目标检测一直是计算机视觉的基础问题,在 2010 年左右就开始停滞不前了。自 2013 年一篇论文的发表,目标检测从原始的传统手工提取特征方法变成了基于卷积神经网络的特征提取,从此一发不可收拾。
本文将跟着历史的潮流,简要地探讨「目标检测」算法的两种思想和这些思想引申出的算法,主要涉及那些主流算法,no bells and whistles.
概述 Overview
在深度学习正式介入之前,传统的「目标检测」方法都是 区域选择、提取特征、分类回归 三部曲,这样就有两个难以解决的问题;其一是区域选择的策略效果差、时间复杂度高;其二是手工提取的特征鲁棒性较差。
云计算时代来临后,「目标检测」算法大家族主要划分为两大派系,一个是 R-CNN 系两刀流,另一个则是以 YOLO 为代表的一刀流派。下面分别解释一下 两刀流 和 一刀流。
两刀流
顾名思义,两刀解决问题:
1、生成可能区域(Region Proposal) & CNN 提取特征
2、放入分类器分类并修正位置
这一流派的算法都离不开 Region Proposal ,即是优点也是缺点,主要代表人物就是 R-CNN系。
一刀流
顾名思义,一刀解决问题,直接对预测的目标物体进行回归。
回归解决问题简单快速,但是太粗暴了,主要代表人物是 YOLO 和 SSD 。
无论 两刀流 还是 一刀流,他们都是在同一个天平下选取一个平衡点、或者选取一个极端—— 要么准,要么快。
两刀流的天平主要倾向准,
一刀流的天平主要倾向快。
但最后万剑归宗,大家也找到了自己的平衡,平衡点的有略微的不同。
接下来我们花开两朵各表一支,一朵 两刀流 的前世今生,另一朵 一刀流 的发展历史。
两刀流 R-CNN
R-CNN 其实是一个很大的家族,自从 rbg 大神发表那篇论文,子孙无数、桃李满天下。在此,我们只探讨 R-CNN 直系亲属,他们的发展顺序如下:
R-CNN -> SPP Net -> Fast R-CNN -> Faster R-CNN -> Mask R-CNN
其实说句良心话,最佩服的并不是 rbg 大神,而是提出了 SPP Net 的以何恺明为主的作者们。
他们在整个家族进化的过程中,一致暗埋了一条主线:充分榨干 feature maps 的价值。
R-CNN / 2013
论文:Rich feature hierarchies for accurate object detection and semantic segmentation
这篇论文,这个模型,是利用卷积神经网络来做「目标检测」的开山之作,其意义深远不言而喻。
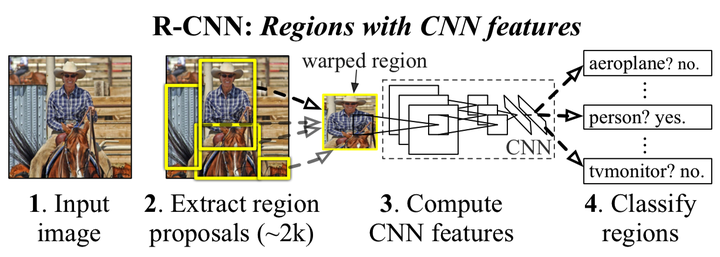
