原文 : A Review of Relational Machine Learning for Knowledge Graphs
1. Introduction
- Statistical Relational Learning
目的 : 预测边, 预测node的属性, 对node进行聚类 - 与KB的结合
- 从既有事实中推理出新的关系
- 结合信息抽出的方法, 从语料库中抽出新的"noisy" 事实(即无法百分百确定的事实.)
- 章节结构
- 介绍知识图谱和其属性(第二章)
- 讨论SRL相关和将其应用到KB的方法.(第三章)
- 利用潜在变量找到nodes/edges之间的关系.(第四章)
- 根据图的统计信息直接找到nodes/edges之间的关系.(第五章)
- 上面两种方法的结合(第六章)
- 将上面各种model如何在KG上训练(第七章)
- 利用马尔科夫随机场的推理(第八张
- 如何将SRL应用于知识图谱构建(第九章)
- 现有模型的扩展.
2. KNOWLEDGE GRAPHS
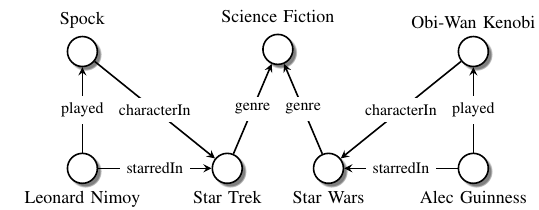
2.1 Knowledge representation
知识图谱的基本结构是 SPO : (subject, predicate, object) (SPO) triples
比如:
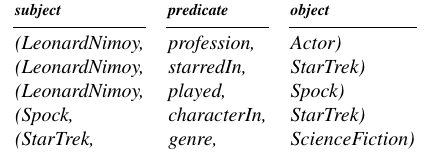
这个就叫做 知识图谱, 有时候也叫作 异质信息网络.
知识图谱有一定的规则:
- Type具有层级性. (Type 包括 Entity Type和Relation Type)
- Type之间包含着约束. (包括Entity Type和Entity Type之间的约束, Relation Type和Entity Type之间的 和 Relation Type和Relation Type之间的)
2.2 Open vs. closed world assumption
- Closed world assumption : KB是完美的, 没有错误.
- Open world assumption : KB中含有很多没有的链接.
2.3 Knowledge base construction
注意这里是知识图谱的构建, 而不是补全. 进行了以下的分类:
- Curated approaches : 专家构建
- Collaborative approaches : 志愿者参与构建(常识性的关系)
- Automated semi-structured approaches : 从结构化文本中进行构建的知识库. 通常具有相当高的正确率
- Automated unstructured approaches : 从非结构性文本中利用机器学习构建. 这个就是关系抽出的任务, 在第九章讲.
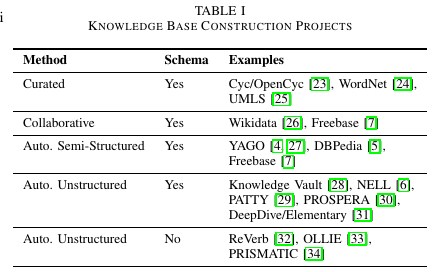
知识图谱还根据 Entity和Relation的选用范围是否被限定来对KB进行分类.
- schema-based : Entity和Relation都是固定的.
- schema-free : Entity和Relation都没有确定. 是开放的, 但是有一个坏处是, 这里是按照字符进行储存的,
会造成信息重复, 比如在这里, (“Obama”, “born in”, “Hawaii”), (“Barack Obama”,“place
of birth”, “Honolulu”), 会被当做两个完全不同的triple来对待.
这篇文章我们聚焦于schema-based Knowledge Base.
2.4 Uses of knowledge graphs
一些应用, 包括指代消解, 信息去冗余, QA.
2.5 Main tasks in knowledge graph construction and curation
几个经典的Knowledge Graph构建任务
- Link prediction( knowledge graph completion) : 即预测已经存在的边, 这个能力可以用来发现未知的边.
