1 Lucene简介
Lucene是apache下的一个开源的全文检索引擎工具包。
1.1 全文检索(Full-text Search)
1.1.1 定义
全文检索就是先分词创建索引,再执行搜索的过程。
分词:就是将一段文字分成一个个单词
全文检索就将一段文字分成一个个单词去查询数据!!!
1.1.2 应用场景
1.1.2.1 搜索引擎(了解)
搜索引擎是一个基于全文检索、能独立运行、提供搜索服务的软件系统。
|
|
1.1.2.2 电商站内搜索(重点)
思考:电商网站内,我们都是通过输入关键词来搜索商品的。如果我们根据关键词,直接查询数据库,会有什么后果?
答:我们只能使用模糊搜索,来进行匹配,会导致很多数据匹配不到。所以,我们必须使用全文检索。
|
|
1.2 Lucene实现全文检索的流程
|
|
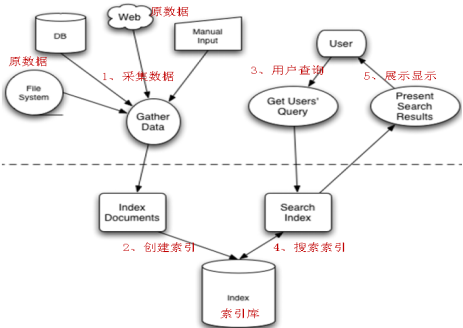
全文检索的流程分为两大部分:索引流程、搜索流程。
索引流程:采集数据--->构建文档对象--->创建索引(将文档写入索引库)。
搜索流程:创建查询--->执行搜索--->渲染搜索结果。
2 入门示例
2.1 需求
使用Lucene实现电商项目中图书类商品的索引和搜索功能。
2.2 配置步骤说明
(1)搭建环境(先下载Lucene)
(2)创建索引库
(3)搜索索引库
2.3 配置步骤
2.3.1 第一部分:搭建环境(创建项目,导入包)
前提:已经创建好了数据库(直接导入book.sql文件)
|
|

2.3.1.1 第一步:下载Lucene
Lucene是开发全文检索功能的工具包,使用时从官方网站下载,并解压。
官方网站:http://lucene.apache.org/
下载地址:http://archive.apache.org/dist/lucene/java/
下载版本:4.10.3(要求:jdk1.7及以上)
核心包lucene-core-4.10.3.jar(附常用API)
|
|
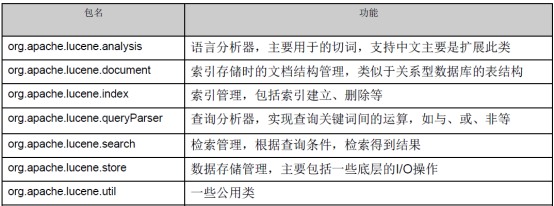
2.3.1.2 第二步:创建项目,导入包
|
mysql5.1驱动包:mysql-connector-java-5.1.7-bin.jar 核心包:lucene-core-4.10.3.jar 分析器通用包:lucene-analyzers-common-4.10.3.jar 查询解析器包:lucene-queryparser-4.10.3.jar |
项目结构如下:
|
|
2.3.2 第二部分:创建索引
步骤说明:
(1)采集数据
(2)将数据转换成Lucene文档
(3)将文档写入索引库,创建索引
2.3.2.1 第一步:采集数据
Lucene全文检索,不是直接查询数据库,所以需要先将数据采集出来。
(1)创建Book类
|
public class Book { private Integer bookId; // 图书ID private String name; // 图书名称 private Float price; // 图书价格 private String pic; // 图书图片 private String description; // 图书描述 // 补全getset方法 } |
(2)创建一个BookDao类
|
package cn.gzsxt.lucene.dao; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import java.util.ArrayList; import java.util.List; import cn.gzsxt.lucene.pojo.Book; public class BookDao { public List<Book> getAll() { // 数据库链接 Connection connection = null; // 预编译statement PreparedStatement preparedStatement = null; // 结果集 ResultSet resultSet = null; // 图书列表 List<Book> list = new ArrayList<Book>(); try { // 加载数据库驱动 Class.forName("com.mysql.jdbc.Driver"); // 连接数据库 connection = DriverManager.getConnection( "jdbc:mysql://localhost:3306/lucene", "root", "gzsxt"); // SQL语句 String sql = "SELECT * FROM book"; // 创建preparedStatement preparedStatement = connection.prepareStatement(sql); // 获取结果集 resultSet = preparedStatement.executeQuery(); // 结果集解析 while (resultSet.next()) { Book book = new Book(); book.setBookId(resultSet.getInt("id")); book.setName(resultSet.getString("name")); book.setPrice(resultSet.getFloat("price")); book.setPic(resultSet.getString("pic")); book.setDescription(resultSet.getString("description")); list.add(book); } } catch (Exception e) { e.printStackTrace(); }finally { if(null!