1.Python函数概述
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。Python具有很多内置函数,除此之外也可以自定义函数。自定义函数可以理解为一个变量,通过定义函数再来调用函数来实现函数功能。
2. 自定义函数
格式:
def 函数名(参数):
函数体
注意:
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
3. 函数的调用
格式:
函数名()
#定义 def Hello(): print('Hello python world') #调用 Hello() result: Hello python world
与变量类似,变量名()为函数名,变量值为函数体,变量的id 可以用变量名。函数的内存地址加上括号就是调用函数。
4. 实参与形参
定义函数括号里的一般叫形参(形式参数),调用时括号里传递的参数一般叫实参(实际参数)。
def sum(x,y): #x、y为形参
print(x) print(y) print(x+y) sum (10,20) #10、20为实参,与形参对应 result: 10 20 30 def sum(x,y): print(x) print(y) sum(y=20,x=10) result: 10 20 直接使用sum(x)或者sum(y)这种形式是错误的。可以单独第一一个参数在调用,如: def sum(x) print(x) sum(10) result: 10
函数亦可以成为另一个参数的实参:
def test(): print(100) def sum(x): print(x) sum(test) result: <function test at 0x00000294367F2EA0>
5. return返回值
return语句[表达式]退出函数,选择性地向调用方返回一个表达式,即return将返回值赋给调用函数。不带参数值的return语句返回None。return可以返回任意数据类型。
def test1( ): print(100) def test2(): print(test1( )) test2( ) result: 100 None def test2(): return 200 print(test2()) #相当于test2( )=200 result: 200 def test1(): print(100) def test2(): return [1,2,3,4] print(test2()) result: [1,2,3,4]
6. 练习
用函数实现监控内存、CPU、磁盘的使用情况,如果系统资源超出阈值则进行报警。
需要用到的模块:psutil、yagmail。
1> psutil,监控系统资源;yagmail,发送邮件
#下载安装 (yunwei) E:Learningpython>pip install psutil yagmail ……. Successfully installed psutil-5.6.2 yagmail-0.11.220 ….. (yunwei) E:Learningpython>pip list
psutil: import psutil #导入 mem = psutil.virtual_memory() #监控内存 print(mem) result: svmem(total=8496857088, available=3805626368, percent=55.2, used=4691230720, free=3805626368) #总共、可用、占用率(%)、已用、空闲,单位均为字节 import psutil cpu = psutil.cpu_percent(1) #一秒内CPU的占用率 print(cpu) result: 12.4 import psutil disk = psutil.disk_usage('c:') #查看C盘的使用情况 print(disk) result: sdiskusage(total=107374178304, used=25433534464, free=81940643840, percent=23.7)
以上各系统信息均以元组形式列出,可以通过[index]取出相应的值。利用函数实现时尽量一个动作一个函数,降低函数的耦合。
yagmail: #导入 import yagmail #连接邮箱服务器 yag = yagmail.SMTP(user='18618250232@163.com', password='你自己的密码', host='smtp.163.com') # 发送邮件 yag.send(to=['18618250232@163.com','18702510185@163.com'],subject='这是测试邮件标题', contents=['这是测试邮件的内容',r'C:UsersAdministrator.USER-20190512NQDesktopsed.txt']) #多个收件人、附件 # 断开连接 yag.close()
Python定义函数的规范格式:
Python中一般将函数封装到某一个主函数,例如,定义一个主函数main(),将函数disk()、mem()、cpu()封装。
def sendmail( )
def disk( ):
pass
def mem( ):
pass
def cpu( ):
pass
def main( ):
disk( )
mem( )
cpu( )
调用时较规范的写法为:
if __name__ == '__main__': #__name__是内置变量,它是一个字符串 main()
这是因为在Python中,同一环境下的.py文件是可以当做模块导入的。
以a.py为例,可以使用import命令:
import a 或者 from a import *,前面这种方法可以使用a.show( )来显示a.py文件内容,后面这种方法可以直接使用show( )函数打印导入文件的内容。
if……main( )的这种格式就是为了声明要利用主窗口来调用其他函数。
监控系统资源:
#定义内存监控,检测其占用百分比 def mem(): import psutil mem = psutil.virtual_memory() che_mem = mem[2] return che_mem # print(che_mem) #定义cpu监控 def cpu(): import psutil che_cpu = psutil.cpu_percent(1) return che_cpu # print(che_cpu) #定义C盘资源使用情况,监控其占用百分比 def disk(): import psutil disk = psutil.disk_usage('c:') che_disk = disk[3] return che_disk # print(che_disk) #定义报警邮件
def mail(x,y):
import yagmail
yag = yagmail.SMTP(user='你自己的邮箱@163.com', password='你自己的密码', host='smtp.163.com')
yag.send(to='你自己的邮箱@qq.com', subject=x,
contents=y)
yag.close()
#定义主函数 def main(): mem() cpu() disk() def sendmail(): #调用主函数
def sendmail():
if __name__ == '__main__':
main()
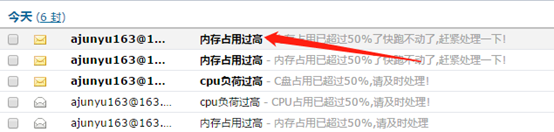
if mem()> 50:
mail('内存占用过高','内存占用百分比已达到%d了快跑不动了,赶紧处理一下!'%(mem()))
elif cpu () > 50:
mail('cpu占用过高','CPU占用百分比已达到%d,再这么下去就要溢出来了,还想不想用电脑了,赶紧处理一下!'%(cpu()))
elif disk() > 50:
mail('磁盘即将填满','C盘占用已达到%d了,电脑的大脑快满了,你让它怎么活?赶紧去处理!'%(disk()))
sendmail()
再导出为exe程序,就可以一键监控系统环境了。 (yunwei) E:Learningpython>pyinstaller -F monit_sys.py 35349 INFO: Appending archive to EXE E:Learningpythondistmonit_sys.exe
双击,看邮件

7.名称空间和作用域
内置名称空间:(python启动时就有)python解释器内置的名字,print,max,min。
全局名称空间:(执行python文件时启动)定投定义的变量。
局部名称空间:(调用函数时启动,调用结束失效)函数内部定义的变量。
三者的加载顺序:
内置--->全局--->局部
三者的访问顺序
局部--->全局--->内置
a = 100 #全局变量 def sl(): a = 50 #局部变量 def s2(): a = 25 #局部变量 print (a) s2() sl() result: 25
8.装饰器
装饰器是在不修改源代码和调用方式的基础上增加新的功能。多个装饰器可以装饰在同一个函数上。
先来看无参装饰器:
先定义一个函数func1:
def func1(): print('this is func1') func1() result: this is func1
该函数调用的是func1( ),在不改变源代码、不改变其调用方式的基础上使该函数执行结果添加一行’this is a new function’,即利用装饰器给原函数添加功能:
def deco(func): def wrapper( ): func() print('this is a new function') return wrapper def func1(): print('this is func1') func1 = deco(func1) func1() result: this is func1 this is a new function
函数分析:Python语句是从上到下按行执行的,因此首先定义函数deco,跳过函数体找到该函数的调用deco( func1),将实参func1即func1( )函数的内存地址传入,定义函数wrapper( ),传入参数func=func1,并返回wrapper( )的内存地址;deco函数执行完赋值给变量func1(func1= deco(func1)),再回到调用函数deco( ),所以此时func1( )的地址与wrapper( )的内存地址相等,即func1=wrapper;内存地址加括号即调用函数,因此执行到func1( )时即调用函数wrapper( ),该函数实现:执行函数func1( )即打印‘this is func1’、打印‘this is a new function’,结束函数。实现了在不改变源代码和调用方式的情况下增加新功能。
以上就是无参数装饰器的执行过程。
对于带参数的装饰器:
def deco(func): def wrapper(x,y): func(x,y) print('this is a new function') return wrapper def func1(x,y): print('this is func1 | %s : %s'%(x,y)) func1 = deco(func1) func1(1,2) result: this is func1 | 1 : 2 this is a new function