- Entity resolution: 由于Entity具有层级性, 如果将同属于高一级的低级node合并, 其关系却不能合并,
这样Knowledge Graph就会存在多个相同的点, 而在给定具体的句子时我们需要确定句子中实体在Knowledge
Graph中的位置.例子见下图, 其中 A.Guinners是高级node, 其可以代表 Arthur Guinness 和 Alec Guinness:

- Link-based clustering
就是说根据link来对点进行分类, 比如社交网络中的团体分类.
3. SRL For Knowledge Graph
3.1 定义
Statistical Relational Learning : 是指利用关系数据的统计模型, 并没有指定问题.
接下来的分析基于Knowledge Graph的种类是 :
- Open world assumption : Knowledge Graph中所有信息都是已知的(和没说一样), 但是triples中还有未完成的链接和噪声.
- Entity和Type会由于层级性的存在, 存在重复. 如2.5.2 所示.
这一章的主要内容是对Knowledge Graph进行数据建模.
3.2 Notation
这里的符号过于多, 但是都很容易懂, 看论文即可.
3.3 Probabilistic knowledge graphs
这一节重要讲了建模的方法.
如果采样三阶tensor的方法, 每个位置都是0/1的方式去储存Knowledge Graph的话, 那么要求的时间复杂度和空间复杂度都是
O(n^3), 这对于拥有大量实体和关系的Knowledge Graph是不切实际的, 因此需要用 Type 之间的
constriant来进行限制.
理想的, 一个好的 Relation Model 应该是可以 O(max(entity_num, relation_num)) 的.
3.4 Statistical properties of knowledge graphs
3.4.1 Constriant
Type 之间的 constriant.
硬式constriant : 传统的 constriant 是硬式的, 即如A的出身是东北, 东北又属于中国, 那么A的出身也是中国.
软式constriant(homophily) : 但是也还有一些在全局看来不正确但是有很强约束效果的约束条件.比如 拥有相似性质Entity更有可能连在一起, 美国演员更有可能参演美国的电影.
3.4.2 Block structure
entity可以先按照某种属性分成很多Block. 在Block和Block之间具有高度密集连接的现象成为Block structure.
这里其实有点聚类的感觉, 在一个Block中的Entity其实有相似的某个性质, 而两个密集连接的Block是说,
这两个Block所代表的性质具有认知上的连接关系. 文中给出的例子是, 科幻演员的Block和科幻电影Block之间的连接紧密.
3.4.3 Global and long-range statistical dependencies
简单来说, 就是Entities和Relations的组合 $((E_{1s},R_1,E_{1e}),...,(E_{ns},R_n,E_{ne}))$ 存在pattern, 比如说, 在东北出生的人A, 有很大概率A的爸爸B有东北的户口.
这类组合中蕴含着丰富的信息.
3.4.4 Skewed
对于我们的讨论对象, Imcomplete Knowledge Graph, 其中的连接是有偏向的.
比如, 在维基的Knowledge Graph中就很少会有 A是B 的独生子这种关系.
3.5 Types of SRL models
1) 基础模型的分类
SRL的定义是 : 对关系数据的统计学建模.
那么首先要看有什么关系, 关系在统计中的表现就是条件概率, 文中指出三种条件概率来指导的三种基础模型, 之所以成为基础是因为这三者可以进行叠加组合:
- Latent feature models
$P(y_{i,j,k})=f(subject, object, relation, heta)$
对应第四章, 假设除了一些图中没有的特征, 基于这些进行推理, 有点像贝叶斯派的做法. - Graph feature models
$P(y_{i,j,k})=f(Graph_features, heta)$
对应第五章 , 只基于图中已有信息进行基于统计的推理, 有点类似与概率派的做法. - Markov Random Fields
假设 $y_{ijk}$ 有局部交互性, 即之后最近的连接node和edge有关.
