SparkStreaming接收Kafka数据的两种方式
- SparkStreaming接收数据原理
- 一、SparkStreaming + Kafka Receiver模式
- 二、SparkStreaming + Kafka Direct模式
- 三、Direct模式与Receiver模式比较
- 四、SparkStreaming+Kafka维护消费者offset
- 五、实例:SparkStreaming集成Kafka,读取Kafka中数据,进行数据统计计算
- 5.1 pom.xml
- 5.2模式一:Receiver模式:对于所有的Receivers,接收到的数据将会保存在Spark executors中,然后由Spark Streaming启动的Job来处理这些数据。
- 5.3模式二:Direct模式:当作业需要处理的数据来临时,spark通过调用Kafka的简单消费者API读取一定范围的数据。
- SparkStreaming读取kafka数据-DirectStream方式
- 六、实例:spark streaming+kafka随机wordcount统计
- 七、Springboot最简单的实战介绍 整合kafka-生产者与消费者(消息推送与订阅获取)
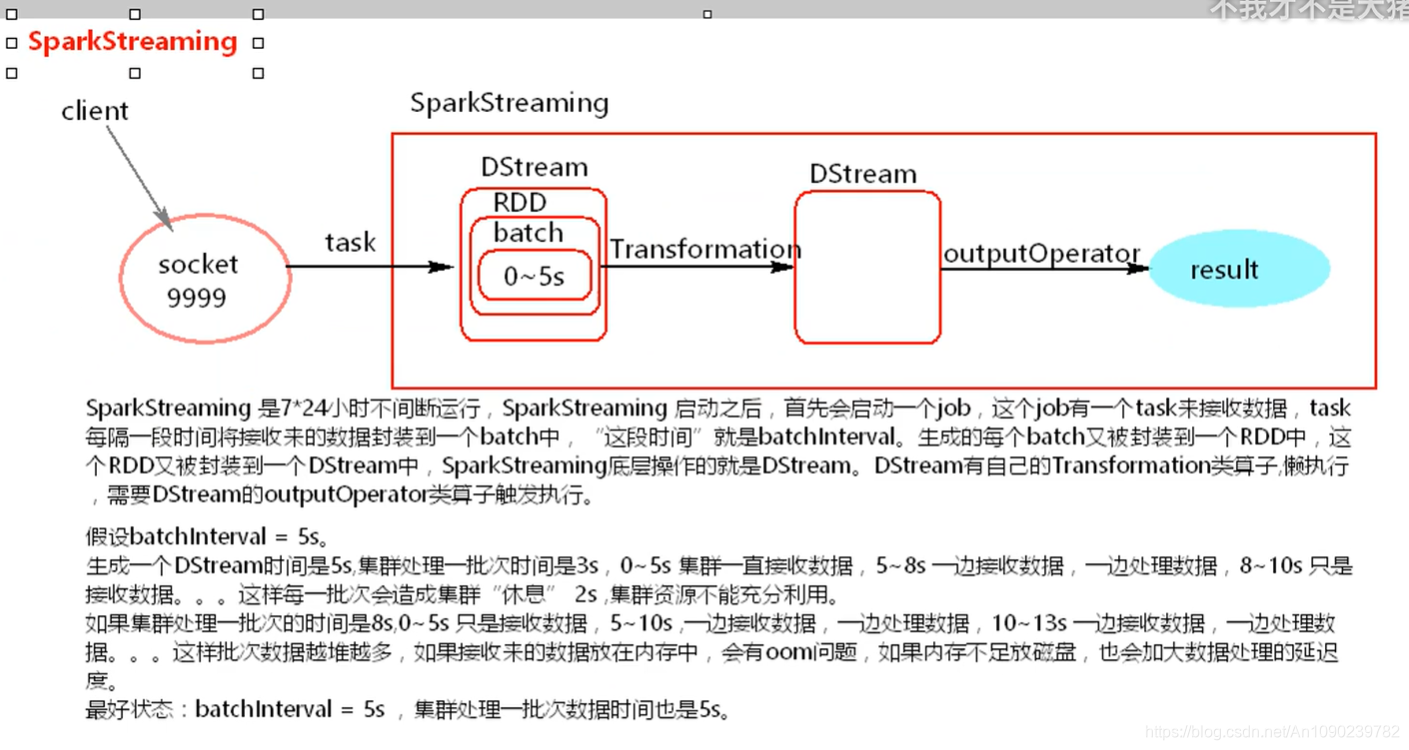
SparkStreaming接收数据原理
一、SparkStreaming + Kafka Receiver模式
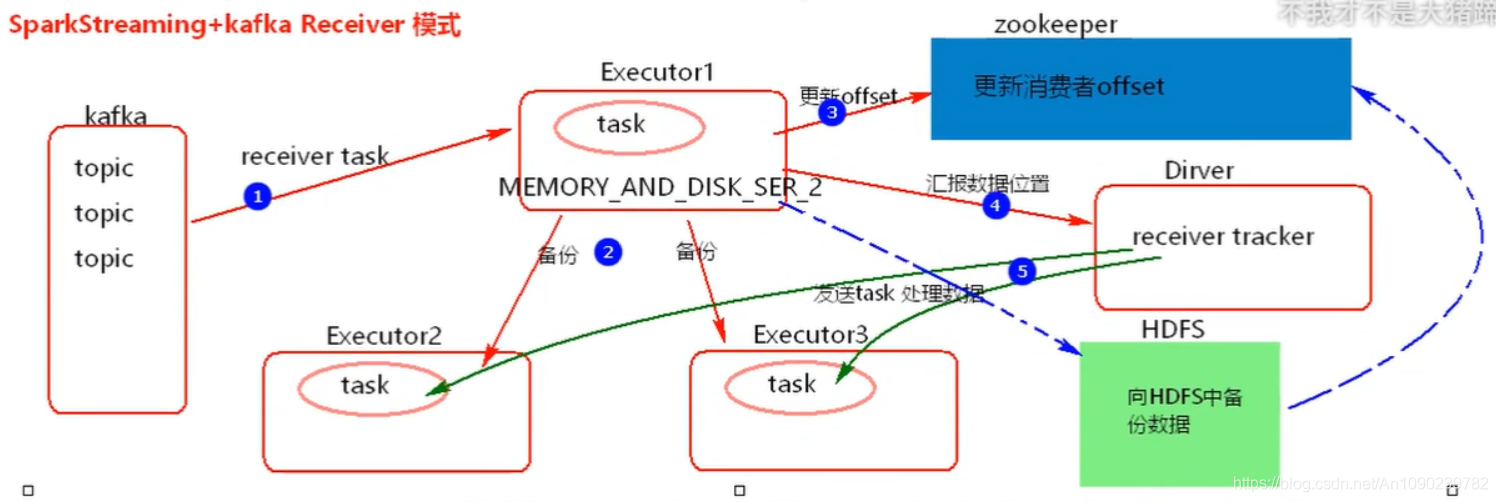
SparkStreaming + Kafka Reveiver模式处理数据采用了Reveiver接收器的模式,需要一个task一直处于占用接收数据,接收来的数据存储级别:MEMORY_AND_DISH_SER_2,这种模式几乎是没有用的。