对于上面这两种方式,虽然没有改变源代码且没有改变调用格式,但也在函数体之间增加的了一行 func1( ) = deco ( func1),为了保证装饰器的规范性,使用@符号来进行美化:
原代码: def deco(func): def wrapper(x,y): func(x,y) print('this is a new function') return wrapper def func1(x,y): print('this is func1 | %s : %s'%(x,y)) func1 = deco(func1) func1(1,2) 美化后的代码: def deco(func): def wrapper(x,y): func(x,y) print('this is a new function') return wrapper @deco # func1 = deco(func1) def func1(x,y): print('this is func1 | %s : %s'%(x,y)) func1(1,2) result: this is func1 | 1 : 2 this is a new function
一个函数可以有多个装饰器,将@写到一起即可。
9. 迭代器
迭代,iterate,是一个重复的过程,即每一次重复为一次迭代;并且每次迭代的结果都是下一次迭代的初始值。同时满足两条才可称之为迭代。
例如while循环:
ls = [1,2,3] count = 0 while count < len(ls): #重复的动作,上一次执行的结果是下一次的初始值,是迭代 print(ls[count]) count += 1
迭代器:对于序列类型:字符串、列表、元组,我们可以使用索引的方式迭代取出其包含的元素。但对于字典、集合、文件等类型是没有索引的,若还想取出其内部包含的元素,则必须找出一种不依赖于索引的迭代方式,这就是迭代器。
定义条件: str1 = 'HelloWorld' l1 = ['a','b','c'] t1 = ('a','b','c') info = { 'name':'zxj', 'age': 23 } s1 = {1,2,5,8} f = open('info.txt',encoding='utf-8') #文件
对于上例,不使用for循环的情况下将各类型中的元素取出,可以通过while循环,用index将字符串、列表、元组的元素取出,但字典、集合不支持index,因此Python解释器必须提供了一种不依赖于下标的取值方法,即迭代器。
可迭代对象:可迭代对象指的是内置有__iter__方法的对象,即obj.__iter__,如下:
对于上述定义的条件
str1.__iter__() l1.__iter__() t1.__iter__() info.__iter__() s1.__iter__() f.__iter__()
均存在__iter__( ),即字符串、元组、列表、字典、集合、文件都是可迭代对象。整数、浮点数都不是可迭代对象。
迭代器对象:可迭代对象执行obj.__iter__()得到的结果就是迭代器对象
迭代器对象指的是即内置有__iter__又内置有__next__方法的对象
f.__next__()
对于上面的定义,只有文件是迭代器对象。
通过item(obj)__next__可以将可迭代对象变为迭代器对象。obj__next__与next(obj)完全等效。
iter(str1).__next__()
iter(l1).__next__()
iter(t1).__next__()
iter(info).__next__()
iter(s1).__next__()
将可迭代对象变为迭代器对象后就可以不依赖索引取值了。
res = iter(s1) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) result: #超出集合范围会报错 Traceback (most recent call last): 8 File "E:/Learning/python/experment.py", line 230, in <module> 1 2 5 print(res.__next__()) StopIteration 变成迭代器对象后可以用while循环将集合里的元素取出 s1 = {1,2,5,6} res = iter(s1) count = 0 while count< len(s1): print(next(res)) count += 1 result: 1 2 5 6 更简单直接的方法,可以用for循环 s1 = {1,2,5,6} for i in s1: #for语句将s1变成了迭代器对象,过滤错误。 print(i) result: 1 2 5 6 for循环已经对语句经过另外的处理,只要用for循环,就将in后面的内容变成迭代器对象,并处理异常(比如超出长度范围的报错)。
可迭代对象不一定是迭代器对象;迭代器对象一定是可迭代对象。
10. 生成器
只要函数里有yield关键字,那么函数名( )得到的结果就是生成器,并且不会执行函数内部代码。
生成器本身就是迭代器。
def test(): str1 = 'HelloWorld' yield str1 print(test()) #打印函数的执行结果 print(test().__next__()) result: <generator object test at 0x0000020AEA54CF68> #生成器 HelloWorld
与return不同的是,return可以返回一个值,而yield可以返回多个值,并且在同一时间只能储存一个值,较return节省空间。但是yield没有索引,不能回退取值。