解决问题一、速度
传统的区域选择使用滑窗,每滑一个窗口检测一次,相邻窗口信息重叠高,检测速度慢。R-CNN 使用一个启发式方法(Selective search),先生成候选区域再检测,降低信息冗余程度,从而提高检测速度。
解决问题二、特征提取
传统的手工提取特征鲁棒性差,限于如颜色、纹理等 低层次(Low level)的特征。
该方法将 PASCAL VOC 上的检测率从 35.1% 提升到 53.7% ,提高了好几个量级。虽然比传统方法好很多,但是从现在的眼光看,只能是初窥门径。
SPP Net / 2014
论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
R-CNN 提出后的一年,以何恺明、任少卿为首的团队提出了 SPP Net ,这才是真正摸到了卷积神经网络的脉络。也不奇怪,毕竟这些人鼓捣出了 ResNet 残差网络,对神经网络的理解是其他人没法比的。
尽管 R-CNN 效果不错,但是他还有两个硬伤:
硬伤一、算力冗余
先生成候选区域,再对区域进行卷积,这里有两个问题:其一是候选区域会有一定程度的重叠,对相同区域进行重复卷积;其二是每个区域进行新的卷积需要新的存储空间。
何恺明等人意识到这个可以优化,于是把先生成候选区域再卷积,变成了先卷积后生成区域。“简单地”改变顺序,不仅减少存储量而且加快了训练速度。
硬伤二、图片缩放
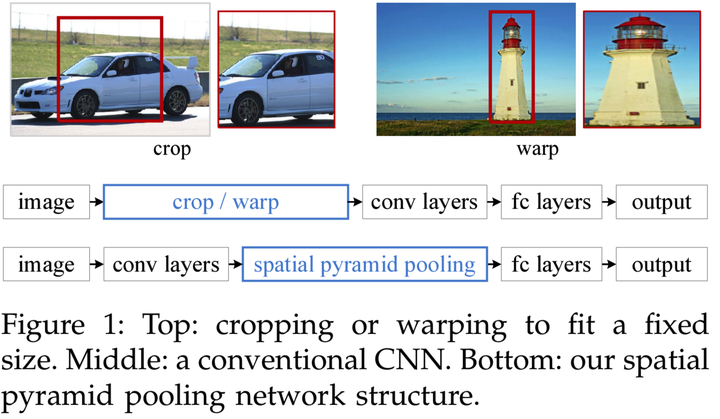
无论是剪裁(Crop)还是缩放(Warp),在很大程度上会丢失图片原有的信息导致训练效果不好,如上图所示。直观的理解,把车剪裁成一个门,人看到这个门也不好判断整体是一辆车;把一座高塔缩放成一个胖胖的塔,人看到也没很大把握直接下结论。人都做不到,机器的难度就可想而知了。
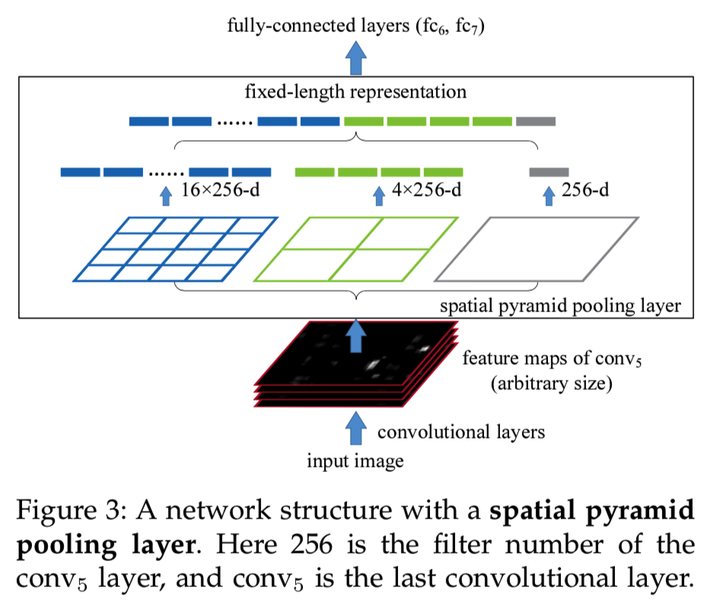
何恺明等人发现了这个问题,于是思索有什么办法能不对图片进行变形,将图片原汁原味地输入进去学习。
最后他们发现问题的根源是 FC Layer(全连接层)需要确定输入维度,于是他们在输入全连接层前定义一个特殊的池化层,将输入的任意尺度 feature maps 组合成特定维度的输出,这个组合可以是不同大小的拼凑,如同拼凑七巧板般。
举个例子,我们要输入的维度 ,那么我们可以这样组合
。
SPP Net 的出现是如同一道惊雷,不仅减少了计算冗余,更重要的是打破了固定尺寸输入这一束缚,让后来者享受到这一缕阳光。
注:这个时候 FCN 还没有出现,FCN 是同年 11 月发表的,SPP Net 是 4 月发表的。