在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据。数据会被持久化,默认级别为MEMORY_AND_DISK_SER_2,这个级别也可以修改。receiver task对接收过来的数据进行存储和备份,这个过程会有节点之间的数据传输。备份完成后去zookeeper中更新消费偏移量,然后向Driver中的receiver tracker汇报数据的位置。最后Driver根据数据本地化将task分发到不同节点上执行。
原因:
存在丢失数据的问题
当接收完消息后,更新完zookeeper offset后,如果Driver挂掉,Driver下的Executor也会被killed,在Executor内存中的数据多少会有丢失。
如何解决数据丢失问题
开启WAL(Write Ahead Log),预写日志机制,当Executor备份完数据之后,向HDFS中也备份一份数据,备份完成之后,再去更新消费者offset,如果开启WAL机制,可以将接收来的数据存储级别降级,例如,MEMORY_AND_DISK_SER。开启WAL机制要设置checkpoint。
开启WAL机制,带来了新问题
必须数据备份到HDFS完成之后,才会更新offset,下一步才会汇报数据位置,再发task处理数据,会造成数据处理的延迟加大。
Reveiver模式的并行度:[每一批次生成的DStream中的RDD的分区数]
spark.streaming.blockInterval = 200ms,在batchInterval内每个200ms,将接收来的数据封装到一个block中,batchInterval时间内生成的这些block组成了当这个batch。假设batchInterval = 5s ,5s内生成的batch中就有25个block。RDD->partition.batch->block,这里每一个block就是对应RDD中的partition。