分别用return和yield的方式取出0~9 #return的方式:return只能返回一个值,因此要想将所有的值返回,必须将这些值打包为集合或其他数据类型一次性返回给函数,程序复杂,占用存储空间大。 def test(): l = [] for i in range(10): l.append(i) return l print(test()) result: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] #yield的方式:yield可以返回多个值,在执行循环时每次执行都返回以一个结果给函数,并且在同一时间只能存储一个值,因此程序简单,占用存储空间小。 def test(): for i in range(10): print(i) yield i for i in test(): print(i) result: 0 1 2 3 4 5 6 7 8 9
11. 匿名函数
用关键字lambda定义匿名函数。匿名函数并不定义函数名,具有参数,而且自带return,直接return函数体的执行结果。匿名函数通常只调用一次,之后不再使用。lambda函数主要应用于函数名不方便定义的场景,可以通过一条命令执行一个函数。
print(lambda x,y : x+y) result: <function <lambda> at 0x0000029903DC2EA0> #返回内存地址 print((lambda x,y : x+y)(1,2)) #内存地址加括号进行调用 result: 3 等效于函数: def test(x,y): return x+y print(test(1,2)) result: 3
11.1 lambda的使用场景
max、sorted、map、filter
1> max函数:求最大值。
定义字典:《雪中》经典人物:年龄 info = { 'x徐凤年': '31', 'l吕洞玄': '800', 'g高树露': '300', 'l洛阳': '700', 'n南宫仆射': '30' } print(max(info)) result: x徐凤年 字典默认循环的是key值,x最大 若要取出年龄最大的人名,可以通过以下方法: 首先,可以通过print(max(info.values()))得到最大的年龄800 其次,定义函数func(),得到返回内存值func。 def func(k): return info[k] #info[k]拿到的是k对应的value 最后,max函数在遍历字典info时,指定遍历value print(max(info,key = func)) 执行结果: l洛阳 这个过程可以用匿名函数一条语句实现: print(max(info,key = lambda k:info[k])) result: 1洛阳
2> sorted:排序
对上述的字典按年龄排序: print(sorted(info,key = lambda k: info[k])) #从小到大 print(sorted(info,key = lambda k: info[k],reverse=True)) #从大到小 result: ['n南宫仆射', 'g高树露', 'x徐凤年', 'l吕洞玄', 'l洛阳'] ['l洛阳', 'l吕洞玄', 'x徐凤年', 'g高树露', 'n南宫仆射']
3> map:映射
zip:拉链。相当于一个生成器,可以用list命令查看里面的内容。
l1 = [1,2,3] l2 = ['a','b','c'] print(zip(l1,l2)) print(list(zip(l1,l2))) result: <zip object at 0x000002BFD477D948> [(1, 'a'), (2, 'b'), (3, 'c')] #元素一一对应,而且只对应存在的元素 for i in list(zip(l1,l2)): print(i) result: (1, 'a') (2, 'b') (3, 'c')
map也是一一对应的关系。
给列表元素加后缀,先利用for函数实现: names = ['li','zhao','du','wu'] l1 = [] for name in names: res = '%s_SB' % name l1.append(res) print(l1) result: ['li_SB', 'zhao_SB', 'du_SB', 'wu_SB'] for循环可以用map代替 print(list(map(lambda name: '%s_SB' % name,names))) result: ['li_SB', 'zhao_SB', 'du_SB', 'wu_SB']
4> filter:过滤
过滤出列表中以_SB结尾的元素: names = ['li_SB', 'zhao_SB', 'du_SB', 'wu_SB','wang'] print(list(filter(lambda i : i.endswith('_SB') , names))) result: ['li_SB', 'zhao_SB', 'du_SB', 'wu_SB'] 过滤掉以_SB结尾的元素 print(list(filter(lambda i : not i.endswith('_SB') , names))) result: ['wang']
12. 多任务
Python中的多任务包括:多线程、多进程、协程。
线程是最小的调度单位,进程是最小的管理单元。
多任务实现多个任务同时运行。
1> Python多线程的特点
线程的并发是利用cpu上下文的切换(并不是并行),即多线程运行时只有一个CPU在运行,通过上下切换进行任务(执行任务后释放再执行另一个任务,利用CPU的高频实现多任务的实现,并发,实质上是串行)而不是通过并行使用线程;