$P(y_{i,j,k})=f(node_{m},edge_{n}, heta)$ 其中, node_m 是与目标位置连接的点, edge_n 是与目标位置连接的边.
第三个模型具有较强的限制性一般的模型都没有采用这个假设, 但是这个对于确定的关系网络还是很有效的, 具体在第八章讲解. 接下来我们主要集中于前两个模型的融合.
2). 两个模型的融合
公式如下 :
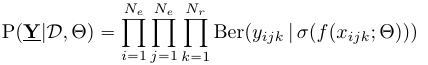
这个里面的 $Theta$ 是中的潜在变量, $mathcal{D}$ 是所有已知的triples, 也就是graph(从中可以提出Graph features).
其中, 用到了伯努利分布和sigmod函数.
这个公式就叫做概率模型.
3). 其他模型
Score-based models
除了基于条件概率的概率模型, 还可以制定基于几何的 score-based models模型, 即最大化existing model和 non-existing model 之间距离的模型, 在 CoType 中就用到了这个模型(因为那个模型要把Entity和Type映射到向量空间去, 符合几何的概念)
4. Latent Feature Model
这里对应的是上面的那个公式, 这里的潜在特征就是 $Theta$.
这个模型的intuition是, 模型中的关系的连接都是依靠Entity内在特征的属性来进行推理的. 因此这里的 Latent Features 指的是 Entity的内在特征.
4.1 Rescal: A bilinear model
4.1.1 模型形式
这个模型的思想是用一个转换矩阵去连接两个实体向量, 而实体向量的意义是, 对于一个实体而言, 向量中的每一维都代表着这个实体的某个 Latent Feature 信息.
公式如下:
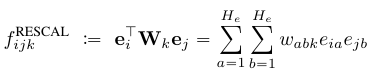
处理的对象是邻接张量, 张量的形式为 :
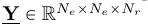
4.1.2 一个具体的例子
用一个实际的例子去解释, 用论文中给出的演员获奖的例子.
设Entity Embedding的第一维代表这个实体是不是一个好演员的指标, 如果是, 这个值就大, 反之则小.
设第二维代表的是, 这个实体是不是一个权威的关于演技奖项. 比如, 实体"奥斯卡奖"的这一维就大, 实体"金酸梅奖"的这一维就小. 现在我们给出两个实际的例子.

第一个实体是一个著名的演员(参演星球大战), 第二个是一个权威奖项.
我们知道, 好演员会拿大奖 是一个Latent Feature,即我们知道存在这种关系, 但是图中并没有明确表示出来. 那么, 我们看看表现映射 好演员应该拿大奖 的Latent Feature信息的矩阵, 代表的是什么:

注意 : 一个关系对应着一个关系矩阵
这个里面的第一项说的是, 左边第一维和右边第一维的关系, 即好演员和好演员, 虽然好演员和好演员是有偏向于合作的关系的, 但这个信息不是 好演员会拿大奖 这个关系矩阵所需要反应的, 因此这个地方为0.1, 也就是对这个预测没有太大关系.
这个里面第二项说的是, 左边第一维和右边第二维的关系, 即好演员和大奖, 这个是有对于 好演员会拿大奖 这一个 Relation 帮助最大的信息, 因此这个值要占很大.
4.1.3 转换矩阵的本质
这个转换矩阵的拥有, 我们对于Knowledge Graph各种property的建模. (Knowledge Graph的property见3.4)
- Block property : 每个entry代表的是Block, 比如i-j的值, 指的是 拥有好演员性质实体组成的的Block 和 拥有大奖属性的实体组成的Block 之间具有密集连接性.
- Homophily : 指的是拥有相同属性的两个实体, 即两个实体的第i维都大的实体倾向于连接在一起. 比如说, 表达 好演员倾向于和好演员一起演戏 这个信息的矩阵的话, 就能体现网络中的Homophily性. 这个矩阵中就会有大的对角线值.
- Anti-correlations : 不倾向于连接在一起的的维度i,j, 体现在矩阵中是, $W_{ij}$ 为负数.
