转自:http://www.cnblogs.com/rechen/p/5143841.html
1、环形缓冲区
缓冲区的好处,就是空间换时间和协调快慢线程。缓冲区可以用很多设计法,这里说一下环形缓冲区的几种设计方案,可以看成是几种环形缓冲区的模式。设 计环形缓冲区涉及到几个点,一是超出缓冲区大小的的索引如何处理,二是如何表示缓冲区满和缓冲区空,三是如何入队、出队,四是缓冲区中数据长度如何计算。
ps.规定以下所有方案,在缓冲区满时不可再写入数据,缓冲区空时不能读数据
1.1、常规数组环形缓冲区
设缓冲区大小为N,队头out,队尾in,out、in均是下标表示:
- 初始时,in=out=0
- 队头队尾的更新用取模操作,out=(out+1)%N,in=(in+1)%N
- out==in表示缓冲区空,(in+1)%N==out表示缓冲区满
- 入队que[in]=value;in=(in+1)%N;
- 出队ret =que[out];out=(out+1)%N;
- 数据长度 len =( in - out + N) % N
1.2、改进版数组环形缓冲区
同样假设缓冲区大小为N,队头out,队尾in,out、in为数组下标,但数据类型为unsigned int。
- 初始时,in=out=0
- 上调缓冲区大小N为2的幂,假设为M
- 队头队尾更新不再取模,直接++out,++in
- out==in表示缓冲区空,(in-out)==M表示缓冲区满
- 入队que[in&(M-1)] = value ; ++in;
- 出队ret = que[out&(M-1)] ; ++out;
- in-out表示数据长度
这个改进的思想来自linux内核循环队列kfifo,这里解释一下几个行为的含义及原理
⑴上调缓冲区大小至2的幂
这是方便取模,x%M == x&(M-1) 为真,位运算的效率比取模要高。用一个例子来分析一下为什么等式成立的:
假设M=8=2³,那么M-1=7,二进制为0000 0111
①若 x<8 ----> x&7=x , x%8 = x,等式成立
②若 x>8 ----> x = 2^a+2^b+2^c+... 比如,51 = 1+2+16+32 = 2^0+2^1+2^4+2^5 ,求 51&7时,由于7的二进制0000 0111,所以2的幂只要大于等于2³的数,与上7结果都是0,所以2^4 & 7 = 0 , 2^5 & 7 = 0, (2^0+2^1+2^4+2^5) & (7) = 2^0+2^1=3。而根据①,(2^0+2^1)&7 = (2^0+2^1)%8 ,所以51&7=51%8
综上得证。
⑵out、in类型设计为unsigned int
无符号整形的溢出之后,又从0开始计数:MAX_UNSIGNED_INT + 1 = 0 ,MAX_UNSIGNED_INT + 2 = 1 ,... 。
in、out溢出之前,都能通过&把in、out映射到正确的位置上,那溢出之后呢?可以举个例子来:
假设现在in=MAX_UNSIGNED_INT,那么in & (M-1) = M-1 ,也就是最后一个位置,再入队时,应该从头开始入队,也就是0,而in+1也为0,所以即使溢出了,(in+1)&(M-1)仍然能映射到正确的 位置。这就是为什么我们入队出队只要做个与映射和++操作就能保证正确的原因。
而,根据入队和出队的操作,队列中的元素总是维持在[out,in)这个区间中,由于溢出可能存在,这个区间有三种情况:
- out没溢出,in没溢出,in-out就是这个缓冲区中数据的长度。
- out没溢出,in溢出,此时数据长度应该是MAX_UNSIGNED_INT - out +1 + in = in - out + MAX_UNSIGNED_INT +1 = in-out。
- out溢出,in溢出,此时数据长度也是in-out。
根据上面三种情况,in-out总是表示环形队列中数据的长度
不得不惊叹,linux内核中的kfifo实现实在是太精妙了。相比前面的版本,所有的取余操作都改成了与运算,入队出队,求缓冲区数据长度都变得非常简单。
1.3、链表实现的环形缓冲区
环形缓冲区的链表实现比数组实现要简单一些,可以用下图的这种设计方案:
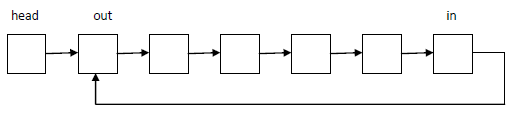
假设要求环形缓冲区大小为N
- 队列长度:可以设计一个size的成员,每次O(1)取size,也可以O(N)遍历队列求size
- 队列空:head->next == NULL
- 队列满:size == N
- 出队核心
ret = out;
out = out->next;
head->next = out; - 入队核心new_node表示新申请的结点
new_node->next = in->next;
in->next = in_node;
++size;
当然,链表结点的设定是自由的,链表结点本身可以内含数组、链表、哈希表等等,例如下面这样,内含一个数组
