 {
185 ptmpnode = q.front();
186 q.pop();
187 cout<<ptmpnode->elem<<" ";
188 if(NULL != ptmpnode->left)
189 q.push(ptmpnode->left);
190 if(NULL != ptmpnode->right)
191 q.push(ptmpnode->right);
192 }
193 }
194 }
程序测试结果如下:

二叉树后序遍历(非递归)
二叉树的递归遍历算法就不用说了;在非递归算法中,后序遍历难度大,很多书上只给出思想或者几段无法直接调试的代码,甚至有些书上是错的,当时我在研究的过程中,就是按着书上错误的代码绕了好半天,几预抓狂。好在最终摸索出来了,不禁感叹很多出书人的水平真是...... 这里将直接可以在编译器里调试的代码贴出来(在DEV-C++编译器中编译通过)

这里我们约定:空的节点用空格表示,按照前序遍历来创建树!
1 // main.cpp
3 using namespace std;
4 typedef struct node {
5 char data;
6 struct node *lchild;
7 struct node *rchild;
8 }BiNode,*BiTree;
9 typedef struct node1{
10 BiTree data[30]; //默认30个元素 ,这里需要一个辅助堆栈!!!
11 int top;
12 }Stack;
13
14 void createTree(BiTree &T) //先序递归创建树,这里注意参数的类型,T的类型是 "*&" ,如果是 "**" 代码稍加改动就OK...
15 {
16 char ch;
17 cin.get(ch).get(); //过滤输入流中每次回车产生的回车符
18 if (ch==' ') T=NULL; //这里首先判断是不是空格,如果是,则为该节点赋NULL
19 else{
20 T=(BiTree)malloc(sizeof(BiNode));
21 T->data=ch;
22 createTree(T->lchild);
23 createTree(T->rchild);
24 }
25 }
26 void initstack(Stack *&st)
27 {
28 st=(Stack *)malloc(sizeof(Stack));
29 st->top=-1;
30 }
31 bool isempty(Stack *st)
32 {
33 return st->top==-1;
34 }
35 bool isfull(Stack *st)
36 {
37 return st->top==19;
38 }
39 void push(Stack *st,BiTree T)
40 {
41 if (!isfull(st))
42 st->data[++st->top]=T; //栈顶指针始终指向堆栈最上面可用的一个元素,因此入栈时候,先要将指针加1,然后再执行入栈操作! 43 else cout<<"已满"<<endl; 44 } 45 BiTree pop(Stack *st) 46 { 47 if (!isempty(st)) return st->data[st->top--]; 48 } 49 BiTree gettop(Stack *st) 50 { 51 if (!isempty(st)) return st->data[st->top]; //出栈时,先取出栈顶指针指向的元素,然后再将指针减1,使其指向栈中下一个可用元素! 52 } 53 void preOrderNoRe(BiTree T) // 前序遍历 54 { 55 Stack *st; 56 initstack(st); 57 BiTree p; 58 p=T; 59 while (p!=NULL||!isempty(st)) 60 { 61 while (p!=NULL) 62 { 63 cout<<p->data<<" "; 64 push(st,p); 65 p=p->lchild; 66 } 67 if (!isempty(st)) 68 { 69 p=pop(st); 70 p=p->rchild; 71 } 72 73 } 74 } 75 void inOrderNoRe(BiTree T) //中序遍历 76 { 77 Stack *st; 78 initstack(st); 79 BiTree p; 80 p=T; 81 while (p!=NULL||!isempty(st)) 82 { 83 while (p!=NULL) 84 { 85 push(st,p); 86 p=p->lchild; 87 } 88 if (!isempty(st)) 89 { 90 p=pop(st); 91 cout<<p->data<<" "; 92 p=p->rchild; 93 } 94 95 } 96 } 97 void postOrderNoRe(BiTree T) //后序遍历 98 { 99 BiTree p;100 Stack *st;101 initstack(st);102 p=T;103 int Tag[20]; //栈,用于标识从左(0)或右(1)返回 104 while (p!=NULL || !isempty(st))105 {106 while (p!=NULL)107 {108 push(st,p);109 Tag[st->top]=0;110 p=p->lchild;111 }112 while (!isempty(st)&&Tag[st->top]==1)113 {114 p=pop(st);115 cout<<p->data<<" ";116 }117 if (!isempty(st))118 {119 Tag[st->top]=1; //设置标记右子树已经访问 120 p=gettop(st);121 p=p->rchild;122 }123 else break;124 }125 }126 int main()127 {128 cout<<"Enter char one by one hicjiajia"<<endl;129 BiNode *T;130 createTree(T);131 cout<<endl;132 133 cout<<"preOrderNoRe: ";preOrderNoRe(T);cout<<endl;134 cout<<"inOrderNoRe: ";inOrderNoRe(T);cout<<endl;135 cout<<"postOrderNoRe: ";postOrderNoRe(T);cout<<endl; 136 system("pause");137 return 0;138 }
