去年,OpenAI和DeepMind联手做了当时最酷的实验,不用经典的奖励信号来训练智能体,而是根据人类反馈进行强化学习的新方法。有篇博客专门讲了这个实验 Learning from Human Preferences,原始论文是《 Deep Reinforcement Learning from Human Preferences》(根据人类偏好进行的深度增强学习)。
链接:https://arxiv.org/pdf/1706.03741.pdf

过一些深度强化学习,你也可以训练木棍做后空翻
我曾经看到过一些建议:复现论文是提高机器学习能力的一种很好的方法,这对我自己来说是一个有趣的尝试。Learning from Human Preferences 的确是一个很有意思的项目,我很高兴能复现它,但是回想起来这段经历,却和预期有出入。
如果你也想复现论文,以下是一些深度强化学习的注意事项:
· · ·
首先,通常来说,强化学习要比你预期的要复杂得多。
很大一部分原因是,强化学习非常敏感。有很多细节需要正确处理,如果不正确的话,你很难判断出哪里出了问题。
情况1:完成基本实现后,执行训练却没有成功。对于这个问题,我有各种各样的想法,但结果证明是因为激励的正则化和关键阶段1的像素数据。尽管事后我知道是哪里出了问题,但也找不到可循的通关路径:基于像素数据的激励预测器网络准确性的确很好,我花了很长时间仔细检查激励预测器,才发现注意到激励正则化错误。找出问题发生的原因很偶然,因为注意到一个小的差错,才找到了正确的道路。
情况2:在做最后的代码清理时,我意识到我把Dropout搞错了。激励预测器网络以一对视频片段作为输入,每个视频片段由两个具有共享权重的网络进行相同的处理。如果你在每个网络中都添加了Dropout,并且不小心忘记给每个网络提供相同的随机种子,那么对于每个网络,Dropout出的网络都是不同的,这样视频剪辑就不会进行相同的处理了。尽管预测网络的准确性看起来完全一样,但实际上完全破坏了原来的网络训练。
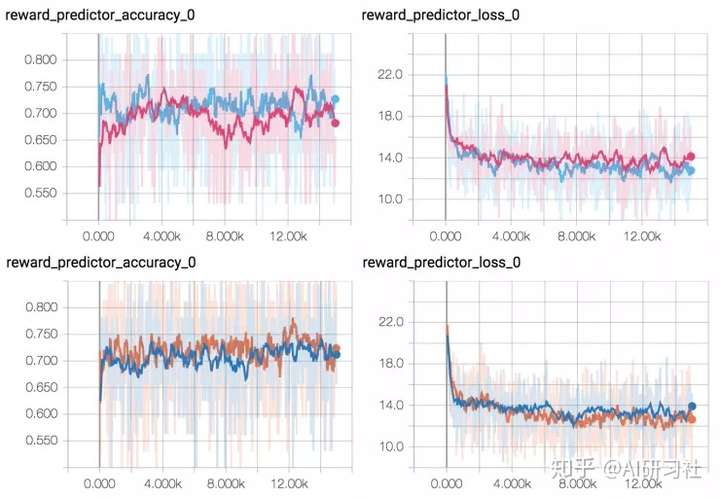
哪一个是坏的?嗯,我也看不明白
我觉得这是经常会发生的事情 (比如:《Deep Reinforcement Learning Doesn’t Work Yet 》)。我的收获是,当你开始一个强化学习项目的时候,理论上会遇到一个像被数学题困住了一样的困境。这并不像我通常的编程经验:在你被困的地方,通常有一条清晰的线索可以遵循,你最多可以在几天之内摆脱困境。 这更像是当你试图解决一个难题时,问题没有明显的进展,唯一的方法就是各种尝试,直到你找到关键的证据,或者找到重要的灵感,让你找到答案。
所以结论是在感到疑惑时应该尽可能注意到细节。
在这个项目中有很多要点,唯一的线索来自于注意那些微不足道的小事情。 例如,有时将帧之间的差异作为特征会很有效。直接利用新的特征是很有诱惑力的,但是我意识到,我并不清楚为什么它对我当时使用的简单环境产生如此大的影响。 只有处在这样的困惑下,才能发现,将背景归零后取帧之间的差异会使得正则化问题显现出来。
我不太确定怎么样能让人意识这些,但我目前最好的猜测是:
- 学会了解困惑是什么样的感觉。 有很多各种各样“不太对”的感觉。 有时候你知道代码很难看。 有时候担心在错误的事情上浪费时间。 但有时你看到了一些你没有预料到的东西:困惑。 能够认识到不舒服的确切程度是很重要的,这样你就可以发现问题。
- 养成在困惑中坚持的习惯。 有一些不舒服的地方可以暂时忽略 (例如:原型开发过程中的代码嗅觉 ),但困惑不能忽略。当你感到到困惑时,尽量去找到原因这是很重要的。
还有,最好做好每几周就会陷入困境的准备。如果你坚持下去,注意那些小细节并且充满信心,你就能到达彼岸。
· · ·
说到过去编程经验的不同,第二个主要的学习经验是在长迭代时间下工作所需的思维方式的差异。
调试似乎涉及四个基本步骤:
- 搜集关于问题可能性的相关证据
- 形成关于这个问题的假设(根据你迄今为止搜集到的证据)
- 选择最有可能的假设,实现修复,看看会发生什么
- 重复以上步骤,直到问题消失
在我以前做过的大多数编程中,我已经习惯了快速反馈。如果有些东西不起作用,你可以做一个改变,看看它在几秒钟或几分钟内会产生什么不同。收集这些证据很容易。
事实上,在快速反馈的情况下,收集证据比形成假设要容易得多。当你能在短时间内验证第一个想法时,为什么要花15分钟仔细考虑所有的事情,即使它们可能是导致现象的原因?换句话说:如果你能获得快速反馈的话,不用经过认真思考,只要不停尝试就行了。
如果你采用的是尝试策略,每次尝试都需要花10小时,是种非常浪费时间的做法。如果最后一次都没有成功呢?好吧,我承认事情有时候就是这样。那我们就再检查一次。第二天早上回来:还是没用?好吧,也许是另一种,那我们就再跑一次吧。一个星期过后,你还没有解决这个问题。
同时进行多次运行,每次尝试不同的事情,在某种程度上都会有所帮助。但是 a) 除非你能够用集群,否则你最终可能会在云计算上付出大量的代价(见下文); b) 由于上面提到的强化学习的困难,如果你试图迭代得太快,你可能永远不会意识到你到底需要什么样的证据。
从大量的实验和少量的思考,转变为少量的尝试和大量的思考,是生产力的一个关键转变。在较长的迭代时间进行调试时,你确实需要投入大量的时间到建立假设--形成步骤--思考所有的可能性是什么,它们自己看起来有多大的可能性,以及根据到目前为止所看到的一切,它们看起来有多大的可能性。尽可能多地花你时间在上面,即使需要30分钟或一个小时。一旦你把假设空间尽可能完善了充实了,知道哪些证据可以让你能够最好地区分不同的可能性才可以着手实验。
(如果你把该项目作为业余项目,那么仔细考虑这个问题就显得尤为重要了。 如果你每天只在这个项目上工作一个小时,每次迭代都需要一天的时间,那么每周运行的次数更像你必须充分利用的稀有商品。每天挤出工作时间来思考怎么样改善运行结果,会让人感觉压力非常大。所以转变思路,花几天的时间思考,而不是开始任何运行,直到我对“问题是什么”的假设非常有信心为止。)
要想更多地思考,坚持做更详细的工作日志是非常重要的一环。当进展时间不到几个小时的时候,没有工作日志也无关紧要, 但是如果再长一点的话,你就很容易忘记你已经尝试过的东西,结果只能是在原地打转。 我总结的日志格式是:
Log 1: 我现在在做的有什么具体的输出?
Log 2: 大胆思考,例如关于当前问题的假设,下一步该做什么?