=resultSet){ try { resultSet.close(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(null!=preparedStatement){ try { preparedStatement.close(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } if(null!=connection){ try { connection.close(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } return list; } } |
(3)创建一个测试类BookDaoTest
|
package cn.gzsxt.lucene.test; import java.util.List; import org.junit.Test; import cn.gzsxt.lucene.dao.BookDao; import cn.gzsxt.lucene.pojo.Book; public class BookDaoTest { @Test public void getAll(){ BookDao dao = new BookDao(); List<Book> books = dao.getAll(); for (Book book : books) { System.out.println("图书id:"+book.getBookId()+",图书名称:"+book.getName()); } } } |
(4)测试结果,采集数据成功
|
|

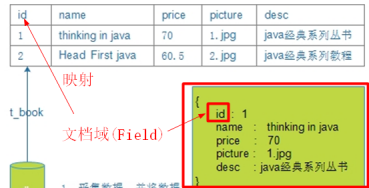
2.3.2.2 第二步:将数据转换成Lucene文档
Lucene是使用文档类型来封装数据的,所有需要先将采集的数据转换成文档类型。其格式为:
|
|
修改BookDao,新增一个方法,转换数据
|
public List<Document> getDocuments(List<Book> books){ // Document对象集合 List<Document> docList = new ArrayList<Document>(); // Document对象 Document doc = null; for (Book book : books) { // 创建Document对象,同时要创建field对象 doc = new Document(); // 根据需求创建不同的Field Field id = new TextField("id", book.getBookId().toString(), Store.YES); Field name = new TextField("name", book.getName(), Store.YES); Field price = new TextField("price", book.getPrice().toString(),Store.YES); Field pic = new TextField("pic", book.getPic(), Store.YES); Field desc = new TextField("description", book.getDescription(), Store.YES); // 把域(Field)添加到文档(Document)中 doc.add(id); doc.add(name); doc.add(price); doc.add(pic); doc.add(desc); docList.add(doc); } return docList; } |
2.3.2.3 第三步:创建索引库
说明:Lucene是在将文档写入索引库的过程中,自动完成分词、创建索引的。因此创建索引库,从形式上看,就是将文档写入索引库!
修改测试类,新增createIndex方法
|
@Test public void createIndex(){ try { BookDao dao = new BookDao(); // 分析文档,对文档中的field域进行分词 Analyzer analyzer = new StandardAnalyzer(); // 创建索引 // 1) 创建索引库目录 Directory directory = FSDirectory.open(new File("F:\lucene\0719")); // 2) 创建IndexWriterConfig对象 IndexWriterConfig cfg = new IndexWriterConfig(Version.LATEST, analyzer); // 3) 创建IndexWriter对象 IndexWriter writer = new IndexWriter(directory, cfg); // 4) 通过IndexWriter对象添加文档对象(document) writer.addDocuments(dao.getDocuments(dao.getAll())); // 5) 关闭IndexWriter writer.close(); System.out.println("创建索引库成功"); } catch (Exception e) { e.printStackTrace(); } } |
测试结果,创建成功!!!