运行结果如图:

《算法导论》读书笔记之第11章 散列表
摘要:
本章介绍了散列表(hash table)的概念、散列函数的设计及散列冲突的处理。散列表类似与字典的目录,查找的元素都有一个key与之对应,在实践当中,散列技术的效率是很高的,合理的设计散函数和冲突处理方法,可以使得在散列表中查找一个元素的期望时间为O(1)。散列表是普通数组概念的推广,在散列表中,不是直接把关键字用作数组下标,而是根据关键字通过散列函数计算出来的。书中介绍散列表非常注重推理和证明,看的时候迷迷糊糊的,再次证明了数学真的很重要。在STL中map容器的功能就是散列表的功能,但是map采用的是红黑树实现的,后面接着学习,关于map的操作可以参考:http://www.cplusplus.com/reference/map/。
1、直接寻址表
当关键字的的全域(范围)U比较小的时,直接寻址是简单有效的技术,一般可以采用数组实现直接寻址表,数组下标对应的就是关键字的值,即具有关键字k的元素被放在直接寻址表的槽k中。直接寻址表的字典操作实现比较简单,直接操作数组即可以,只需O(1)的时间。
2、散列表
直接寻址表的不足之处在于当关键字的范围U很大时,在计算机内存容量的限制下,构造一个存储|U|大小的表不太实际。当存储在字典中的关键字集合K比所有可能的关键字域U要小的多时,散列表需要的存储空间要比直接寻址表少的很多。散列表通过散列函数h计算出关键字k在槽的位置。散列函数h将关键字域U映射到散列表T[0....m-1]的槽位上。即h:U->{0,1...,m-1}。采用散列函数的目的在于缩小需要处理的小标范围,从而降低了空间的开销。
散列表存在的问题:两个关键字可能映射到同一个槽上,即碰撞(collision)。需要找到有效的办法来解决碰撞。
3、散列函数
好的散列函数的特点是每个关键字都等可能的散列到m个槽位上的任何一个中去,并与其他的关键字已被散列到哪一个槽位无关。多数散列函数都是假定关键字域为自然数N={0,1,2,....},如果给的关键字不是自然数,则必须有一种方法将它们解释为自然数。例如对关键字为字符串时,可以通过将字符串中每个字符的ASCII码相加,转换为自然数。书中介绍了三种设计方案:除法散列法、乘法散法和全域散列法。
(1)除法散列法
通过取k除以m的余数,将关键字k映射到m个槽的某一个中去。散列函数为:h(k)=k mod m 。m不应是2的幂,通常m的值是与2的整数幂不太接近的质数。
(2)乘法散列法
这个方法看的时候不是很明白,没有搞清楚什么意思,先将基本的思想记录下来,日后好好消化一下。乘法散列法构造散列函数需要两个步骤。第一步,用关键字k乘上常数A(0<A<1),并抽取kA的小数部分。然后,用m乘以这个值,再取结果的底。散列函数如下:h(k) = m(kA mod 1)。
(3)全域散列
给定一组散列函数H,每次进行散列时候从H中随机的选择一个散列函数h,使得h独立于要存储的关键字。全域散列函数类的平均性能是比较好的。
4、碰撞处理
通常有两类方法处理碰撞:开放寻址(Open Addressing)法和链接(Chaining)法。前者是将所有结点均存放在散列表T[0..m-1]中;后者通常是把散列到同一槽中的所有元素放在一个链表中,而将此链表的头指针放在散列表T[0..m-1]中。
(1)开放寻址法
所有的元素都在散列表中,每一个表项或包含动态集合的一个元素,或包含NIL。这种方法中散列表可能被填满,以致于不能插入任何新的元素。在开放寻址法中,当要插入一个元素时,可以连续地检查或探测散列表的各项,直到有一个空槽来放置待插入的关键字为止。有三种技术用于开放寻址法:线性探测、二次探测以及双重探测。
<1>线性探测
给定一个普通的散列函数h':U —>{0,1,.....,m-1},线性探测方法采用的散列函数为:h(k,i) = (h'(k)+i)mod m,i=0,1,....,m-1
探测时从i=0开始,首先探查T[h'(k)],然后依次探测T[h'(k)+1],…,直到T[h'(k)+m-1],此后又循环到T[0],T[1],…,直到探测到T[h'(k)-1]为止。探测过程终止于三种情况:
(1)若当前探测的单元为空,则表示查找失败(若是插入则将key写入其中);
(2)若当前探测的单元中含有key,则查找成功,但对于插入意味着失败;
(3)若探测到T[h'(k)-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。
线性探测方法较容易实现,但是存在一次群集问题,即连续被占用的槽的序列变的越来越长。采用例子进行说明线性探测过程,已知一组关键字为(26,36,41,38,44,15,68,12,6,51),用除余法构造散列函数,初始情况如下图所示:

散列过程如下图所示:

<2>二次探测
二次探测法的探查序列是:h(k,i) =(h'(k)+i*i)%m ,0≤i≤m-1 。初次的探测位置为T[h'(k)],后序的探测位置在次基础上加一个偏移量,该偏移量以二次的方式依赖于i。该方法的缺陷是不易探查到整个散列空间。
<3>双重散列
该方法是开放寻址的最好方法之一,因为其产生的排列具有随机选择的排列的许多特性。采用的散列函数为:h(k,i)=(h1(k)+ih2(k)) mod m。其中h1和h2为辅助散列函数。初始探测位置为T[h1(k)],后续的探测位置在此基础上加上偏移量h2(k)模m。
(2)链接法
将所有关键字为同义词的结点链接在同一个链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。
