一、RabbitMQ的几个关键概念
1、Connection和Channel
生产者/消费者都需要和RabbitMQ Broker建立连接,每个连接都是一条TCP连接,也就是Connection。
一旦TCP连接建立起来后,客户端就创建一个AMQP信道(Channel),每个信道都会被指派一个唯一的ID。Channel是建立在Connection之上的虚拟连接,RabbitMQ处理的每条AMQP指令都是通过信道完成的。
我们完全可以使用 Connection 就能完成客户端和rabbitmq的通讯,为什么还要引入信道呢?
因为,在通常的应用场景下,可能会有多个线程(生产者/消费者)需要同时和RabbitMQ通信,那么必然会创建多个Connection,也就是多个TCP连接。但建立和销毁TCP连接都会有很大的系统开销。
所以,RabbitMQ 采用类似NIO(Non-blocking I/O)的方法,选择TCP连接复用。在connection上建立channel,不仅可以减少性能开销,同时也便于管理。
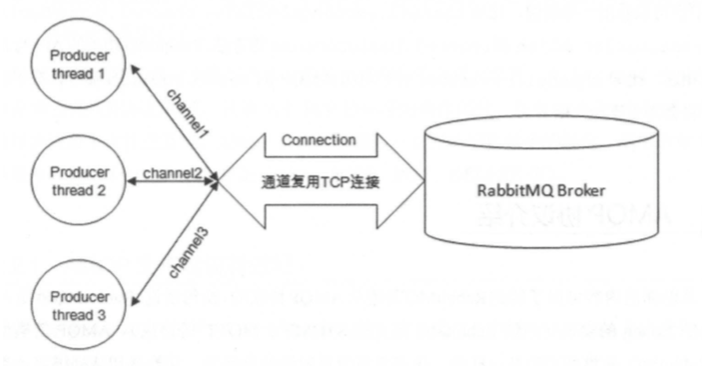
每个线程把持一个信道,所以信道复用了 Connection 的 TCP 连接。同时 RabbitMQ 可以确保每个线程的私密性,就像拥有独立的连接一样。当每个信道的流量不是很大时,复用单一的 Connection 可以在产生性能瓶颈的情况下有效地节省 TCP 连接资源。但是信道本身的流量很大时,多个信道继续复用一个 Connection 的话就会产生性能瓶颈。此时,就需要开辟多个 Connection,将这些信道平均分配到这些 Connection 中,至于这些相关的调优策略需要根据业务自身的实际情况进行调节。
信道在 AMQP 中是一个很重要的概念,大多数操作都是在信道这个层面展开的。
比如 channel.exchangeDeclare、channel.queueDeclare、channel.basicPublish、channel.basicConsume 等方法。
RabbitMQ 相关的 API 与 AMQP 紧密相连,比如 channel.basicPublish 对应 AMQP 的 Basic.Publish 命令。
2、Exchange、Queue、Route
Broker:就是消息队列服务器实体,指rabbitmq实例。
Channel:消息通道,在客户端的每个连接connection上,可建立多个channel,每个channel代表一个会话任务。
Exchange:消息交换机,它指定消息按什么规则路由到哪个队列。
Queue:消息队列载体,存放消息的地方,每个消息都会被投入到一个或多个队列中。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
Producer:消息生产者,生产投递消息的程序。
Consumer:消息消费者,接受处理消息的程序。
二、使用Tracing日志记录消息
RabbitMQ 的 Tracing能跟踪RabbitMQ中消息的流入流出情况。rabbitmq_tracing插件会对流入流出的消息做封装,然后将封装后的消息日志存入相应的trace文件之中。
可以使用 rabbitmq-plugins enable rabbitmq_tracing 命令来启动rabbitmq_tracing插件。如果是使用docker部署的,先进入docker环境,再开启。
在rabbitmq 的GUI 管理界面 “Admin” 选项右侧原本只有 ”Users”、”Virtual Hosts”和 ”Policies“ 三项,在添加rabbitmq_tracing 插件之后,会多出”Tracing”选项。
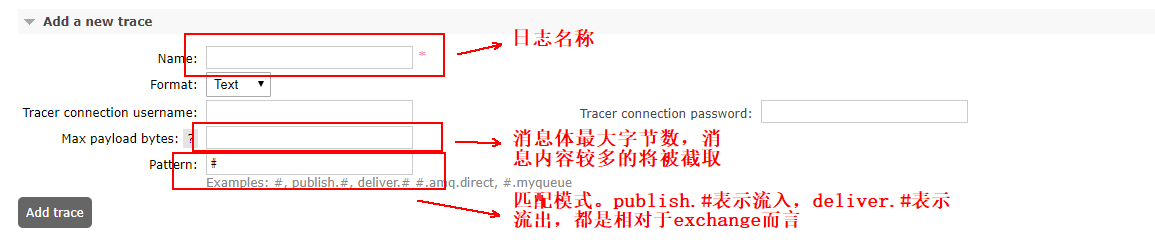
Name:自定义日志名称,建议标准点容易区分。
Format:表示输出的消息日志格式,有Text和JSON两种,Text格式的日志方便人类阅读,JSON的方便程序解析。Text相比JSON格式占用空间稍大点。
JSON格式的payload(消息体)默认会采用Base64进行编码。
Max payload bytes:表示每条消息的最大限制,单位为B。比如设置了了此值为10,那么当有超过10B的消息经过Rabbit MQ时会被截断。如消息“trace test payload.”会被截断成“trace test”。
Pattern:用来设置匹配模式,如“#” 匹配所有消息流入流出的情况,即当有客户端生产消息或消费消息的时候,都会把相应的消息日志记录下来。“publish.#” 匹配所有消息流入的情况;“deliver.#” 匹配所有消息流出的情况;“publish.exchange.b2b.gms.ass”只匹配发送者(Exchanges)为exchange.b2b.gms.ass的所有消息流入的情况。
三、持久化
RabbitMQ默认是不持久Exchange、Queue、Binding以及队列中消息的,这意味着一旦MQ服务器重启,所有已声明的队列,Exchange,Binding以及队列中的消息都会丢失。为了防止丢失,需要实现持久化。但持久化会对RabbitMQ的性能造成很大的影响,可能会下降10倍不止。所以,为了提高rabbitmq的性能,没有必要持久化的可以不用设置为持久化。
1、Exchange 和 Queue 持久化
把Exchange 和 Queue 的durable 属性置为true,可以实现Queue 和Exchange 的持久化。但这里需要注意的是,只有Exchange 和Queues 的durable都为true 时才能绑定,否则在绑定时,RabbitMQ会报错的。也就是说,
2、Message 持久化
消息的持久化需要在消息投递的时候设置delivery mode值为2。消息持久化必须同时要求exchange和queue也是持久化的。
持久化的代价就是性能损失,磁盘IO远远慢于RAM(使用SSD会显著提高消息持久化的性能) , 持久化会大大降低RabbitMQ每秒可处理的消息.两者的性能差距可能在10倍以上。
- exchange持久化,在声明时指定durable => 1
- queue持久化,在声明时指定durable => 1
- 消息持久化,在投递时指定delivery_mode => 2(1是非持久化)