|
|
2.3.3 第三部分:搜索索引
2.3.3.1 说明
搜索的时候,需要指定搜索哪一个域(也就是字段),并且,还要对搜索的关键词做分词处理。
2.3.3.2 执行搜索
修改测试类,新增searchDocumentByIndex方法
|
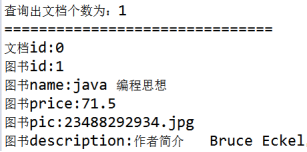
@Test public void searchDocumentByIndex(){ try { // 1、 创建查询(Query对象) // 创建分析器 Analyzer analyzer = new StandardAnalyzer(); QueryParser queryParser = new QueryParser("name", analyzer); Query query = queryParser.parse("name:java教程"); // 2、 执行搜索 // a) 指定索引库目录 Directory directory = FSDirectory.open(new File("F:\lucene\0719")); // b) 创建IndexReader对象 IndexReader reader = DirectoryReader.open(directory); // c) 创建IndexSearcher对象 IndexSearcher searcher = new IndexSearcher(reader); // d) 通过IndexSearcher对象执行查询索引库,返回TopDocs对象 // 第一个参数:查询对象 // 第二个参数:最大的n条记录 TopDocs topDocs = searcher.search(query, 10); // e) 提取TopDocs对象中前n条记录 ScoreDoc[] scoreDocs = topDocs.scoreDocs; System.out.println("查询出文档个数为:" + topDocs.totalHits); for (ScoreDoc scoreDoc : scoreDocs) { // 文档对象ID int docId = scoreDoc.doc; Document doc = searcher.doc(docId); // f) 输出文档内容 System.out.println("==============================="); System.out.println("文档id:" + docId); System.out.println("图书id:" + doc.get("id")); System.out.println("图书name:" + doc.get("name")); System.out.println("图书price:" + doc.get("price")); System.out.println("图书pic:" + doc.get("pic")); System.out.println("图书description:" + doc.get("description")); } // g) 关闭IndexReader reader.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } |
测试结果,非常成功!!!
|
|
2.4 小结
Lucene全文检索,确实可以实现对关键词做分词、再执行搜索功能。并且结果更精确。
3 分词
3.1 重要性
分词是全文检索的核心。
所谓的分词,就是将一段文本,根据一定的规则,拆分成一个一个词。
Lucene是根据分析器实现分词的。针对不同的语言提供了不同的分析器。并且提供了一个通用的标准分析器StandardAnalyzer
3.2 分词过程
--说明:我们通过分析StandardAnalyzer核心源码来分析分词过程
|
@Override protected TokenStreamComponents createComponents(final String fieldName, final Reader reader) { final StandardTokenizer src = new StandardTokenizer(getVersion(), reader); src.setMaxTokenLength(maxTokenLength); TokenStream tok = new StandardFilter(getVersion(), src); tok = new LowerCaseFilter(getVersion(), tok); tok = new StopFilter(getVersion(), tok, stopwords); return new TokenStreamComponents(src, tok) { @Override protected void setReader(final Reader reader) throws IOException { src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength); super.setReader(reader); } }; } |
对应Lucene分词的过程,我们可以做如下总结:
(1)分词的时候,是以域为单位的。不同的域,相互独立。
同一个域中,拆分出来相同的词,视为同一个词(Term)
不同的域中,拆分出来相同的词,不是同一个词。
其中,Term是Lucene最小的语汇单元,不可再细分。
(2)分词的时候经历了一系列的过滤器。如大小写转换、去除停用词等。
3.3 分词后索引库结构
我们这里借助前面的示例来说明
|
|
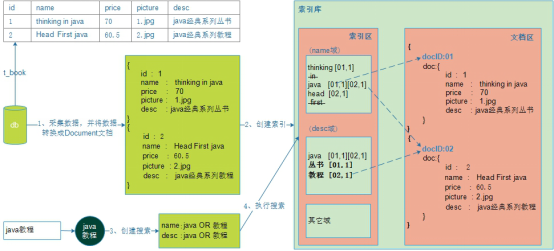
从上图中,我们发现:
(1)索引库中有两个区域:索引区、文档区。
(2)文档区存放的是文档。Lucene给每一个文档自动加上一个文档编号docID。
(3)索引区存放的是索引。注意:
索引是以域为单位的,不同的域,彼此相互独立。
索引是根据分词规则创建出来的,根据索引就能找到对应的文档。
3.4 Luke客户端连接索引库
Luke作为Lucene工具包中的一个工具(http://www.getopt.org/luke/),可以通过可视化界面,连接操作索引库。
3.4.1 启动方法
(1)双击start.bat启动!