Log 3: 对当前的运行做个记录,并简短地提醒你每次运行应该回答哪些问题。
Log 4: 运行的结果 (TensorBoard 图, 任何其他重要的观察结果), 按运行类型分类 (例如:根据智能体训练时的环境)
一开始,我的日志相对较少,但在项目结束时,我的态度更倾向于“记录我所想的一切”。 虽然付出的时间成本很高,但我认为是值得的,部分原因是有些调试需要相互参照的结果和想法,往往要间隔数天或数周,部分是因为(至少这是我的印象)从大规模升级转变为有效的思维的整体改进。

典型的日志
· · ·
为了将实验成果效益最大化,在实验过程中我做了两件事情,这些事也许会在未来发挥作用。
首先,记录所有指标,这样你能最大限度提升每次运行时收集的证据数量。其中有一些明显的指标,比如训练/验证准确性。当然,用大量时间来头脑风暴,研究其他指标对于诊断潜在的问题也很重要。
我之所以提出这个建议,部分是因为后视偏差,因为我知道应该更早地开始记录哪些指标。很难预测哪些指标在高级阶段会有用。不过,可能有用的策略方法是:
对于系统中的每一个重要组件,考虑一下可以测量什么。如果有一个数据库,测量它在大小上增长的速度。如果有队列,测量处理项目的速度。
对于每一个复杂的过程,测量它的不同部分花了多长时间。如果你有一个训练循环,测量每一批运行所需的时间。如果你有一个复杂的推理过程,测量每个子推理所花费的时间。这些时间对以后的性能调试会有很大帮助,有时还会发现一些其他很难发现的错误。 (例如,如果你看到某些结果的时间越来越长,可能是因为内存泄漏。)
同样,请考虑分析不同组件的内存使用情况。小内存泄漏可以指向各种事情。
另一种策略是观察其他人在衡量什么。在深入强化学习的背景下,John Schulman在他的研究Nuts and Bolts of Deep RL talk(https://www.youtube.com/watch?v=8EcdaCk9KaQ) 中有一些很好的建议。对于策略梯度方法,我发现策略熵是一个很好的指标,它可以很好地反映训练是否再进行,比每一次训练的奖励都要敏感得多。
不健康和健康的策略熵图。失败模式1(左):收敛到常量熵(随机选择一个行为子集);失败模式2(中间):收敛到零熵(每次选择相同的动作)。右:成功的乒乓球训练运行的策略熵
当你在记录的度量中看到一些可疑的东西时,记住要注意困惑,宁愿错误地假设它是重要的东西,而不仅仅把它当做一些数据结构的低效实现。(我忽略了每秒的帧中一个微小但莫名的衰变,从而导致几个月的多线程错误。)
如果能在一个地方看到所有的度量标准,调试就容易得多。我喜欢尽可能多得使用Tensorboard。使用Tensorflow记录度量标准比较困难,所以考虑使用查看easy-tf-log(https://github.com/mrahtz/easy-tf-log),它提供了一个简单的没有任何额外的设置界面的接口 tflog(key, value) 。
第二件看起来很有意义的是花时间尝试和提前预测失败。
多亏了后视偏差在回顾实验时失败原因往往是显而易见的。但真正令人沮丧的是,在你观察到它是什么之前,失败模式已经显而易见了。当你开始训练一个模型,等你第二天回来一看它失败了,甚至在你研究失败原因之前,你就意识到“哦,那一定是因为我忘了设置frobulator”?
简单的是有时你可以提前触发这种半事后认知(half-hindsight-realisation)。它需要有意识的努力,在开始运行之前先停下来思考五分钟哪里可能出错。我认为最有用的脚本是: 2
1、问问自己,“如果运行失败了自己会有多惊讶?”
2、如果答案是“不是很惊讶”,那么设想自己处于未来场景中——这次运行已经失败了,然后问问自己,“如果失败了,哪些地方错了?”