多线程的执行顺序是无序的;
多线程共享全局变量,全局变量不能够修改,若要修改,必须加关键字global进行申明;
线程是继承在进程里的。没有进程就没有线程;
GIL全局解释器锁;
只要在进行耗时的IO操作的时候,能释放GIL,所以在IO密集的代码里,用多线程就很合适。
#导入多线程模块 import threading #导入time模块 import time #定义实验函数 def test1(n): time.sleep(1) print('task',n) for i in range(1,11): t = threading.Thread(target=test1,args=('t%s' % i,)) #调用多线程,参数用args调用 t.start() #启用线程 result: #多线程执行的顺序是无序的 task t2 task t1 task t3 task t4 task t8 task t7 task t6 task t5 task t9 task t10 num = 1 def tast(): global num #申明全局变量 num += 100 def test2(): print(num) #共享变量 t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() t2.start() result: 101
2> GIL详解
GIL的全称是:Global Interpreter Lock,意思就是全局解释器锁,这个GIL并不是python的特性,是只在Cpython解释器里引入的一个概念,而在其他的语言编写的解释器里就没有这个GIL例如:Jython,Pypy
为什么会有gil?:
随着电脑多核cpu的出现核cpu频率的提升,为了充分利用多核处理器,进行多线程的编程方式更为普及,随之而来的困难是线程之间数据的一致性和状态同步,而python也利用了多核,所以也逃不开这个困难,为了解决这个数据不能同步的问题,设计了gil全局解释器锁。
在多线程中共享全局变量的时候会有线程对全局变量进行的资源竞争,会对全局变量的修改产生不是我们想要的结果,而那个时候我们用到的是python中线程模块里面的互斥锁,哪样的话每次对全局变量进行操作的时候,只有一个线程能够拿到这个全局变量。

import threading global_num = 0 def test1(): global global_num for i in range(1000000): global_num += 1 print("test1", global_num) def test2(): global global_num for i in range(1000000): global_num += 1 print("test2", global_num) t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() t2.start() result: #多线程对全局变量进行竞争,主线程运行完其余线程还没有运行完,导致生成的数为随机的高位数,结果并不是两次相加后的2000000 test1 1114536 test2 1294516
在不断地存放锁、赋值锁中,数字越小出错的概率越小。
为了能够得到正确的结果,解决数据不一致的问题,需要对多任务进行加锁操作:
import threading lock = threading.Lock() #定义线程锁 global_num = 0 def test1(): global global_num lock.acquire() #加锁 for i in range(1000000): global_num += 1 print("test1", global_num) lock.release() #释放锁 def test2(): global global_num lock.acquire() for i in range(1000000): global_num += 1 lock.release() print("test2", global_num) t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() t2.start() result: test1 1000000 test2 2000000
再次注意,由于CPU的高频,多任务是并发运行的。如
def test1() time.sleep(1) print(‘test1’) def test2() time.sleep(1) print(‘test2’) t1 = threading.Thread(target = test1) t2 = threading.Thread(target = test2)
这个多任务总共用了1秒时间。
多线程可以提高执行效率。
13. 多进程
多线程适用于IO密集(如从硬盘读取资料)的场景,多进程适用于CPU密集(如加减乘除的计算)的场景。
一个程序运行起来之后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单位,不仅可以通过线程完成多任务,进程也是可以的;
进程之间是相互独立的;
cpu密集的时候适合用多进程。多进程是多核CPU并行的。
多进程比较耗费资源,效率较高。
13.1 多进程实现多任务