举例说明链接法的执行过程,设有一组关键字为(26,36,41,38,44,15,68,12,6,51),用除余法构造散列函数,初始情况如下图所示: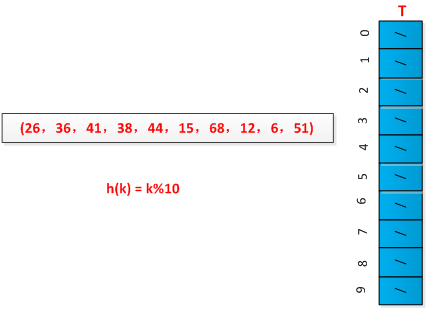
最终结果如下图所示:

5、字符串散列
通常都是将元素的key转换为数字进行散列,如果key本身就是整数,那么散列函数可以采用keymod tablesize(要保证tablesize是质数)。而在实际工作中经常用字符串作为关键字,例如身姓名、职位等等。这个时候需要设计一个好的散列函数进程处理关键字为字符串的元素。参考《数据结构与算法分析》第5章,有以下几种处理方法:
方法1:将字符串的所有的字符的ASCII码值进行相加,将所得和作为元素的关键字。设计的散列函数如下所示:
1 int hash(const string& key,int tablesize)
2 {
3 int hashVal = 0;
4 for(int i=0;i<key.length();i++)
5 hashVal += key[i];
6 return hashVal % tableSize;
7 }
此方法的缺点是不能有效的分布元素,例如假设关键字是有8个字母构成的字符串,散列表的长度为10007。字母最大的ASCII码为127,按照方法1可得到关键字对应的最大数值为127×8=1016,也就是说通过散列函数映射时只能映射到散列表的槽0-1016之间,这样导致大部分槽没有用到,分布不均匀,从而效率低下。
方法2:假设关键字至少有三个字母构成,散列函数只是取前三个字母进行散列。设计的散列函数如下所示:
1 int hash(const string& key,int tablesize)
2 {
3 //27 represents the number of letters plus the blank
4 return (key[0]+27*key[1]+729*key[2])%tablesize;
5 }
该方法只是取字符串的前三个字符的ASCII码进行散列,最大的得到的数值是2851,如果散列的长度为10007,那么只有28%的空间被用到,大部分空间没有用到。因此如果散列表太大,就不太适用。
方法3:借助Horner's 规则,构造一个质数(通常是37)的多项式,(非常的巧妙,不知道为何是37)。计算公式为:key[keysize-i-1]37^i,0<=i<keysize求和。设计的散列函数如下所示:
1 int hash(const string & key,int tablesize)
2 {
3 int hashVal = 0;
4 for(int i =0;i<key.length();i++)
5 hashVal = 37*hashVal + key[i];
6 hashVal %= tableSize;
7 if(hashVal<0) //计算的hashVal溢出
8 hashVal += tableSize;
9 return hashVal;
10 }
该方法存在的问题是如果字符串关键字比较长,散列函数的计算过程就变长,有可能导致计算的hashVal溢出。针对这种情况可以采取字符串的部分字符进行计算,例如计算偶数或者奇数位的字符。
6、再散列(rehashing)
如果散列表满了,再往散列表中插入新的元素时候就会失败。这个时候可以通过创建另外一个散列表,使得新的散列表的长度是当前散列表的2倍多一些,重新计算各个元素的hash值,插入到新的散列表中。再散列的问题是在什么时候进行最好,有三种情况可以判断是否该进行再散列:
(1)当散列表将快要满了,给定一个范围,例如散列被中已经被用到了80%,这个时候进行再散列。
(2)当插入一个新元素失败时候,进行再散列。
(3)根据装载因子(存放n个元素的、具有m个槽位的散列表T,装载因子α=n/m,即每个链子中的平均存储的元素数目)进行判断,当装载因子达到一定的阈值时候,进行在散列。
在采用链接法处理碰撞问题时,采用第三种方法进行在散列效率最好。
7、实例练习
看完书后,有一股想把hash表实现的冲动。在此设计的散列表针对的是关键字为字符串的元素,采用字符串散列函数方法3进行设计散列函数,采用链接方法处理碰撞,然后采用根据装载因子(指定为1,同时将n个元素映射到一个链表上,即n==m时候)进行再散列。采用C++,借助vector和list,设计的hash表框架如下:
1 template <class T>
2 class HashTable
3 {
4 public:
5 HashTable(int size = 101);
6 int insert(const T& x);
7 int remove(const T& x);
8 int contains(const T& x);
9 void make_empty();
10 void display()const;
11 private:
12 vector<list<T> > lists;
13 int currentSize;//当前散列表中元素的个数
14 int hash(const string& key);
15 int myhash(const T& x);
16 void rehash();
17 };
实现的完整程序如下所示:
1 #include <iostream>
2 #include <vector>
3 #include <list>
4 #include <string>
5 #include <cstdlib>
6 #include <cmath>
7 #include <algorithm>
8 using namespace std;
9
10 int nextPrime(const int n);
11
12 template <class T>
13 class HashTable
14 {
15 public:
16 HashTable(int size = 101);
17 int insert(const T& x);
18 int remove(const T& x);
19 int contains(const T& x);
20 void make_empty();