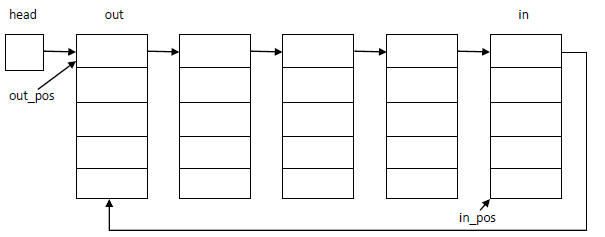
这时,可以增设两个变量out_pos,in_pos。假设结点内数组的大小为N_ELEMS,整个链表结点的数量为node_nums
- 队列长度:(nodes_nums-2)*N+N-out_pos+in_pos
- 队列空:head->next == NULL
- 队列满:队列长度 == N
- 出队核心
out_pos == N_ELEMS;
delete_node = out;
free(delete_node);
out = out->next;
out_pos = 0;
head->next = out;
ret = out[out_pos++]; - 入队核心,new_node表示新申请的核心
in_pos == N_ELEMS;
new_node->next = in->next;
in = new_node;
in_pos = 0;
in[in_pos++] = value;
1.4、改进链表环形缓冲区
上面链表环形队列出队列可能释放内存,入队列可能申请内存,所以,可以用个空闲链表把该释放的内存管理起来,入队列时,如果要增加结点,先从空闲链表中取结点,取不到再去申请内存,这样就可以避免多次分配释放内存了,至于其他的操作都是一样的。
上边只是简单的说了下入队出队等操作,事实上,缓冲区往往是和读写线程伴随出现 的,缓冲区中的每一个资源,对于同类线程可能需要互斥访问,也可能可以共享使用,而不同类线程间(读写线程)往往需要做同步操作。比如,读线程之间可能共 享缓冲区的每一个资源,也可能互斥使用每个资源,通常,在缓冲区满时写线程不能写,缓冲区空时读线程不能读,也就是读写线程要求同步。这其实就是操作系统 课程上PV操作的几个经典模式,如果读读之间、写写之间要求互斥使用资源,并且读写线程间不要求互斥,就是生产者消费者问题,如果读读之间不要求互斥(每 个资源可供多个读线程共同使用),写写之间要求互斥(每个资源仅供一个写线程使用),并且读写线程也要求互斥(读的时候不能写,写的时候不能读),就是读 写者问题。
下面会以生产者消费者模式和1.2节改进版的循环缓冲区为例,来说说并发循环队列有锁实现,下一篇说无锁实现。关于读写者的问题,以后有时间再详谈。
2、生产者消费者
先提一嘴生产者消费者的优点吧
- 并发,若缓冲区中数据处理方式一致,可以开多个线程或进程处理数据或生产数据
- 异步,生产者无需干等着消费者消费数据,消费者也无需干等着生产者生产数据,只需根据缓冲区的状态做出相应反应,如果结合io多用复用技术,也就是所谓的反应器模式,可以设计很好的异步通信架构,像zeromq底层的线程通信就是使用这种方案来做的。
- 解耦,解耦可以说是一个附带作用,由于生产者和消费者无直接关联,也就是生产者中不会去调用任何消费者的方法或者反过来,所以任何一方的变动不影响另一方。
- 缓冲,主要是保持各自的性能,比如生产者很快,那没关系,消费者虽然消费不过来,但可以把数据放缓冲区里。
现在正式开工,根据生产者和消费者的数量,可以把生产者消费者划分为四种类型,1:1,1:N,M:1,M:N。
然后再做个规定,规定环形缓冲区的大小为M,M为2的幂次方,in、out统一称为slot。
2.1、单生产者单消费者
一个生产者,一个消费者,缓冲区可用资源数为M。
这种情况只要同步生产者和消费者,同步的方法是用两个信号量available_in_slots,available_out_slots分别表示生产者有多个可用资源、消费者有多个可用资源, 每生产一个产品,生产者可用资源减1,消费者可用资源加1,这点可用PV操作来实现,用P操作可以消耗1个资源,P操作结束资源数减1,V操作可以生产1 个资源,V操作结束后资源数加1。初始时,available_in_slots=M,表示生产者有M个空间可放产 品,available_out_slots=0,表示消费者还没有可用资源:

available_in_slots = M; available_out_slots = 0; in=out=0; void producer() { while(true){ P(available_in_slots); queue[(in++)&(M-1)] = data; V(available_out_slots) } } void consumer() { while(true){ P(available_out_slots); queue[(out++)&(M-1)] = data; V(available_in_slots) } }
2.2、单生产者多消费者
一个生产者,多个消费者,缓冲区可用资源数位M。
这种情况下,消费者有多个,消费者之间对out slot要互斥访问,用out_slot_mutex来实现消费者间的互斥,拿到out_slot_mutex的消费者线程才得以继续执行,没拿到的只能 阻塞。生产者消费者要同步,用available_in_slots,available_out_slots来实现生产者消费者的同步。