|
|

(2)连接索引库
|
|

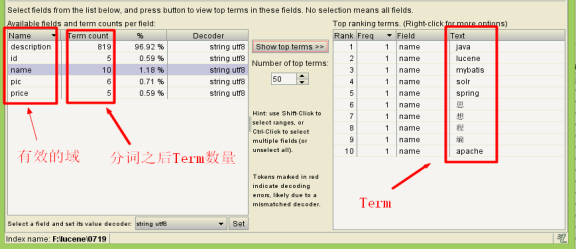
3.4.2 验证分词效果
|
|
4 Field域
问题:我们已经知道,Lucene是在写入文档时,完成分词、索引的。那Lucene是怎么知道的呢?
答:Lucene是根据文档中的域的属性,来确定是否要分词、创建索引的。所以,我们必须搞清楚域有哪些属性。
4.1 域的属性
4.1.1 三大属性
4.1.1.1 是否分词(tokenized)
只有设置了分词属性为true,lucene才会对这个域进行分词处理。
在实际的开发中,有一些字段是不需要分词的,比如商品id,商品图片等。
而有一些字段是必须分词的,比如商品名称,描述信息等。
4.1.1.2 是否索引(indexed)
只有设置了索引属性为true,lucene才为这个域的Term词创建索引。
在实际的开发中,有一些字段是不需要创建索引的,比如商品的图片等。我们只需要对参与搜索的字段做索引处理。
4.1.1.3 是否存储(stored)
只有设置了存储属性为true,在查找的时候,才能从文档中获取这个域的值。
在实际开发中,有一些字段是不需要存储的。比如:商品的描述信息。
因为商品描述信息,通常都是大文本数据,读的时候会造成巨大的IO开销。而描述信息是不需要经常查询的字段,这样的话就白白浪费了cpu的资源了。
因此,像这种不需要经常查询,又是大文本的字段,通常不会存储到索引库。
4.1.2 特点
(1)三大属性彼此独立。
(2)通常分词是为了创建索引。
(3)不存储这个域文本内容,也可以对这个域先分词、创建索引。
4.2 Field常用类型
域的常用类型有很多,每一个类都有自己默认的三大属性。如下:
|
Field类 |
数据类型 |
Analyzed 是否分词 |
Indexed 是否索引 |
Stored 是否存储 |
|
StringField(FieldName, FieldValue,Store.YES)) |
字符串 |
N |
Y |
Y或N |
|
LongField(FieldName, FieldValue,Store.YES) |
Long型 |
Y |
Y |
Y或N |
|
FloatField(FieldName, FieldValue,Store.YES) |
Float型 |
Y |
Y |
Y或N |
|
StoredField(FieldName, FieldValue) |
重载方法,支持多种类型 |
N |
N |
Y |
|
TextField(FieldName, FieldValue, Store.NO) |
字符串 |
Y |
Y |
Y或N |
4.3 改造入门示例中的域类型
4.3.1 分析
(1)图书id:
是否分词:不用分词,因为不会根据商品id来搜索商品
是否索引:不索引,因为不需要根据图书ID进行搜索
是否存储:要存储,因为查询结果页面需要使用id这个值。
(2)图书名称:
是否分词:要分词,因为要将图书的名称内容分词索引,根据关键搜索图书名称抽取的词。
是否索引:要索引。
是否存储:要存储。
(3)图书价格:
是否分词:要分词,lucene对数字型的值只要有搜索需求的都要分词和索引,因为lucene对数字型的内容要特殊分词处理,本例子可能要根据价格范围搜索, 需要分词和索引。
是否索引:要索引
是否存储:要存储
(4)图书图片地址:
是否分词:不分词
是否索引:不索引
是否存储:要存储
(5)图书描述:
是否分词:要分词
是否索引:要索引
是否存储:因为图书描述内容量大,不在查询结果页面直接显示,不存储。
不存储是来不在lucene的索引文件中记录,节省lucene的索引文件空间,如果要在详情页面显示描述,思路:
从lucene中取出图书的id,根据图书的id查询关系数据库中book表得到描述信息。
4.3.2 代码修改
修改BookDao的getDocument方法
|
public List<Document> getDocuments(List<Book> books){ // Document对象集合 List<Document> docList = new ArrayList<Document>(); // Document对象 Document doc = null; for (Book book : books) { // 创建Document对象,同时要创建field对象 doc = new Document(); // 图书ID // 参数:域名、域中存储的内容、是否存储 // 不分词、索引、要存储 // Field id = new TextField("id", book.getId().toString(),Store.YES); Field id = new StoredField("id", book.getBookId().toString()); // 图书名称 // 分词、索引、存储 Field name = new TextField("name", book.getName(),Store.YES); // 图书价格 // 分词、索引、存储 Field price = new FloatField("price", book.getPrice(), Store.YES); // 图书图片 // 不分词、不索引、要存储 Field pic = new StoredField("pic", book.getPic()); // 图书描述 // 分词、索引、不存储 Field desc = new TextField("description",book.getDescription(), Store.NO); // 把域(Field)添加到文档(Document)中 doc.add(id); doc.add(name); doc.add(price); doc.add(pic); doc.add(desc); docList.add(doc); } return docList; } |
4.3.3 测试
(1)去索引库目录中,手动清空索引库。
(2)重新创建索引库。
(3)使用Luke验证分词、索引效果。
|
|

改造成功!!!
5 索引库维护
在第4节,我们需要重新创建索引的时候,是去索引库目录下,手动删除的。
而在实际的开发中,我们可能压根就不知道索引库在哪,就算知道,我们也不可能每次都去手动删除,非常之麻烦!!!