21 void display()const;
22 private:
23 vector<list<T> > lists;
24 int currentSize;
25 int hash(const string& key);
26 int myhash(const T& x);
27 void rehash();
28 };
29
30 template <class T>
31 HashTable<T>::HashTable(int size)
32 {
33 lists = vector<list<T> >(size);
34 currentSize = 0;
35 }
36
37 template <class T>
38 int HashTable<T>::hash(const string& key)
39 {
40 int hashVal = 0;
41 int tableSize = lists.size();
42 for(int i=0;i<key.length();i++)
43 hashVal = 37*hashVal+key[i];
44 hashVal %= tableSize;
45 if(hashVal < 0)
46 hashVal += tableSize;
47 return hashVal;
48 }
49
50 template <class T>
51 int HashTable<T>:: myhash(const T& x)
52 {
53 string key = x.getName();
54 return hash(key);
55 }
56 template <class T>
57 int HashTable<T>::insert(const T& x)
58 {
59 list<T> &whichlist = lists[myhash(x)];
60 if(find(whichlist.begin(),whichlist.end(),x) != whichlist.end())
61 return 0;
62 whichlist.push_back(x);
63 currentSize = currentSize + 1;
64 if(currentSize > lists.size())
65 rehash();
66 return 1;
67 }
68
69 template <class T>
70 int HashTable<T>::remove(const T& x)
71 {
72
73 typename std::list<T>::iterator iter;
74 list<T> &whichlist = lists[myhash(x)];
75 iter = find(whichlist.begin(),whichlist.end(),x);
76 if( iter != whichlist.end())
77 {
78 whichlist.erase(iter);
79 currentSize--;
80 return 1;
81 }
82 return 0;
83 }
84
85 template <class T>
86 int HashTable<T>::contains(const T& x)
87 {
88 list<T> whichlist;
89 typename std::list<T>::iterator iter;
90 whichlist = lists[myhash(x)];
91 iter = find(whichlist.begin(),whichlist.end(),x);
92 if( iter != whichlist.end())
93 return 1;
94 return 0;
95 }
96
97 template <class T>
98 void HashTable<T>::make_empty()
99 {
100 for(int i=0;i<lists.size();i++)
101 lists[i].clear();
102 currentSize = 0;
103 return 0;
104 }
105
106 template <class T>
107 void HashTable<T>::rehash()
108 {
109 vector<list<T> > oldLists = lists;
110 lists.resize(nextPrime(2*lists.size()));
111 for(int i=0;i<lists.size();i++)
112 lists[i].clear();
113 currentSize = 0;
114 for(int i=0;i<oldLists.size();i++)
115 {
116 typename std::list<T>::iterator iter = oldLists[i].begin();
117 while(iter != oldLists[i].end())
118 insert(*iter++);
119 }
120 }
121 template <class T>
122 void HashTable<T>::display()const
123 {
124 for(int i=0;i<lists.size();i++)
125 {
126 cout<<i<<": ";
127 typename std::list<T>::const_iterator iter = lists[i].begin();
128 while(iter != lists[i].end())
129 {
130 cout<<*iter<<" ";
131 ++iter;
132 }
133 cout<<endl;
134 }
135 }
136 int nextPrime(const int n)
137 {
138 int ret,i;
139 ret = n;
140 while(1)
141 {
142 int flag = 1;
143 for(i=2;i<sqrt(ret);i++)
144 if(ret % i == 0)
145 {
146 flag = 0;