如何提高RDD的并行度:当在batchInterval时间一定情况下,减少spark.streaming.blockInterval值,建议这个值不要低于50ms。
SparkStreaming + Kafka Reveiver模式:
- 存在数据丢失问题,不常用
- 即使开始了WAL机制解决了丢失数据问题,但是,数据处理延迟大。
- Reveiver模式底层消费kafka,采用的是High Level Consumer API实现,不关心消费者offset,无法从每批次中获取消费者offset和指定总某个offset继续消费数据。
- Receiver模式采用zookeeper来维护消费者offset。
二、SparkStreaming + Kafka Direct模式
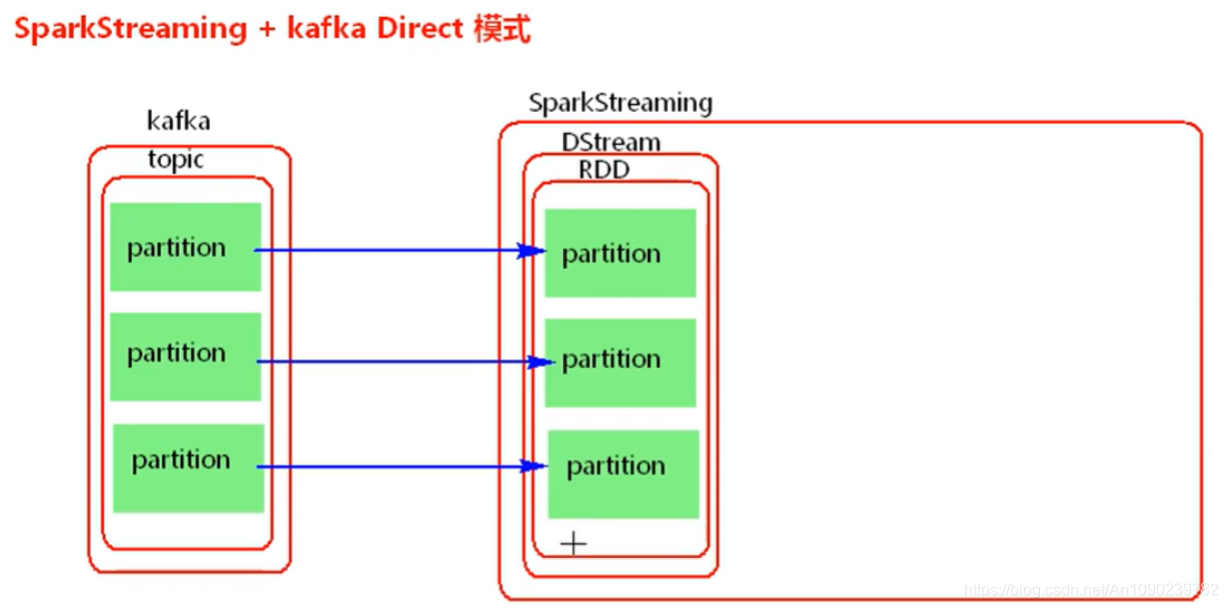
Spark Streaming + Kafka Direct模式:
不需要一个task一直接收数据,当前批次处理数据时,直接读取数据处理,Direct模式并行度与读取的topic中的partition的个数一对一。
SparkStreaming+kafka 的Driect模式就是将kafka看成存数据的一方,不是被动接收数据,而是主动去取数据。消费者偏移量也不是用zookeeper来管理,而是SparkStreaming内部对消费者偏移量自动来维护,默认消费偏移量是在内存中,当然如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。当然也可以实现用zookeeper来管理。
Direct模式使用Spark 来自己来维护消费者offset,默认offset存储在内存中,如果设置了checkpoint,在checkpoint中也有一份,Direct模式可以做到手动维护消费者offset。
如何提高并行度?