所以,我们必须学习如何维护索引库,使用程序来操作索引库。
需要注意的是,索引是与文档紧密相连的,因此对索引的维护,实际上就是对文档的增删改。
5.1 添加索引(文档)
5.1.1 需求
数据库中新上架了图书,必须把这些图书也添加到索引库中,不然就搜不到该新上架的图书了。
5.1.2 代码实现
调用 indexWriter.addDocument(doc)添加索引。
参考入门示例中的创建索引。
5.2 删除索引(文档)
5.2.1 需求
某些图书不再出版销售了,我们需要从索引库中移除该图书。
5.2.2 代码实现
|
@Test public void deleteIndex() throws Exception { // 1、指定索引库目录 Directory directory = FSDirectory.open(new File("F:\lucene\0719")); // 2、创建IndexWriterConfig IndexWriterConfig cfg = new IndexWriterConfig(Version.LATEST, new StandardAnalyzer()); // 3、 创建IndexWriter IndexWriter writer = new IndexWriter(directory, cfg); // 4、通过IndexWriter来删除索引 // 删除指定索引 writer.deleteDocuments(new Term("name", "apache")); // 5、关闭IndexWriter writer.close(); System.out.println("删除成功"); } |
5.2.3 清空索引库
|
@Test public void deleteIndex() throws Exception { // 1、指定索引库目录 Directory directory = FSDirectory.open(new File("F:\lucene\0719")); // 2、创建IndexWriterConfig IndexWriterConfig cfg = new IndexWriterConfig(Version.LATEST, new StandardAnalyzer()); // 3、 创建IndexWriter IndexWriter writer = new IndexWriter(directory, cfg); // 4、通过IndexWriter来删除索引 // 删除指定索引 writer.deleteAll(); // 5、关闭IndexWriter writer.close(); System.out.println("清空索引库成功"); } |
5.3 更新索引(文档)
5.3.1 说明
Lucene更新索引比较特殊,是先删除满足条件的索引,再添加新的索引。
5.3.2 代码实现
|
// 修改索引 @Test public void updateIndex() throws Exception { // 1、指定索引库目录 Directory directory = FSDirectory.open(new File("F:\lucene\0719")); // 2、创建IndexWriterConfig IndexWriterConfig cfg = new IndexWriterConfig(Version.LATEST, new StandardAnalyzer()); // 3、 创建IndexWriter IndexWriter writer = new IndexWriter(directory, cfg); // 4、通过IndexWriter来修改索引 // a)、创建修改后的文档对象 Document document = new Document(); // 文件名称 Field filenameField = new StringField("name", "updateIndex", Store.YES); document.add(filenameField); // 修改指定索引为新的索引 writer.updateDocument(new Term("name", "apache"), document); // 5、关闭IndexWriter writer.close(); System.out.println("更新成功"); } |
6 搜索
问题:我们在入门示例中,已经知道Lucene是通过IndexSearcher对象,来执行搜索的。那我们为什么还要继续学习Lucene呢?
答:因为在实际的开发中,我们的查询的业务是相对复杂的,比如我们在通过关键词查找的时候,往往进行价格、商品类别的过滤。
而Lucene提供了一套查询方案,供我们实现复杂的查询。
6.1 创建查询的两种方法
执行查询之前,必须创建一个查询Query查询对象。
Query自身是一个抽象类,不能实例化,必须通过其它的方式来实现初始化。
在这里,Lucene提供了两种初始化Query查询对象的方式。
6.1.1 使用Lucene提供Query子类
Query是一个抽象类,lucene提供了很多查询对象,比如TermQuery项精确查询,NumericRangeQuery数字范围查询等。
使用TermQuery实例化
|
Query query = new TermQuery(new Term("name", "lucene")); |
6.1.2 使用QueryParse解析查询表达式
QueryParser会将用户输入的查询表达式解析成Query对象实例。如下代码:
|
QueryParser queryParser = new QueryParser("name", new IKAnalyzer()); Query query = queryParser.parse("name:lucene"); |
6.2 常用的Query子类搜索