147 break;
148 }
149 if(flag == 1)
150 break;
151 else
152 {
153 ret = ret +1;
154 continue;
155 }
156 }
157 return ret;
158 }
159
160 class Employee
161 {
162 public:
163 Employee(){}
164 Employee(const string n,int s=0):name(n),salary(s){ }
165 const string & getName()const { return name; }
166 bool operator == (const Employee &rhs) const
167 {
168 return getName() == rhs.getName();
169 }
170 bool operator != (const Employee &rhs) const
171 {
172 return !(*this == rhs);
173 }
174 friend ostream& operator <<(ostream& out,const Employee& e)
175 {
176 out<<"("<<e.name<<","<<e.salary<<") ";
177 return out;
178 }
179 private:
180 string name;
181 int salary;
182 };
183
184 int main()
185 {
186 Employee e1("Tom",6000);
187 Employee e2("Anker",7000);
188 Employee e3("Jermey",8000);
189 Employee e4("Lucy",7500);
190 HashTable<Employee> emp_table(13);
191
192 emp_table.insert(e1);
193 emp_table.insert(e2);
194 emp_table.insert(e3);
195 emp_table.insert(e4);
196
197 cout<<"Hash table is: "<<endl;
198 emp_table.display();
199 if(emp_table.contains(e4) == 1)
200 cout<<"Tom is exist in hash table"<<endl;
201 if(emp_table.remove(e1) == 1)
202 cout<<"Removing Tom form the hash table successfully"<<endl;
203 if(emp_table.contains(e1) == 1)
204 cout<<"Tom is exist in hash table"<<endl;
205 else
206 cout<<"Tom is not exist in hash table"<<endl;
207 //emp_table.display();
208 exit(0);
209 }
程序测试结果如下所示:

参考:http://www.cnblogs.com/zhanglanyun/archive/2011/09/01/2161729.html
散列表
散列方法不同于顺序查找、二分查找、二叉排序树及B-树上的查找。它不以关键字的比较为基本操作,采用直接寻址技术。在理想情况下,无须任何比较就可以找到待查关键字,查找的期望时间为O(1)。
一、散列表的概念
1、散列表
设所有可能出现的关键字集合记为U(简称全集)。实际发生(即实际存储)的关键字集合记为K(|K|比|U|小得多)。
散列方法是使用函数h将U映射到表T[0..m-1]的下标上(m=O(|U|))。这样以U中关键字为自变量,以h为函数的运算结果就是相应结点的存储地址。从而达到在O(1)时间内就可完成查找。其中:
① h:U→{0,1,2,…,m-1} ,通常称h为散列函数(Hash Function)。散列函数h的作用是压缩待处理的下标范围,使待处理的|U|个值减少到m个值,从而降低空间开销。
② T为散列表(Hash Table)。
③ h(K i )(K i ∈U)是关键字为K i 结点存储地址(亦称散列值或散列地址)。
④ 将结点按其关键字的散列地址存储到散列表中的过程称为散列(Hashing)
2、散列表的冲突现象
(1)冲突
两个不同的关键字,由于散列函数值相同,因而被映射到同一表位置上。该现象称为冲突(Collision)或碰撞。发生冲突的两个关键字称为该散列函数的同义词(Synonym)。
【例】上图中的k 2 ≠k 5 ,但h(k 2 )=h(k 5 ),故k 2 和K 5 所在的结点的存储地址相同。
(2)安全避免冲突的条件
最理想的解决冲突的方法是安全避免冲突。要做到这一点必须满足两个条件:
①其一是|U|≤m
②其二是选择合适的散列函数。这只适用于|U|较小,且关键字均事先已知的情况,此时经过精心设计散列函数h有可能完全避免冲突。
(3)冲突不可能完全避免
通常情况下,h是一个压缩映像。虽然|K|≤m,但|U|>m,故无论怎样设计h,也不可能完全避免冲突。因此,只能在设计h时尽可能使冲突最少。同时还需要确定解决冲突的方法,使发生冲突的同义词能够存储到表中。
(4)影响冲突的因素
冲突的频繁程度除了与h相关外,还与表的填满程度相关。设m和n分别表示表长和表中填人的结点数,则将α=n/m定义为散列表的装填因子(Load Factor)。α越大,表越满,冲突的机会也越大。通常取α≤1。
二、散列函数的构造方法
1、散列函数的选择有两条标准:简单和均匀。
简单指散列函数的计算简单快速;均匀指对于关键字集合中的任一关键字,散列函数能以等概率将其映射到表空间的任何一个位置上。也就是说,散列函数能将子集K随机均匀地分布在表的地址集{0,1,…,m-1}上,以使冲突最小化。
2、常用散列函数
为简单起见,假定关键字是定义在自然数集合上。其它关键字可以转换到自然数集合上。
(1)平方取中法