3、修正想到的任何地方
4、重复上述步骤知道问题1的答案是“非常惊讶”(或者至少“要多惊讶有多惊讶”)
总是会有一些你无法预测的错误,并且有时你仍然会忽略一些明显可以避免的错误,但是这个方法至少看起来能够减少一些你会因为没有事先想到而犯的非常愚蠢的错误。
· · ·
最后,该项目最令人惊讶的是花费的时间,以及所需的计算资源。
我最初估计作为一个业余项目,它会耗费3个月的时间。但是实际上它耗费了大约8个月时间。(最初的估计其实已经很悲观了!)部分原因是低估了每个阶段可能花费的时间,但是最大的低估是没有预测到该项目之外出现的其他事情。很难说这个推论有多么严谨,但是对于业余项目来说,将你初始的预估时间(已经悲观估计的)加倍或许是个不错的经验方法。
更令人感到意外的是:每个阶段实际花费的时间。我初始的项目计划中主要阶段的时间表基本如下:
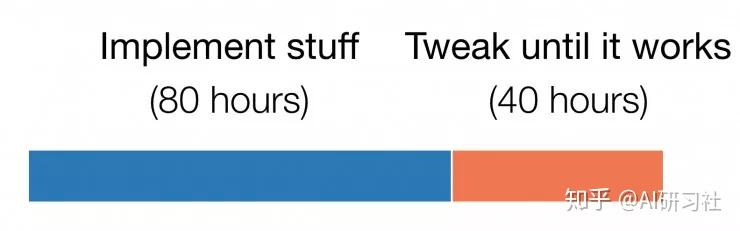
这是每个阶段实际花费的时间
不是写代码花费了很长时间,而是调试代码。实际上,在一个所谓的简单环境上运行起来花费了4倍最初预想的实现时间。(这是第一个我连续花费数小时时间的业余项目,但是所获得的经验与过去机器学习项目类似。)
(备注:从一开始就仔细设计,你想象中强化学习的“简单”环境。尤其是,要仔细考虑:a)你的奖励是否能够真正传达解决任务的正确信息;b)奖励是否只仅依赖之前的观测结果还是也依赖当前的动作。实际上,如果你在进行任意的奖励预测时,后者可能也是相关的,例如,使用一个critic)
另一个是所需的计算资源总量。我很幸运可以使用学校的集群,虽然机器只有 CPU ,但对一些工作来说已经很好了。对于需要 GPU 的工作(如在一些小部分上进行快速迭代)或集群太繁忙的时候,我用两个云服务进行实验:谷歌云计算引擎的虚拟机(https://console.cloud.google.com/projectselector/compute/instances?supportedpurview=project&pli=1)、FloydHub(https://www.floydhub.com/)。
如果你只想通过shell访问GPU机器,谷歌云计算引擎还是不错的,不过我更多是在FloydHub上进行尝试的。FloydHub基本上是一个专门面向机器学习的云计算服务。运行floyd run python awesomecode.py 命令,FloydHub会初始化一个容器,将你的代码上传上去,并且运行你的代码。FloydHub如此强大有两个关键因素:
- 容器预装了GPU驱动和常用库。(甚至在2018年,我仍然在谷歌云计算引擎虚拟机上花费了好几个小时处理更新TensorFlow时CUDA的版本问题。)
- 每次运行都是自动存档的。对于每次运行,使用的代码、用来运行代码的命令、命令行任意输出以及任何输出的数据都会自动保存,并且通过一个网页接口建立索引。
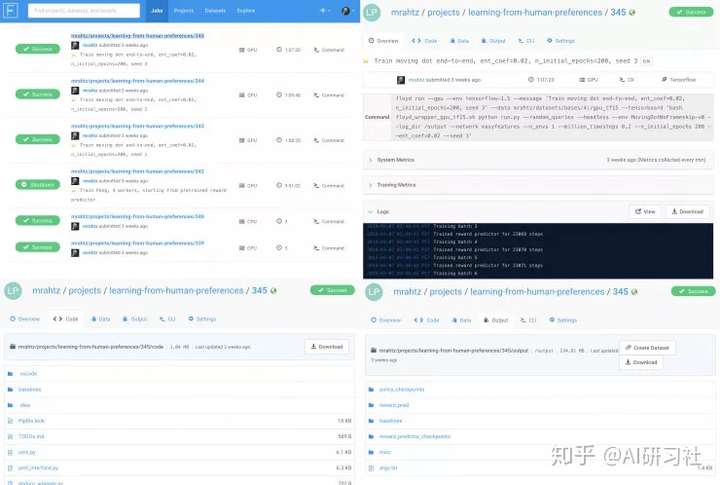
如图为FloydHub的网页接口。上面:历史运行的索引,和单次运行的概观。下面:每次运行所使用的代码和运行输出的任意数据都被自动存档。
第二点的重要程度我难以言表。对于任何项目,这种长期且详细记录操作和复现之前实验的能力都是绝对有必要的。虽然版本控制软件也能有所帮助,但是a)管理大量输出非常困难;b)需要非常勤奋。(例如,如果你开始运行了一些,然后做了一点修改后又运行了另一个,当你提交首次运行的结果时,能否清楚使用了哪份代码?)你可以仔细记笔记或者检查你自己的系统,但是在FloydHub上,它都自动完成压根不需要你花费这么多精力。
我喜欢FloydHub的其他一些方面还有:
- 一旦运行结束,容器会自动关闭。不用担心地查看运行是否完成、虚拟机是否关闭。
- 付费比谷歌云更加直接。比如说你支付了10小时的费用,你的虚拟机立马就被充值了10个小时。这样使得每周的预算更加容易。
我用FloydHub遇到的一个麻烦是它不能自定义容器。如果你的代码有非常多的依赖包,你在每次运行前都需要安装这些依赖包。这就限制了短期运行上的迭代速率。但是,你可以通过创建一个包含安装这些依赖包之后文件系统变更的“dataset”,然后再每次开始运行时都从“dataset”中拷贝出来这些文件解决这个问题(例如 create_floyd_base.sh)。虽然这很尴尬,但仍然比解决GPU驱动问题要好一些。
FloydHub比谷歌云稍微贵一点:FloydHub上一个K80 GPU机器1.2美元/小时,而谷歌云上类似配置的机器只需要0.85美元/小时(如果你不需要高达61G 内存的机器的话费用更低)。除非你的预算真的有限,我认为FloydHub带来的额外便利是值这个价的。只有在并行运行大量计算的情况下,谷歌云才算是更加划算,因为你可以在单个大型虚拟机上运行多个。
(第三个选择是谷歌的新Colaboratory服务,这就相当于提供给你了一个能够在K80 GPU 机器上免费访问的Jupyter笔记本。但不会因为Jupyter而延迟:你可以执行任意命令,并且如果你真的想的话可以设置shell访问。这个最大的弊端是如果你关闭了浏览器窗口,你的代码不会保持运行,而且还有在托管该笔记本的容器重置之前能够运行时间的限制。所以这一点不适宜长期运行,但对运行在GPU上快速原型是有帮助的。)
这个项目总共花费了:
- 谷歌计算引擎上150个小时GPU运行时间,和7700小时(实际时间x核数)的CPU运行时间,
- FloydHub上292小时的GPU运行时间,
- 和我大学集群上 1500 小时的CPU运行时间(实际时间,4到16核)。
我惊讶地发现在实现这个项目的8个月时间里,总共花费了大约850美元(FloydHub上花了200美元,谷歌云计算引擎上花了650美元)。
其中一些原因是我笨手笨脚(见上文慢迭代思想章节)。一些原因是强化学习仍然是如此低效,运行起来需要花费很长时间(每次都需要花费多达10小时的时间来训练一个Pong代理)。
但其中很大一部分原因是我在这个项目最后阶段遇到意外:强化学习可能不太稳定,我们需要使用不同的随机种子重复运行多次以确定性能。
举例来说,一旦我认为基本完成了所有事情,我就会在这个环境上进行端到端测试。但是即使我一直使用最简单的环境,当训练一个点移动到正方形中央上,仍然遇到了非常大的问题。因此我重新回到 FloydHub 进行调整并运行了三个副本,事实证明我认为优秀的超参数在三次测试中只成功了一次。
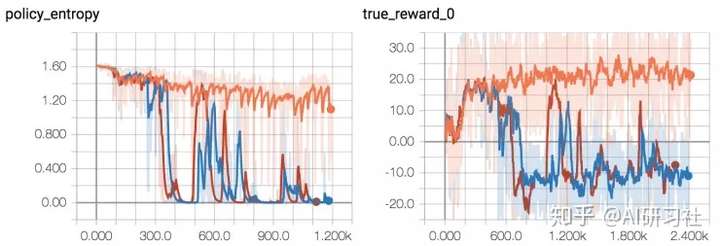
2/3 的随机种子出现失败(红/蓝)并不罕见
对需要的计算量,我给你一个直观的数字:
- 使用 A3C和16名人员,Pong 需要花费 10 小时训练;
- 花费160小时CPU时间;
- 运行3个随机数种子, 需要CPU花费480小时(20天)。
成本方面:
- FloydHub 每小时收费 $0.50 美金,使用8核的设备;
- 所以每运行10小时收费5美金;
- 同时运行3个不同的随机数种子,每运行一次需要花费15美元。
就相当于每验证一次你的想法就需要花费3个三明治的钱。
再次,从 《Deep Reinforcement Learning Doesn’t Work Yet》这篇文章中可以看到,这种不稳定貌似正常也可接受。事实上,即使“ 五个随机种子 (一种通用标准) 可能不足以说明结果有意义, 通过仔细选择,你会得到不重叠的置信区间。”