- 增大读取的topic中的partition个数
- 读取过来DStream之后,可以重新分区
三、Direct模式与Receiver模式比较
- 简化了并行度,默认的并行度与读取的kafka中的topic的partition个数一对一。
- Reveiver模式采用zookeeper来维护消费者offset,Direct模式使用Spark来自己维护消费者offset。
- Receiver模式采用消费Kafka的High Level Consumer API实现,Direct模式采用的是读取kafka的Simple Consumer API可以做到手动维护offset。
SparkStreaming2.3+kafka 改变
1)丢弃了SparkStreaming+kafka 的receiver模式。
2)采用了新的消费者api实现,类似于1.6中SparkStreaming 读取 kafka Direct模式。并行度一样。
3)因为采用了新的消费者api实现,所有相对于1.6的Direct模式【simple api实现】 ,api使用上有很大差别。未来这种api有可能继续变化
4)kafka中有两个参数:
heartbeat.interval.ms:这个值代表 kafka集群与消费者之间的心跳间隔时间,kafka 集群确保消费者保持连接的心跳通信时间间隔。这个时间默认是3s.这个值必须设置的比session.timeout.ms appropriately 小,一般设置不大于 session.timeout.ms appropriately 的1/3。
session.timeout.ms appropriately:这个值代表消费者与kafka之间的session 会话超时时间,如果在这个时间内,kafka 没有接收到消费者的心跳【heartbeat.interval.ms 控制】,那么kafka将移除当前的消费者。这个时间默认是10s。这个时间是位于 group.min.session.timeout.ms【6s】 和 group.max.session.timeout.ms【300s】之间的一个参数,如果SparkSteaming 批次间隔时间大于5分钟,也就是大于300s,那么就要相应的调大group.max.session.timeout.ms 这个值。
5)大多数情况下,SparkStreaming读取数据使用 LocationStrategies.PreferConsistent
这种策略,这种策略会将分区均匀的分布在集群的Executor之间。 如果Executor在kafka 集群中的某些节点上,可以使用
LocationStrategies.PreferBrokers 这种策略,那么当前这个Executor
中的数据会来自当前broker节点。 如果节点之间的分区有明显的分布不均,可以使用
LocationStrategies.PreferFixed 这种策略,可以通过一个map 指定将topic分区分布在哪些节点中。
6)新的消费者api 可以将kafka 中的消息预读取到缓存区中,默认大小为64k。默认缓存区在 Executor 中,加快处理数据速度。可以通过参数 spark.streaming.kafka.consumer.cache.maxCapacity 来增大,也可以通过spark.streaming.kafka.consumer.cache.enabled 设置成false 关闭缓存机制。
7)关于消费者offset
1).如果设置了checkpoint ,那么offset 将会存储在checkpoint中。这种有缺点:
第一,当从checkpoint中恢复数据时,有可能造成重复的消费,需要我们写代码来保证数据的输出幂等。第二,当代码逻辑改变时,无法从checkpoint中来恢复offset.
2).依靠kafka 来存储消费者offset,kafka 中有一个特殊的topic
来存储消费者offset。新的消费者api中,会定期自动提交offset。这种情况有可能也不是我们想要的,因为有可能消费者自动提交了offset,但是后期SparkStreaming
没有将接收来的数据及时处理保存。这里也就是为什么会在配置中将enable.auto.commit
设置成false的原因。这种消费模式也称最多消费一次,默认sparkStreaming
拉取到数据之后就可以更新offset,无论是否消费成功。自动提交offset的频率由参数auto.commit.interval.ms
决定,默认5s。如果我们能保证完全处理完业务之后,可以后期异步的手动提交消费者offset.