具体方法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
【例】将一组关键字(0100,0110,1010,1001,0111)平方后得
(0010000,0012100,1020100,1002001,0012321)
,若取表长为1000,则可取中间的三位数作为散列地址集:(100,121,201,020,123)。相应的散列函数用C实现很简单:
int Hash(int key){ //假设key是4位整数
key*=key; key/=100; //先求平方值,后去掉末尾的两位数
return key%1000; //取中间三位数作为散列地址返回
}
(2)除余法
该方法是最为简单常用的一种方法。它是以表长m来除关键字,取其余数作为散列地址,即 h(key)=key%m。该方法的关键是选取m。选取的m应使得散列函数值尽可能与关键字的各位相关。m最好为素数。
【例】若选m是关键字的基数的幂次,则就等于是选择关键字的最后若干位数字作为地址,而与高位无关。于是高位不同而低位相同的关键字均互为同义词。
【例】若关键字是十进制整数,其基为10,则当m=100时,159,259,359,…,等均互为同义词。
(3)相乘取整法
该方法包括两个步骤:首先用关键字key乘上某个常数A(0<A<1),并抽取出key.A的小数部分;然后用m乘以该小数后取整。即:

该函数的C代码为:
int Hash(int key){
double d=key *A; //不妨设A和m已有定义
return (int)(m*(d-(int)d));//(int)表示强制转换后面的表达式为整数
}
(4)随机数法
选择一个随机函数,取关键字的随机函数值为它的散列地址,即h(key)=random(key)其中random为伪随机函数,但要保证函数值是在0到m-1之间。
(5)数字分析法
设有
n 个 d 位数,每一位可能有 r 种不同的符号。这 r
种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布均匀些,每种符号出现的几率均等;
在某些位上分布不均匀,只有某几种符号经常出现。可根据散列表的大小,选取其中各种符号分布均匀的若干位作为散列地址。
(6)基数转换法
将关键码值看成另一种进制的数再转换成原来进制的数,然后选其中几位作为散列地址。
(7)折叠法
有时关键码所含的位数很多,采用平方取中法计算太复杂,则可将关键码分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为散列地址,这方法称为折叠法。
(8)ELFhash字符串散列函数
ELFhash函数在UNIX系统V
版本4中的“可执行链接格式”( Executable and Linking Format,即ELF
)中会用到,ELF文件格式用于存储可执行文件与目标文件。ELFhash函数是对字符串的散列。它对于长字符串和短字符串都很有效,字符串中每个字符都有同样的作用,它巧妙地对字符的ASCII编码值进行计算,ELFhash函数对于能够比较均匀地把字符串分布在散列表中。
三、处理冲突的方法
通常有两类方法处理冲突:开放定址(Open Addressing)法和拉链(Chaining)法。前者是将所有结点均存放在散列表T[0..m-1]中;后者通常是将互为同义词的结点链成一个单链表,而将此链表的头指针放在散列表T[0..m-1]中。
1、开放定址法
(1)开放地址法解决冲突的方法
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的地址则表明表中无待查的关键字,即查找失败。注意:
①用开放定址法建立散列表时,建表前须将表中所有单元(更严格地说,是指单元中存储的关键字)置空。
②空单元的表示与具体的应用相关。
【例】关键字均为非负数时,可用"-1"来表示空单元,而关键字为字符串时,空单元应是空串。
总之:应该用一个不会出现的关键字来表示空单元。
(2)开放地址法的一般形式
开放定址法的一般形式为: h i =(h(key)+d i )%m 1≤i≤m-1.其中:
①h(key)为散列函数,d i 为增量序列,m为表长。
②h(key)是初始的探查位置,后续的探查位置依次是h l ,h 2 ,…,h m-1 ,即h(key),h l ,h 2 ,…,h m-1 形成了一个探查序列。
③若令开放地址一般形式的i从0开始,并令d 0 =0,则h 0 =h(key),则有: h i =(h(key)+d i )%m 0≤i≤m-1.探查序列可简记为h i (0≤i≤m-1)。
(3)开放地址法堆装填因子的要求
开放定址法要求散列表的装填因子α≤l,实用中取α为0.5到0.9之间的某个值为宜。
(4)形成探测序列的方法
按照形成探查序列的方法不同,可将开放定址法区分为线性探查法、二次探查法、双重散列法等。
①线性探查法(Linear Probing)
该方法的基本思想是:将散列表T[0..m-1]看成是一个循环向量,若初始探查的地址为d(即h(key)=d),则最长的探查序列为:d,d+l,d+2,…,m-1,0,1,…,d-1
.即:探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循环到T[0],T[1],…,直到探查到T[d-1]为止。探查过程终止于三种情况:
(1)若当前探查的单元为空,则表示查找失败(若是插入则将key写入其中);
(2)若当前探查的单元中含有key,则查找成功,但对于插入意味着失败;
(3)若探查到T[d-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。
利用开放地址法的一般形式,线性探查法的探查序列为:
h i =(h(key)+i)%m 0≤i≤m-1 //即d i =i
【例9.1】已知一组关键字为(26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。