Fast R-CNN / 2015
论文:Fast R-CNN
此时,我们的 rbg 大哥也按耐不住了——自己家的孩子,自己养大——于是憋出了一个大招 Fast R-CNN 。取这个名字的意思就是“儿子比爸爸强”,相对于原来的 Slow R-CNN,做了速度上的优化——就是快。
在这篇论文中,引用了 SPP Net 的工作,并且致谢其第一作者何恺明的慷慨解答。
纵观全文,最大的建树就是将原来的串行结构改成并行结构。
改进:流水线
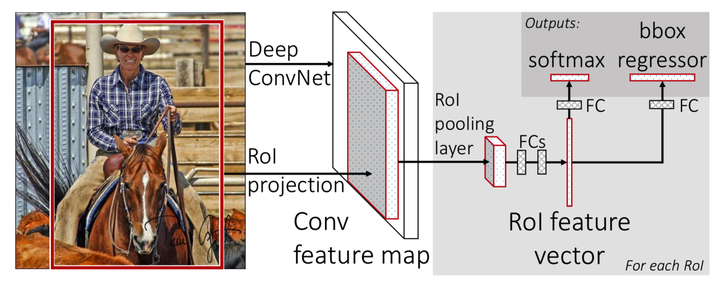
原来的 R-CNN 是先对候选框区域进行分类,判断有没有物体,如果有则对 Bounding Box 进行精修 回归 。这是一个串联式的任务,那么势必没有并联的快,所以 rbg 就将原有结构改成并行——在分类的同时,对 Bbox 进行回归。
这一改变将 Bbox 和 Clf 的 loss 结合起来变成一个 Loss 一起训练,并吸纳了 SPP Net 的优点,最终不仅加快了预测的速度,而且提高了精度。
Faster R-CNN / 2015
论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
众人拾柴火焰高,原来 SPP Net 的人马和 rbg 一起研究憋大招,在 rbg 和 何恺明 绽放完光芒后,任少卿 老哥发出了太阳般的光芒——RPN 的概念让人不得不服。
神经网络一统天下
在 Faster R-CNN 前,我们生产候选区域都是用的一系列启发式算法,基于 Low Level 特征生成区域。这样就有两个问题:
第一个问题 是生成区域的靠谱程度随缘,而 两刀流 算法正是依靠生成区域的靠谱程度——生成大量无效区域则会造成算力的浪费、少生成区域则会漏检;
第二个问题 是生成候选区域的算法是在 CPU 上运行的,而我们的训练在 GPU 上面,跨结构交互必定会有损效率。
那么怎么解决这两个问题呢?
于是乎,任少卿等人提出了一个 Region Proposal Networks 的概念,利用神经网络自己学习去生成候选区域。
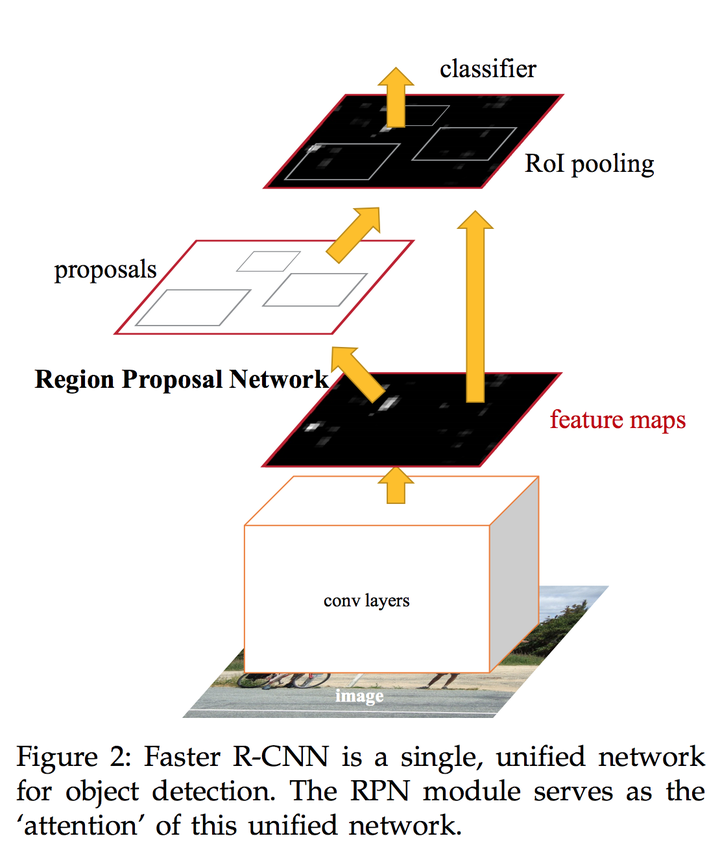
这种生成方法同时解决了上述的两个问题,神经网络可以学到更加高层、语义、抽象的特征,生成的候选区域的可靠程度大大提高;可以从上图看出 RPNs 和 RoI Pooling 共用前面的卷积神经网络——将 RPNs 嵌入原有网络,原有网络和 RPNs 一起预测,大大地减少了参数量和预测时间。
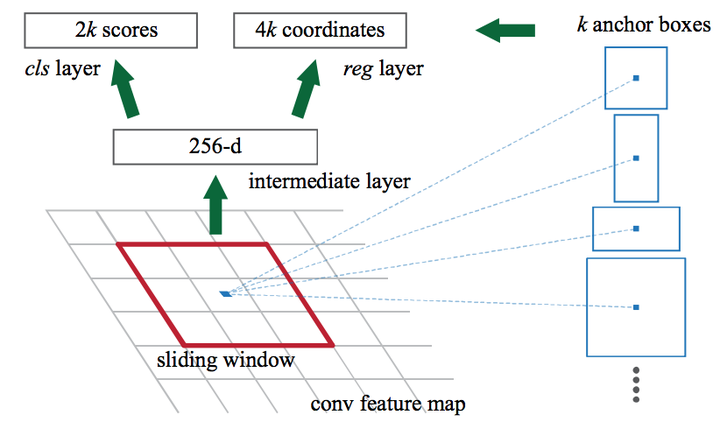