(突然之间,OpenAI学者计划提供的25,000美元的AWS学分看起来并不那么疯狂,这可能与你给予某人的数量有关,因此计算完全不用担心。)
我的意思是,如果你想要解决一个深入的强化学习项目,请确保你知道你在做什么。确保你准备好需要花费多少时间,花多少钱。
· · ·
总的来说,复现一篇强化学习方面的论文作为业余项目还是很有趣的。反过来看,也可以想想从中学到了什么技能,我也想知道花费几个月时间复现一篇论文是否值得。
另一方面, 我感觉到我在机器学习方面的研究能力并没有很大提升 (回想起来,这实际上是我的目标),反而应用能力得到了提升,研究中相当多的困难似乎会产生出很多有趣和具体的想法;这些想法会让你觉得为此花费的时间是值得的。 产生一个有趣的想法似乎是一个问题 a) 需要大量可供利用的概念, b) 对好的想法或创意拥有敏锐的嗅觉 (例如,什么样的工作会对社区有用)。为了达成以上目的,我认为一个好的做法是阅读有影响力论文,总结并批判性分析这些论文。
所以我认为我从这个项目中得到的主要结论是,无论你是想提高工程技能还是研究技能都值得仔细思考。并不是说没有两者兼得的情况; 但是如果某方面是你的弱项的话,你可以找一个专门针对此项的项目做,来提高你的水平。
如果这两项技能你都想提升,比较好的方法或许是阅读大量论文,寻找你感兴趣且有清晰代码的论文,并尝试实现或扩展它。
· · ·
如果你想做深度强化学习的项目,这里有一些细节需要注意。
找些研究论文来复现
找一些知识点相对单一的论文,避免需要多个知识点协同工作的论文;
强化学习
- 如果你做的项目是将强化学习算法作为大型系统的一部分,不要尝试自己编写强化学习算法,尽管这是一个有趣的挑战,你也可以学到很多东西,但是强化学习目前还不足够稳定,你有可能会无法确定你的系统不工作是因为你的强化学习算法有bug,还是因为你的这个系统有Bug。
- 做任何事之前, 检查如何在你的环境中使用基线算法简化智能体训练。
- 不要忘记标准化观察,这些观察有可能使用在所有地方。
- 一旦你觉得你做出了什么,就尽快写一个端到端的测试。成功的训练可能比你期望的要更脆弱。
- 如果你使用 OpenAI Gym 环境,注意使用 -v0 环境, 有25%的可能,当前的操作被忽略,反而重复之前的操作 (降低环境的确定性)。如果你不希望出现那么多随机性的话,请使用 -v4 环境 。另外注意默认的环境每次只提供给你从仿真器得到的4帧,与早期的DeepMInd论文一致。如果你不想这样的话,请使用 NoFrameSkip 环境。因为这是一个完全稳定的环境,它实际呈现出的和仿真器上给你的完全一致,例如可以使用 PongNoFrameskip-v4。
通用机器学习
- 端到端测试需要运行很长时间,如果后面要进行大规模的重构,你将浪费大量时间。 第一次运行时就做好总比先计算出来然后保存重构留着后面再说要好。
- 初始化一个模块需要花费20秒。比如因为语法错误而浪费时间,确实让人头疼。如果你不喜欢IDE开发环境,或者因为你只能在shell的命令行窗口进行编辑,就值得花时间为你的编辑器创建一个Linter。(对 Vim来说, 我喜欢带Pylint 和 Flake8的ALE. Flake8更像一个格式检查器, 它可以发现Pylint不能发现的问题,比如传递错误参数给某个函数。)不管怎样,花点时间在linter工具上,可以在运行前发现一个愚蠢的错误。
- 不仅仅dropout你要小心,在实现权分享网络中时,你也需要格外小心 - 这也是批规范化。 别忘了网络中有很多规范化统计数据和额外的变量需要匹配。
- 经常看到运行过程中内存的峰值? 这可能是你的验证批量规模太大了。