解答:为了减少冲突,通常令装填因子α<l。这里关键字个数n=10,不妨取m=13,此时α≈0.77,散列表为T[0..12],散列函数为:h(key)=key%13。由除余法的散列函数计算出的上述关键字序列的散列地址为(0,10,2,12,5,2,3,12,6,12)。前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入T[0],T[10),T[2],T[12]和T[5]中。当插入第6个关键字15时,其散列地址2(即h(15)=15%13=2)已被关键字41(15和41互为同义词)占用。故探查h1=(2+1)%13=3,此地址开放,所以将15放入T[3]中。当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。当插入第8个关键字12时,散列地址12已被同义词38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址开放,可将12插入其中。类似地,第9个关键字06直接插入T[6]中;而最后一个关键字51插人时,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。
用线性探查法解决冲突时,当表中i,i+1,…,i+k的位置上已有结点时,一个散列地址为i,i+1,…,i+k+1的结点都将插入在位置i+k+1上。把这种散列地址不同的结点争夺同一个后继散列地址的现象称为聚集或堆积(Clustering)。这将造成不是同义词的结点也处在同一个探查序列之中,从而增加了探查序列的长度,即增加了查找时间。若散列函数不好或装填因子过大,都会使堆积现象加剧。
【例】上例中,h(15)=2,h(68)=3,即15和68不是同义词。但由于处理15和同义词41的冲突时,15抢先占用了T[3],这就使得插入68时,这两个本来不应该发生冲突的非同义词之间也会发生冲突。
为了减少堆积的发生,不能像线性探查法那样探查一个顺序的地址序列(相当于顺序查找),而应使探查序列跳跃式地散列在整个散列表中。
②二次探查法(Quadratic Probing)
二次探查法的探查序列是:h i =(h(key)+i*i)%m 0≤i≤m-1 //即d i =i 2,即探查序列为d=h(key),d+1 2 ,d+2 2 ,…,等。该方法的缺陷是不易探查到整个散列空间。
③双重散列法(Double Hashing)
该方法是开放定址法中最好的方法之一,它的探查序列是:h i =(h(key)+i*h1(key))%m 0≤i≤m-1 //即d i
=i*h1(key),即探查序列为:d=h(key),(d+h1(key))%m,(d+2h1(key))%m,…,等。
该方法使用了两个散列函数h(key)和h1(key),故也称为双散列函数探查法。
注意:定义h1(key)的方法较多,但无论采用什么方法定义,都必须使h1(key)的值和m互素,才能使发生冲突的同义词地址均匀地分布在整个表中,否则可能造成同义词地址的循环计算。
【例】 若m为素数,则h1(key)取1到m-1之间的任何数均与m互素,因此,我们可以简单地将它定义为:h1(key)=key%(m-2)+1
【例】对例9.1,我们可取h(key)=key%13,而h1(key)=key%11+1。
【例】若m是2的方幂,则h1(key)可取1到m-1之间的任何奇数。
2、拉链法
(1)拉链法解决冲突的方法
拉链法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。
【例9.2】已知一组关键字和选定的散列函数和例9.1相同,用拉链法解决冲突构造这组关键字的散列表。
解答:不妨和例9.1类似,取表长为13,故散列函数为h(key)=key%13,散列表为T[0..12]。
注意:当把h(key)=i的关键字插入第i个单链表时,既可插入在链表的头上,也可以插在链表的尾上。这是因为必须确定key不在第i个链表时,才能将它插入表中,所以也就知道链尾结点的地址。若采用将新关键字插入链尾的方式,依次把给定的这组关键字插入表中,则所得到的散列表如下图所示。

(2)拉链法的优点
与开放定址法相比,拉链法有如下几个优点:(1)拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;(2)由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;(4)在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
(3)拉链法的缺点
拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
四、散列表上的运算
散列表上的运算有查找、插入和删除。其中主要是查找,这是因为散列表的目的主要是用于快速查找,且插入和删除均要用到查找操作。
1、散列表类型说明:
#define NIL -1 //空结点标记依赖于关键字类型,本节假定关键字均为非负整数
#define M 997 //表长度依赖于应用,但一般应根据。确定m为一素数
typedef struct{ //散列表结点类型
KeyType key;
InfoType otherinfo; //此类依赖于应用
}NodeType;
typedef NodeType HashTable[m]; //散列表类型
2、基于开放地址法的查找算法
散列表的查找过程和建表过程相似。假设给定的值为K,根据建表时设定的散列函数h,计算出散列地址h(K),若表中该地址单元为空,则查找失败;否则将该地址中的结点与给定值K比较。若相等则查找成功,否则按建表时设定的处理冲突的方法找下一个地址。如此反复下去,直到某个地址单元为空(查找失败)或者关键字比较相等(查找成功)为止。
(1)开放地址法一般形式的函数表示
int Hash(KeyType k,int i)
{ //求在散列表T[0..m-1]中第i次探查的散列地址hi,0≤i≤m-1
//下面的h是散列函数。Increment是求增量序列的函数,它依赖于解决冲突的方法
return(h(K)+Increment(i))%m; //Increment(i)相当于是d i
}
若散列函数用除余法构造,并假设使用线性探查的开放定址法处理冲突,则上述函数中的h(K)和Increment(i)可定义为:
int h(KeyType K){//用除余法求K的散列地址
return K%m;
}
int Increment(int i){
//用线性探查法求第i个增量d i
return i; //若用二次探查法,则返回i*i
}
(2)通用的开放定址法的散列表查找算法:
int HashSearch(HashTable T,KeyType K,int *pos)
{ //在散列表T[0..m-1]中查找K,成功时返回1。失败有两种情况:找到一个开放地址
//时返回0,表满未找到时返回-1。 *pos记录找到K或找到空结点时表中的位置
int i=0; //记录探查次数
do{
*pos=Hash(K,i); //求探查地址hi
if(T[*pos].key==K) return l; //查找成功返回
if(T[*pos].key==NIL) return 0;//查找到空结点返回
}while(++i<m) //最多做m次探查
return -1; //表满且未找到时,查找失败
} //HashSearch
注意:上述算法适用于任何开放定址法,只要给出函数Hash中的散列函数h(K)和增量函数Increment(i)即可。但要提高查找效率时,可将确定的散列函数和求增量的方法直接写入算法HashSearch中。
3、基于开放地址法的插入及建表
建表时首先要将表中各结点的关键字清空,使其地址为开放的;然后调用插入算法将给定的关键字序列依次插入表中。插入算法首先调用查找算法,若在表中找到待插入的关键字或表已满,则插入失败;若在表中找到一个开放地址,则将待插入的结点插入其中,即插入成功。
void Hashlnsert(HashTable T,NodeTypene w)
{ //将新结点new插入散列表T[0..m-1]中
int pos,sign;
sign=HashSearch(T,new.key,&pos); //在表T中查找new的插入位置
if(!sign) //找到一个开放的地址pos
T[pos]=new; //插入新结点new,插入成功
else //插人失败
if(sign>0)
printf("duplicate key!"); //重复的关键字
else //sign<0
Error("hashtableoverflow!"); //表满错误,终止程序执行
} //Hashlnsert
void CreateHashTable(HashTable T,NodeType A[],int n)
{ //根据A[0..n-1]中结点建立散列表T[0..m-1]
int i
if(n>m) //用开放定址法处理冲突时,装填因子α须不大于1
Error("Load factor>1");
for(i=0;i<m;i++)
T[i].key=NIL; //将各关键字清空,使地址i为开放地址
for(i=0;i<n;i++) //依次将A[0..n-1]插入到散列表T[0..m-1]中
Hashlnsert(T,A[i]);
} //CreateHashTable
4、删除
基于开放定址法的散列表不宜执行散列表的删除操作。若必须在散列表中删除结点,则不能将被删结点的关键字置为NIL,而应该将其置为特定的标记DELETED。因此须对查找操作做相应的修改,使之探查到此标记时继续探查下去。同时也要修改插人操作,使其探查到DELETED标记时,将相应的表单元视为一个空单元,将新结点插入其中。这样做无疑增加了时间开销,并且查找时间不再依赖于装填因子。因此,当必须对散列表做删除结点的操作时,一般是用拉链法来解决冲突。
5、性能分析
插入和删除的时间均取决于查找,故下面只分析查找操作的时间性能。
虽然散列表在关键字和存储位置之间建立了对应关系,理想情况是无须关键字的比较就可找到待查关键字。但是由于冲突的存在,散列表的查找过程仍是一个和关键字比较的过程,不过散列表的平均查找长度比顺序查找、二分查找等完全依赖于关键字比较的查找要小得多。
(1)查找成功的ASL
散列表上的查找优于顺序查找和二分查找。
【例】在例9.1和例9.2的散列表中,在结点的查找概率相等的假设下,线性探查法和拉链法查找成功的平均查找长度分别为:
ASL=(1×6+2×2+3×l+9×1)/10=2.2 //线性探查法
ASL=(1×7+2×2+3×1)/10=1.4 //拉链法
当n=10时,顺序查找和二分查找的平均查找长度(成功时)分别为:
ASL=(10+1)/2=5.5 //顺序查找
ASL=(1×l+2×2+3×4+4×3)/10=2.9 //二分查找,可由判定树求出该值
(2) 查找不成功的ASL
对于不成功的查找,顺序查找和二分查找所需进行的关键字比较次数仅取决于表长,而散列查找所需进行的关键字比较次数和待查结点有关。因此,在等概率情况下,也可将散列表在查找不成功时的平均查找长度,定义为查找不成功时对关键字需要执行的平均比较次数。
【例】例9.1和例9.2的散列表中,在等概率情况下,查找不成功时的线性探查法和拉链法的平均查找长度分别为:
ASL unsucc =(9+8+7+6+5+4+3+2+1+1+2+1+10)/13=59/13≈4.54
ASL unsucc =(1+0+2+1+0+1+1+0+0+0+1+0+3)/13≈10/13≈0.77
注意:
①由同一个散列函数、不同的解决冲突方法构造的散列表,其平均查找长度是不相同的。
②散列表的平均查找长度不是结点个数n的函数,而是装填因子α的函数。因此在设计散列表时可选择α以控制散列表的平均查找
长度。
③ α的取值越小,产生冲突的机会就小,但α过小,空间的浪费就过多。只要α选择合适,散列表上的平均查找长度就是一个常数,即散列表上查找的平均时间为O(1)。
④ 散列法与其他查找方法的区别
除散列法外,其他查找方法有共同特征为:均是建立在比较关键字的基础上。其中顺序查找是对无序集合的查找,每次关键字的比较结果为"="或"!="两种可能,其平均时间为O(n);其余的查找均是对有序集合的查找,每次关键字的比较有"="、"<"和">"三种可能,且每次比较后均能缩小下次的查找范围,故查找速度更快,其平均时间为O(lgn)。而散列法是根据关键字直接求出地址的查找方法,其查找的期望时间为O(1)。