4.1.4 潜在变量是?
讲了这么多, 那么潜在变量是什么呢? 是实体变量和关系矩阵的集合.即:
4.1.5 几个更为重要的性质
下面开始介绍这个模型的几个更为重要的性质
1) Relational learning via shared representations
虽说每次的训练都只更新一部分信息, 但是由于更新的一部分信息还是会在之后的训练中起作用, 因此信息是可以在全局传递的, 其实这部分的特性基本上没有解释的意义. 可以忽视.
2) Semantic embedding
由于在知识图谱中实体的语义就是由其相连的实体和edge的类型决定的, 因此这个训练过程可以训练出实体的语义向量. 这个性质支持了对Entity和Relation的聚类.
3) Connection to tensor factorization
就是说这个方法本质是邻接张量分解, 其图解是:
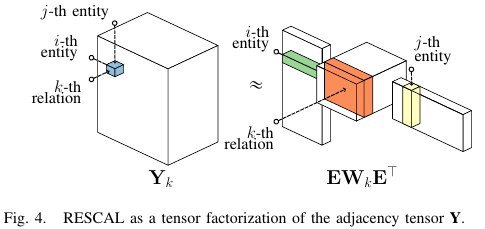
这个后面可以用来设计高效的参数估计算法.
4) 模型优化
一般有两种方法, 梯度下降法 和 基于score的方法, 因为这个模型的核心公式是可以进行张量分解的, 因此可以用 scored-based model 来优化, 因此速度很快.
5) Decoupled Prediction
就是说正向预测的时间和graph大小无关, 只和graph中Latent feature的数量有关.
6) Relational learning results
这个模型可以实现最佳效果.
4.2 Other tensor factorization models
介绍了很多使用张量分解的模型, 其中比较有意思的一个是 discrete latent factors.
模型叫做 Boolean tensor factorization , 邻接张量, (即表示图的张量)基于布尔代数, 被分解为布尔向量.
4.3 Matrix factorization methods
这个是将邻接张量变成了邻接向量,
邻接张量的公式是 :
邻接向量的公式是 :
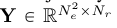
4.4 Multi-layer perceptrons
4.4.1 单层神经网络
当然少不了神经网络了.神经网络的方法如下:
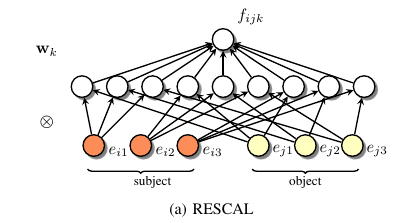
这个方法很简单, 问题在于, 如果把神经网络当做是 RESCAL 的转换来看的话, 那么模仿关系矩阵的隐藏层 $w_k$ 将需要大量的node, 因为在 RESCAL 中的 $W_i$ 就是由大量参数组成的, 并且每个关系向量都需要有一个这样的模型.
4.4.2 E-MLP
为了解决这个问题, 可以使用多层感知机, 如下(从下向上):
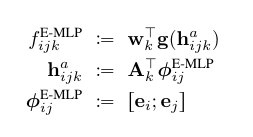
这里由于分了两层, 那么就有一层可以为Latent Feature之间的交互留下了空间. 这个还有和上面一样的过多参数的问题.
4.4.3 ER-MLP
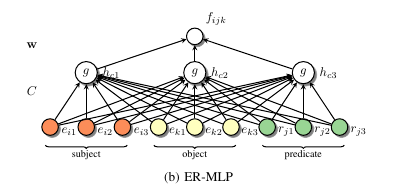
将关系本身也作为了向量. 这个模型很好的捕捉到了实体和关系之间的语义.
4.5 Neural tensor networks
将tensor分解和神经网络的结合的模型, 叫做NTN.
方法如下:
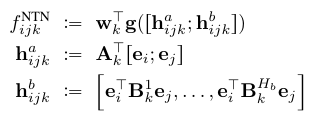
其中 $h_{ijk}^b$ 就是用的 tensor.