在 RPNs 中引入了 anchor 的概念,feature map 中每个滑窗位置都会生成 k 个 anchors,然后判断 anchor 覆盖的图像是前景还是背景,同时回归 Bbox 的精细位置,预测的 Bbox 更加精确。
将 两刀流 的两刀并入同一个网络,这一操作足够载入史册了。
Mask R-CNN / 2017
论文:Mask R-CNN
时隔一年,何恺明团队再次更新了 R-CNN 家族,改进 Faster R-CNN 并使用新的 backbone 和 FPN 创造出了 Mask R-CNN 。
加一条通道
我们纵观发展历史,发现 SPP Net 升级为 Fast R-CNN 时结合了两个 loss ,也就是说网络输入了两种信息去训练,结果精度大大提高了。何恺明他们就思考着再加一个信息输入,即图像的 Mask ,信息变多之后会不会有提升呢?
于是乎 Mask R-CNN 就这样出来了,不仅可以做「目标检测」还可以同时做「语义分割」,将两个计算机视觉基本任务融入一个框架。没有使用什么 trick ,性能却有了较为明显的提升,这个升级的版本让人们不无啧啧惊叹。
作者称其为 meta algorithm ,即一个基础的算法,只要需要「目标检测」或者「语义分割」都可以使用这个作为 Backbone 。
小结 / 2018
我们再总结一下 R-CNN 的发家史:
从平台上讲

一开始的跨平台,到最后的统一到 GPU 内,效率低到效率高。
从结构上讲
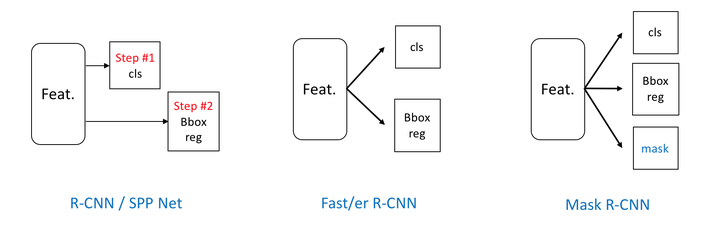
一开始的串行到并行,从单一信息流到三条信息流。
从最开始 50s 一张图片的到最后 200ms 一张图片,甚至可以达到 6 FPS 的高精度识别,无不彰显着人类的智慧。
一刀流 YOLO & SSD

一刀流的想法就比较暴力,给定一张图像,使用回归的方式输出这个目标的边框和类别。一刀流最核心的还是利用了分类器优秀的分类效果,首先给出一个大致的范围(最开始就是全图)进行分类,然后不断迭代这个范围直到一个精细的位置,如上图从蓝色的框框到红色的框框。
这就是一刀流回归的思想,这样做的优点就是快,但是会有许多漏检。
YOLO / 2015
论文:YOLO

YOLO 就是使用回归这种做法的典型算法。
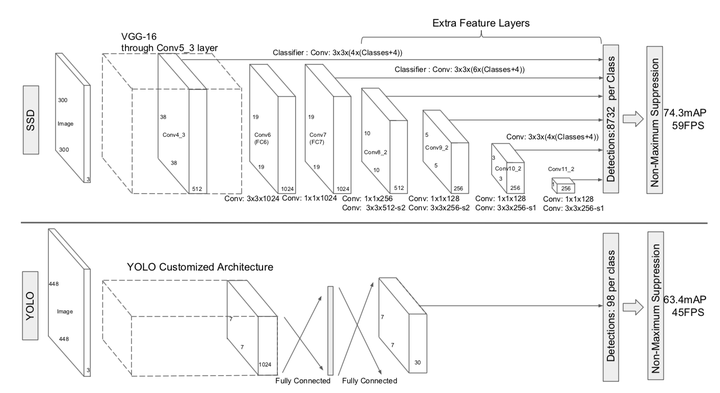
首先将图片 Resize 到固定尺寸,然后通过一套卷积神经网络,最后接上 FC 直接输出结果,这就他们整个网络的基本结构。
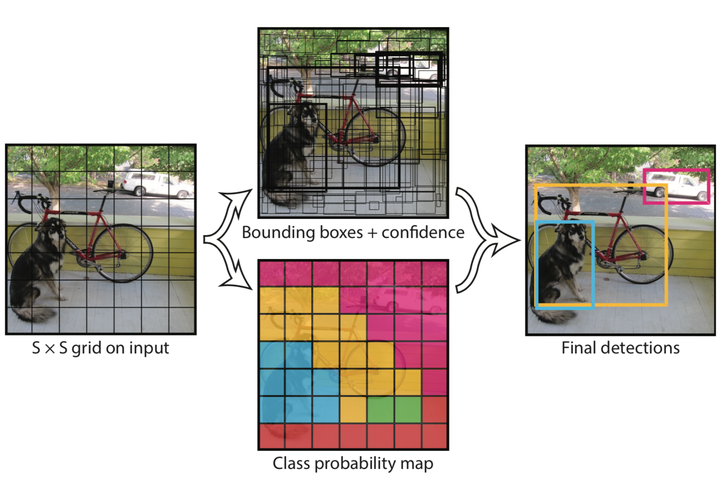