3).自己存储offset,这样在处理逻辑时,保证数据处理的事务,如果处理数据失败,就不保存offset,处理数据成功则保存offset.这样可以做到精准的处理一次处理数据。
四、SparkStreaming+Kafka维护消费者offset
- 使用checkpoint管理消费者offset(Spark1.6+Spark2.3)
如果业务逻辑不变,可以使用checkpoint来管理消费者offset,使用StreamingContext.getOrCreate(checkpoint目录,StreamingContext)首先从checkpoint目录中回复Streaming配置信息、逻辑、offset。
如果业务逻辑变了,使用这种方式不会执行新的业务逻辑,恢复offset的同时,把旧的逻辑也恢复过来了。
如果业务逻辑不变,使用checkpoint维护消费者offset,存在重复消费数据问题,自己要保证后面处理数据的幂等性。
- 手动维护消费者offset(Spark1.6+Spark2.3)。
- 依赖于kafka自己维护消费者offset(Spark1.6+Spark2.3)。
五、实例:SparkStreaming集成Kafka,读取Kafka中数据,进行数据统计计算
实例来自:https://blog.csdn.net/jantelope/article/details/82502674 【Jantelope】
5.1 pom.xml
<properties>
<spark.version>2.1.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
启动kafka:bin/kafka-server-start.sh config/server.properties & —后台方式启动
创建topic:bin/kafka-topics.sh --create --zookeeper bigdata111:2181 -replication-factor 1 --partitions 3 --topic mydemo2
发布消息:bin/kafka-console-producer.sh --broker-list bigdata111:9092 --topic mydemo2
5.2模式一:Receiver模式:对于所有的Receivers,接收到的数据将会保存在Spark executors中,然后由Spark Streaming启动的Job来处理这些数据。
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.storage.StorageLevel
object KafkaRecciver {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("hdfs://bigdata111:9000/checkpoint")
//创建kafka对象 生产者 和消费者
//模式1 采取的是 receiver 方式 reciver 每次只能读取一条记录
val topic = Map("mydemo2" -> 1)
//直接读取的方式 由于kafka 是分布式消息系统需要依赖Zookeeper
val data = KafkaUtils.createStream(ssc, "192.168.128.111:2181", "mygroup", topic, StorageLevel.MEMORY_AND_DISK)
//数据累计计算
val updateFunc =(curVal:Seq[Int],preVal:Option[Int])=>{
//进行数据统计当前值加上之前的值
var total = curVal.sum
//最初的值应该是0
var previous = preVal.getOrElse(0)
//Some 代表最终的返回值
Some(total+previous)
}
val result = data.map(_._2).flatMap(_.split(" ")).map(word=>(word,1)).updateStateByKey(updateFunc).print()
//启动ssc
ssc.start()
ssc.awaitTermination()
}
}
5.3模式二:Direct模式:当作业需要处理的数据来临时,spark通过调用Kafka的简单消费者API读取一定范围的数据。
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkKafka {
def main(args: Array[String]): Unit = {
//构建conf ssc 对象
val conf = new SparkConf().setAppName("Kafka_director").setMaster("local[1]")
val ssc = new StreamingContext(conf, Seconds(3))
//设置数据检查点进行累计统计单词
//ssc.checkpoint("hdfs://192.168.xx.xx:9000/checkpoint")
//在D盘新建一个文件目录wordcount
ssc.checkpoint("D:/wordcount")
//kafka 需要Zookeeper 需要消费者组
val topics = Set("SparkKafka")
// broker的原信息 ip地址以及端口号
val kafkaPrams = Map[String, String]("metadata.broker.list" -> "192.168.xx.xx:9092")
// 数据的输入了类型 数据的解码类型
val data = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaPrams, topics)
val updateFunc = (curVal: Seq[Int], preVal: Option[Int]) => {
//进行数据统计当前值加上之前的值
val total = curVal.sum
//最初的值应该是0
var previous = preVal.getOrElse(0)
//Some 代表最终的但会值
Some(total + previous)
}
//统计结果
val result = data.map(_._2).flatMap(_.split(" ")).map(word => (word, 1)).updateStateByKey(updateFunc).print()
//启动程序
ssc.start()
ssc.awaitTermination()
}
}
SparkStreaming读取kafka数据-DirectStream方式
(
该部分内容来源:作者:黑暗行动,地址:https://blog.csdn.net/chy2z/article/details/85228019
)
项目依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.3.0</version>
</dependency>
dircet方式的优点
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。
checkpoint 使用方式
//设置保存点
jssc.checkpoint("src/main/resources/checkpoint");
那么如何利用保存点恢复数据呢,查看源码利用JavaStreamingContext.getOrCreate实现?
object JavaStreamingContext {
/**
* Either recreate a StreamingContext from checkpoint data or create a new StreamingContext.
* If checkpoint data exists in the provided `checkpointPath`, then StreamingContext will be
* recreated from the checkpoint data. If the data does not exist, then the provided factory
* will be used to create a JavaStreamingContext.