- 如果你在使用Adam作为优化器使用时看到了奇怪的事情发生,这可能是由于 Adam 的动量参数引起。 尝试使用没有动量参数的优化器,比如RMSprop,或者通过设置 β1 =0 屏蔽动量参数。
TensorFlow
- 如果你想调试看计算图中间的一些节点发生了什么,使用 tf.Print,可以将每次运行的输入值打印出来。
- 如果你正在保存推断的检查点,你可以通过忽略优化器参数来节省大量空间。
- session.run() 很烧钱。尽量批量调用。
- 如果您在同一台机器上运行多个TensorFlow实例时,会出现GPU内存不足的错误, 这很可能是因为其中一个实例试图占用所有内存空间导致的,并不是因为你的模型太大。这是TensorFlow的默认做法,你需要告诉TensorFlow只按需使用内存空间,可以参考 allow_growth 操作。
- 如果你想在正在运行的的很多东西的时候,及时访问一个图表,就像你从多个进程访问同一个图表一样,但是有一种锁只允许同一时间只能有一个进程进行进行相关操作。这似乎与Python的全局解释锁明显不同,TensorFlow会在执行繁重工作前释放锁。对此我不敢确定,也没有时间做彻底调试。但如果你也遇到相同状况,可以使用多进程,并用分布式TensorFlow将图表分复制每个进程,将会比较简便。
- 使用Python不用担心溢出,但应用TensorFlow时,你就需要格外小心了:

当不能使用GPU时,请注意使用 allow_soft_placement 切换到CPU。如果你偶尔写的代码无法在GPU上运行时,它可以平滑切换到CPU。例如:

我不清楚有多少像这样无法在GPU上运行的操作,但安全起见,手动切换到CPU,例如:

健康的心理
- 不要对TensorBoard上瘾。 我是认真的。这是一个关于不可预知的奖励上瘾的完美例子:你检查自己的操作是如何运行的时候,而且它在不停的运行,有时检查时你会突然中大奖!这是件超级兴奋的事。 如果你每过一段时间就有检查 TensorBoard 的冲动,这时对你来说,应该设置一个规则,规定合理的检查时间间隔。
· · ·
如果你毫不犹豫地读了这篇文章,那就太棒了!
如果你也想进入深度强化学习领域,这里有一些资源供你入门时参考:
- Andrej Karpathy的 Deep Reinforcement Learning: Pong from Pixels 是一份关于建立动机和直觉方面很好的介绍文章。
- 想了解更多关于强化学习方面的理论,可以参考 David Silver的演讲 。这篇演讲没有过多关于深度强化学习的内容( 基于神经网络的强化学习 ),但至少教会了你很多词汇,帮助你理解相关论文。
- John Schulman的 Nuts and Bolts of Deep RL talk 有很多实际应用方面的建议,这些问题你在后面都可能遇到。
想了解目前深度强化学习领域发生了什么,可以参考一下这些内容:
- Alex Irpan的 Deep Reinforcement Learning Doesn’t Work Yet 对目前的状况有一个很好的概述。
- Vlad Mnih的 Recent Advances and Frontiers in Deep RL ,有很多关于实际例子,用以解决 Alex 文章中提到的问题。
- Sergey Levine的 Deep Robotic Learning 谈话,聚焦改善机器人的泛化和样本效率问题。
- Pieter Abbeel 在2017 NIPS会议上 Deep Learning for Robotics 主题演讲, 提到很多最新的深度强化学习技术。