更具体地做法,是将输入图片划分成一个 SxS 的网格,每个网格负责检测网格里面的物体是啥,并输出 Bbox Info 和 置信度。这里的置信度指的是 该网格内含有什么物体 和 预测这个物体的准确度。
更具体的是如下定义:
我们可以从这个定义得知,当框中没有物体的时候,整个置信度都会变为 0 。
这个想法其实就是一个简单的分而治之想法,将图片卷积后提取的特征图分为 SxS 块,然后利用优秀的分类模型对每一块进行分类,将每个网格处理完使用 NMS (非极大值抑制)的算法去除重叠的框,最后得到我们的结果。
SSD / 2015
论文:SSD
YOLO 这样做的确非常快,但是问题就在于这个框有点大,就会变得粗糙——小物体就容易从这个大网中漏出去,因此对小物体的检测效果不好。
所以 SSD 就在 YOLO 的主意上添加了 Faster R-CNN 的 Anchor 概念,并融合不同卷积层的特征做出预测。
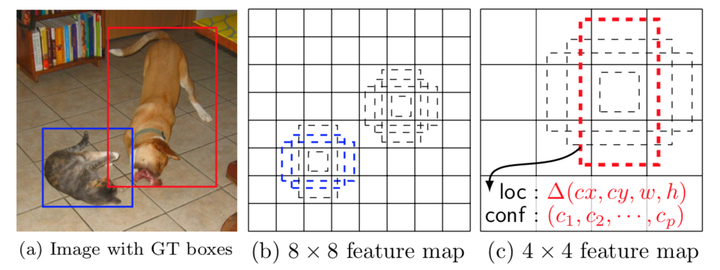
我们从上图就可以很明显的看出这是 YOLO 分治网络 和 Faster R-CNN Anchor 的融合,这就大大提高了对小物体的检测。这里作者做实验也提到和 Faster R-CNN 一样的结果,这个 Anchor的数量和形状会对性能造成较大的影响。
除此之外,由于这个 Anchor 是规整形状的,但是有些物体的摆放位置是千奇百怪的,所以没有 数据增强 前的效果比增强后的效果差 7 个百分点。直观点理解,做轻微地角度扭曲让 Anchor背后的神经元“看到”更多的信息。
还有一个重大的进步是结合了不同尺寸大小 Feature Maps 所提取的特征,然后进行预测。这是 FPN 网络提出前的第一次做 Feature Pyramid 的尝试,这个特征图金字塔结合了不同层的信息,从而结合了不同 尺寸 和 大小 的特征信息。
这个尝试就大大地提高了识别的精度,且高分辨率(尺寸大)的 Feature Map 中含有更多小物体的信息,也是因为这个原因 SSD 能够较好的识别小物体。
除此之外,和 YOLO 最大的区别是,SSD 没有接 FC 减少了大量的参数量、提高了速度。
YOLO9000 / 2016
论文:YOLO9000
到了 SSD ,回归方法的目标检测应该一统天下了,但是 YOLO 的作者不服气,升级做了一个 YOLO9000 ——号称可以同时识别 9000 类物体的实时监测算法。
讲道理,YOLO9000 更像是 SSD 加了一些 Trick ,而并没有什么本质上的进步:
- Batch Normalization
- High resolution classifier 448*448 pretrain