6.2.1 TermQuery
特点:查询的关键词不会再做分词处理,作为整体来搜索。代码如下:
|
/** * Query子类查询之 TermQuery * * 特点:不会再对查询的关键词做分词处理。 * * 需要:查询书名与java教程相关书。 */ @Test public void queryByTermQuery(){ //1、获取一个查询对象 Query query = new TermQuery(new Term("name", "编程思想")); doSearch(query); } private void doSearch(Query query) { try { //2、创建一个查询的执行对象 //指定索引库的目录 Directory d = FSDirectory.open(new File("F:\lucene\0719")); //创建流对象 IndexReader reader = DirectoryReader.open(d); //创建搜索执行对象 IndexSearcher searcher = new IndexSearcher(reader); //3、执行搜索 TopDocs result = searcher.search(query, 10); //4、提出结果集,获取图书的信息 int totalHits = result.totalHits; System.out.println("共查询到"+totalHits+"条满足条件的数据!"); System.out.println("-----------------------------------------"); //提取图书信息。 //score即相关度。即搜索的关键词和 图书名称的相关度,用来做排序处理 ScoreDoc[] scoreDocs = result.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { /** * scoreDoc.doc的返回值,是文档的id, 即 将文档写入索引库的时候,lucene自动给这份文档做的一个编号。 * * 获取到这个文档id之后,即可以根据这个id,找到这份文档。 */ int docId = scoreDoc.doc; System.out.println("文档在索引库中的编号:"+docId); //从文档中提取图书的信息 Document doc = searcher.doc(docId); System.out.println("图书id:"+doc.get("id")); System.out.println("图书name:"+doc.get("name")); System.out.println("图书price:"+doc.get("price")); System.out.println("图书pic:"+doc.get("pic")); System.out.println("图书description:"+doc.get("description")); System.out.println(); System.out.println("------------------------------------"); } //关闭连接,释放资源 if(null!=reader){ reader.close(); } } catch (Exception e) { e.printStackTrace(); } } |
6.2.2 NumericRangeQuery
指定数字范围查询.(创建field类型时,注意与之对应)
|
/** * Query子类查询 之 NumricRangeQuery * 需求:查询所有价格在[60,80)之间的书 * @param query */ @Test public void queryByNumricRangeQuery(){ /** * 第一个参数:要搜索的域 * 第二个参数:最小值 * 第三个参数:最大值 * 第四个参数:是否包含最小值 * 第五个参数:是否包含最大值 */ Query query = NumericRangeQuery.newFloatRange("price", 60.0f, 80.0f, true, false);
doSearch(query); } |
6.2.3 BooleanQuery
BooleanQuery,布尔查询,实现组合条件查询。
|
/** * Query子类查询 之 BooelanQuery查询 组合条件查询 * * 需求:查询书名包含java,并且价格区间在[60,80)之间的书。 */ @Test public void queryBooleanQuery(){ //1、要使用BooelanQuery查询,首先要把单个创建出来,然后再通过BooelanQuery组合 Query price = NumericRangeQuery.newFloatRange("price", 60.0f, 80.0f, true, false); Query name = new TermQuery(new Term("name", "java"));
//2、创建BooleanQuery实例对象 BooleanQuery query = new BooleanQuery(); query.add(name, Occur.MUST_NOT); query.add(price, Occur.MUST); /** * MSUT 表示必须满足 对应的是 + * MSUT_NOT 必须不满足 应对的是 - * SHOULD 可以满足也可以不满足 没有符号 * * SHOULD 与MUST、MUST_NOT组合的时候,SHOULD就没有意义了。 */
doSearch(query); } |
6.3 通过QueryParser搜索
6.3.1 特点
对搜索的关键词,做分词处理。
6.3.2 语法
6.3.2.1 基础语法