其中 $h_{ijk}^a$ 就是用的神经网络法, A的符号看上面就知道了
由于参数过多, 出现过拟合.
4.6 Latent distance models
这个模型通过距离函数来进行优化.
对两个实体之间的连接用距离函数进行建模, 距离是欧式距离这种(也会有其他的).
4.6.1 SE模型
这是最开始的模型. 目标公式如下:
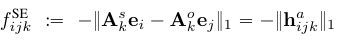
其中k是关系的数量, 也就是说对于每一个关系都对应着两个矩阵. 为了减少参数的量, 有了大名鼎鼎的TransE模型.如下:
4.6.2 TransE模型
就是很简单的一个基于空间向量距离的目标函数.
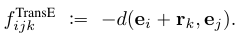
然后基于这个有了各种各样的变种, 其中有一个目标函数为:

4.7 模型对比

在不同的数据上的最佳模型不同, 一个研究显示, RESCAL拥有比较好的属性, 但是文中没有将其与TransE 的数个变种进行比较, 因为TransE本身就是一个基本模型, 其后面还有很多很多变种.
5. GRAPH FEATURE MODELS
直接利用图中信息的方法, 比如我们可以从 A,B是C的父母得知, AB是夫妻. 这个过程中只用到了Graph本身的信息. 而没有潜变量这些.
5.1 Similarity measures for uni-relational data
单向关系数据的相似度计算, 这个适用于只有一种关系的数据.
判断一个点和另外的点是否有链接, 可以通过判断与他们相连的点之间的连接是否紧密.
比如, Hitting Time, Commute Time, and PageRank. 这种利用全局信息的算法比只利用本地信息的算法好.
5.2 Rule Mining and Inductive Logic Programming
intuition是, 从现有的数据中抽出rules, 然后利用rules去发现新的link.
抽取到的信息可以作为 Markov logic 的基础(不懂).
比如说, ALEPH 就是一个Inductive Logic Programming (ILP) system可以从关系数据中学得rules通过 inverse entailment. 更多详情见相关论文. 之后有介绍了一个AMIE的规则挖掘系统.
基于规则发掘的模型具有很强的可解释性, 这个是全局方法, 但是由于真实世界中规则都有一定的范围, 因此很难发现有效的规则.
5.3 Path Ranking Algorithm
简称 PRA, 一类通过随机walk来发现组合路径的算法, 没有兴趣看, 忽略.
6. 两者的组合
两者的优点是互相补充的, 两者的特点是:
- 基于潜变量的方法
通过潜变量来对全局关系模式建模. 在前提假设成立的情况下, 可以在小数据下获得不错的结果. - 基于全局特征的方法
可以对局部或者拟局部的图的模式进行建模.
两者互补的例子:
对于一种大量的且硬式无法体现在实体表征的关系来说, 使用潜变量法会比较难以发现.
比如说, 夫妻关系, 一个人与一个人是否是夫妻关系, 这个基本无法靠两个人的实体特征去发现, 因为这个特征过于局部, 没办法单独作为一个属性,出现在实体的特征里.
而夫妻关系却可以通过, [他们有共同的孩子] 这一点,即表现于图本身的路径的pattern的识别, 来进行判断. 因此两者的融合特别重要.
6.1 Additive relational effects model
将RESCAL和PRA进行组合的方法 - additive relational effects (ARE).
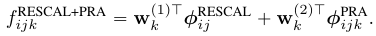
6.2 Other combined models
个人认为之前看过的那篇利用自动变分编码器进行物理动力学系统建模的论文也属于这个类别.
介绍一个模型:

前两项都比较好理解, 就是对Entity1和Entity2的编码, 重点是第三个, 根据第二个式子可以知道, 这个是编码了 ( [并非这个Relation的] Entity1和Entity2的 其他关系) 进入模型中.