- Convolution with anchor boxes
- Dimension clusters
- Multi-Scale Training every 10 batch {320,…..608}
- Direct location prediction
- Fine-Grained Features
加了 BN 层,扩大输入维度,使用了 Anchor,训练的时候数据增强…
所以强是强,但没啥新意,SSD 和 YOLO9000 可以归为一类。
小结 / 2018
回顾过去,从 YOLO 到 SSD ,人们兼收并蓄把不同思想融合起来。
YOLO 使用了分治思想,将输入图片分为 SxS 的网格,不同网格用性能优良的分类器去分类。
SSD 将 YOLO 和 Anchor 思想融合起来,并创新使用 Feature Pyramid 结构。
但是 Resize 输入,必定会损失许多的信息和一定的精度,这也许是一刀流快的原因。
无论如何,YOLO 和 SSD 这两篇论文都是让人不得不赞叹他们想法的精巧,让人受益良多。
总结 Summary
在「目标检测」中有两个指标:快(Fast) 和 准(Accurate)。
一刀流代表的是快,但是最后在快和准中找到了平衡,第一是快,第二是准。
两刀流代表的是准,虽然没有那么快但是也有 6 FPS 可接受的程度,第一是准,第二是快。
两类算法都有其适用的范围,比如说实时快速动作捕捉,一刀流更胜一筹;复杂、多物体重叠,两刀流当仁不让。没有不好的算法,只有合适的使用场景。
我相信 Mask R-CNN 并不是「目标检测」的最终答案,江山代有才人出,展望未来。
参考资料 Reference
- R-CNN “Rich feature hierarchies for accurate object detection and semantic segmentation”
- SPP Net “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”
- Fast R-CNN “Fast R-CNN”
- Faster R-CNN “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”
- Mask R-CNN “Mask R-CNN”
- YOLO “You Only Look Once: Unified, Real-Time Object Detection”
- SSD “SSD: Single Shot MultiBox Detector”
- YOLO9000 “YOLO9000: Better, Faster, Stronger”