|
域名:关键字 实例:name:java |
6.3.2.2 组合条件语法
|
条件1 AND 条件2 条件1 OR 条件2 条件1 NOT 条件2 |
6.3.3 QueryParser
6.3.3.1 代码实现
|
/** * 查询解析器查询 之 QueryParser查询 */ @Test public void queryByQueryParser(){ try { //1、加载分词器 Analyzer analyzer = new StandardAnalyzer(); /** * 2、创建查询解析器实例对象 * 第一个参数:默认搜索的域。 * 如果在搜索的时候,没有特别指定搜索的域,则按照默认的域进行搜索 * 如何在搜索的时候指定搜索域呢? * 答:格式 域名:关键词 即 name:java教程 * * 第二个参数:分词器 ,对关键词做分词处理 */ QueryParser parser = new QueryParser("description", analyzer); Query query = parser.parse("name:java教程"); doSearch(query); } catch (Exception e) { e.printStackTrace(); } } |
6.3.4 MultiFieldQueryParser
通过MulitFieldQueryParse对多个域查询。
|
/** * 查询解析器查询 之 MultiFieldQueryParser查询 * * 特点:同时指定多个搜索域,并且对关键做分词处理 */ @Test public void queryByMultiFieldQueryParser(){ try { //1、定义多个搜索的 name、description String[] fields = {"name","description"}; //2、加载分词器 Analyzer analyzer = new StandardAnalyzer(); //3、创建 MultiFieldQueryParser实例对象 MultiFieldQueryParser mParser = new MultiFieldQueryParser(fields, analyzer); Query query = mParser.parse("lucene教程"); doSearch(query); } catch (Exception e) { e.printStackTrace(); } } |
7 中文分词器
7.1 什么是中文分词器
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。
而中文的语义比较特殊,很难像英文那样,一个汉字一个汉字来划分。
所以需要一个能自动识别中文语义的分词器。
7.2 Lucene自带的中文分词器
7.2.1 StandardAnalyzer:
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
7.2.2 CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足需求。
7.3 使用中文分词器IKAnalyzer
IKAnalyzer继承Lucene的Analyzer抽象类,使用IKAnalyzer和Lucene自带的分析器方法一样,将Analyzer测试代码改为IKAnalyzer测试中文分词效果。
如果使用中文分词器ik-analyzer,就在索引和搜索程序中使用一致的分词器ik-analyzer。
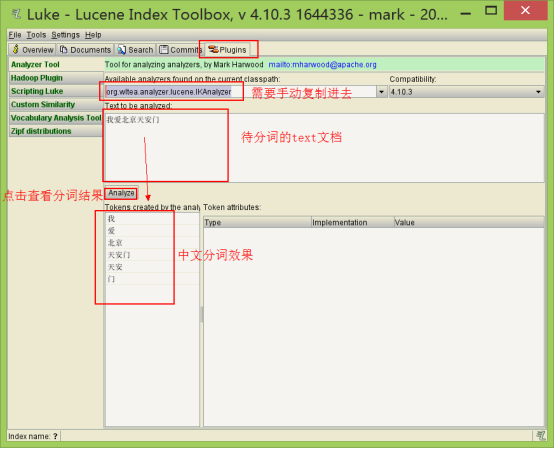
7.3.1 使用luke测试IK中文分词
(1)打开Luke,不要指定Lucene目录。否则看不到效果
(2)在分词器栏,手动输入IkAnalyzer的全路径
org.wltea.analyzer.lucene.IKAnalyzer
|
|
7.3.2 改造代码,使用IkAnalyzer做分词器
7.3.2.1 添加jar包
|
|
7.3.2.2 修改分词器代码
|
// 创建中文分词器 Analyzer analyzer = new IKAnalyzer(); |
7.3.2.3 扩展中文词库
拓展词库的作用:在分词的过程中,保留定义的这些词
1在src或其他source目录下建立自己的拓展词库,mydict.dic文件,例如:
|
|

2在src或其他source目录下建立自己的停用词库,ext_stopword.dic文件
停用词的作用:在分词的过程中,分词器会忽略这些词。
3在src或其他source目录下建立IKAnalyzer.cfg.xml,内容如下(注意路径对应):
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!-- 用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">mydict.dic</entry> <!-- 用户可以在这里配置自己的扩展停用词字典 --> <entry key="ext_stopwords">ext_stopword.dic</entry> </properties> |
如果想配置扩展词和停用词,就创建扩展词的文件和停用词的文件,文件的编码要是utf-8。
注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。
8 思考:(面试题)
在一堆文件中,如何快速根据关键词找出对应的文件?
思路:(1)使用全文检索来解决问题
(2)数据源由数据库变成一堆文件。
(3)从一堆文件中,读出里面的内容,转成文档,创建索引库。
(4)创建索引库之后,再根据关键词搜索索引库,找出文件的名称。
问题:如何读文件的内容?
答:txt文本,直接使用IO即可。
doc|docx 使用POI读取内容。