多进程也是可以实现多任务的 import time #导入time模块 import multiprocessing #导入多进程模块 def test1(): for i in range(7): time.sleep(1) print('task1',i) def test2(): for i in range(7): time.sleep(1) print('task2',i) if __name__ == '__main__': #多进程中必须声明main p1 = multiprocessing.Process(target=test1) #声明进程 p2 = multiprocessing.Process(target=test2) p1.start() #启动进程 p2.start() result: #多进程也是可以实现多任务的 task1 0 task2 0 task1 1 task2 1 task1 2 task2 2 task1 3 task2 3 task1 4 task2 4 task1 5 task2 5 task1 6 task2 6 在多进程中各进程是独立的,不共享全局变量。 num = 0 def test1(): global num for i in range(10): num += 1 def test2(): print(num) if __name__ == '__main__': p1 = multiprocessing.Process(target=test1) p2 = multiprocessing.Process(target=test2) p1.start() p2.start() resul: #两个进程相互独立 0
13.2 进程池(Pool)
用进程池实现多进程:
import time import multiprocessing from multiprocessing import Pool #从多进程模块导入进程池 def test1(): for i in range(4): time.sleep(1) print('task1',i) def test2(): for i in range(4): time.sleep(1) print('task2',i) if __name__ == '__main__': pool = Pool(2) #指定并发数为2,如果进程为1,则为串行。 pool.apply_async(test1) pool.apply_async(test2) pool.close() pool.join() #close、join这两步表示关闭进程池,close在前,join在后,顺序不能变。 result: task1 0 task2 0 task1 1 task2 1 task1 2 task2 2 task1 3 task2 3
14. 协程
协程也叫微线程,它是在一个线程里面;协程也可以实现多任务;协程遇见IO就自动切换。
(yunwei) E:Learningpython>pip install gevent #安装协程模块gevent …. Successfully installed gevent-1.4.0 greenlet-0.4.15 ….. import gevent #导入gevent模块 def test1(): for i in range(4): time.sleep(1) print('task1',i) def test2(): for i in range(4): time.sleep(1) print('task2'.i) g1 = gevent.spawn(test1) #用spawn函数调用函数 g2 = gevent.spawn(test2) g1.join() #用join启动协程 g2.join() result: task1 0 task1 1 task1 2 task1 3 task2 0 task2 1 task2 2 task2 3 可以看到,执行结果是按照串行来执行的,这是因为在协程中不识别time模块,在协程中可以使用协程特有的gevent.sleep来查看协程并发。 import gevent def test1(): for i in range(4): gevent.sleep(1) #time.sleep(1) print('task1',i) def test2(): for i in range(4): gevent.sleep(1) # time.sleep(1) print('task2',i) g1 = gevent.spawn(test1) g2 = gevent.spawn(test2) g1.join() g2.join() result: task1 0 task2 0 task1 1 task2 1 task1 2 task2 2 task1 3 task2 3 若要在协程中使用time模块,需要给其打补丁mokey import gevent from gevent import monkey monkey.patch_all() def test1(): for i in range(4): time.sleep(1) print('task1',i) def test2(): for i in range(4): time.sleep(1) print('task2',i) g1 = gevent.spawn(test1) g2 = gevent.spawn(test2) g1.join() g2.join() result: task1 0 task2 0 task1 1 task2 1 task1 2 task2 2 task1 3 task2 3
协程并发可以理解为一种遇见IO就切换的一种串行。
总的来说:
- 进程是资源分配的单位;
- 线程是操作系统调度的单位;
- 进程切换需要的资源最大,效率低;
- 线程切换需要的资源一般,效率一般;
- 协程切换任务资源很小,效率高;
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协成在一个线程中。