*
* @param checkpointPath Checkpoint directory used in an earlier JavaStreamingContext program
* @param creatingFunc Function to create a new JavaStreamingContext
*/
def getOrCreate(
checkpointPath: String,
creatingFunc: JFunction0[JavaStreamingContext]
): JavaStreamingContext = {
val ssc = StreamingContext.getOrCreate(checkpointPath, () => {
creatingFunc.call().ssc
})
new JavaStreamingContext(ssc)
}
JavaStreamingContext.getOrCreate 使用要点:
* 1: 不存在checkpoint目录时,创建新的JavaStreamingContext,同时编写执行 dstream 业务代码
* 2: 当程序终止在次运行程序时,发现checkpoint目录存在,通过checkpoint恢复程序运行,记住不需要再次执行 dstream 业务代码,否则会报
org.apache.spark.SparkException: org.apache.spark.streaming.dstream.FlatMapp@5a69b104 has not been initialized,
所以 dstream 业务代码 只需要在创建新的JavaStreamingContext时执行一次就够了!!!!切记!!!
实例源码:
package com.chy.streaming;
import com.chy.util.SparkUtil;
import kafka.serializer.StringDecoder;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.Function0;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
import java.util.*;
import java.util.regex.Pattern;
/**
以DStream中的数据进行按key做reduce操作,然后对各个批次的数据进行累加
在有新的数据信息进入或更新时。能够让用户保持想要的不论什么状。使用这个功能须要完毕两步:
1) 定义状态:能够是随意数据类型
2) 定义状态更新函数:用一个函数指定怎样使用先前的状态。从输入流中的新值更新状态。
对于有状态操作,要不断的把当前和历史的时间切片的RDD累加计算,随着时间的流失,计算的数据规模会变得越来越大。
*/
public class KafkaStreamUpdateStateByKey {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) {
String brokers="localhost:9092";
String topics = "spark_uds_topic";
String groupid = "spark_streaming_group";
Set<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
Map<String, String> kafkaParams = new HashMap<>();
kafkaParams.put("metadata.broker.list", brokers);
kafkaParams.put("group.id", groupid);
//程序重新启动后从最老的加载,数据重复
//kafkaParams.put("auto.offset.reset", "smallest");
//程序重新启动后从最新的加载,数据丢失
kafkaParams.put("auto.offset.reset", "largest");
String directory="src/main/resources/checkpoint/KafkaStreamUpdateStateByKey";
JavaStreamingContext jssc=JavaStreamingContext.getOrCreate(directory, new Function0<JavaStreamingContext>() {
@Override
public JavaStreamingContext call() throws Exception {
JavaStreamingContext jssc = SparkUtil.getJavaStreamingContext(10000);
//设置检查点保存路径
jssc.checkpoint(directory);
JavaPairInputDStream<String, String> messages = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topicsSet
);
//设置检查点保存时间
messages.checkpoint(new Duration(10000));
JavaDStream<String> lines = messages.map(Tuple2::_2);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());
words.print();
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(s -> new Tuple2<>(s, 1))
.updateStateByKey(new Function2<List<Integer>, org.apache.spark.api.java.Optional<Integer>, org.apache.spark.api.java.Optional<Integer>>() {
@Override
public org.apache.spark.api.java.Optional<Integer> call(List<Integer> values, org.apache.spark.api.java.Optional<Integer> state) throws Exception {
//第一个参数就是key传进来的数据,第二个参数是曾经已有的数据
//如果第一次,state没有,updatedValue为0,如果有,就获取
Integer updatedValue = 0 ;
if(state.isPresent()){
updatedValue = state.get();
}
//遍历batch传进来的数据可以一直加,随着时间的流式会不断去累加相同key的value的结果。
for(Integer value: values){
updatedValue += value;
}
//返回更新的值
return Optional.of(updatedValue);
}
});
wordCounts.print();
return jssc;
}
});
jssc.start();
try {
jssc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
System.out.println("Shutdown hook run!");
jssc.stop(true,true);
}
});
}
}
六、实例:spark streaming+kafka随机wordcount统计
开发步骤
- SparkStreaming与Kafka整合
- 1:启动zkServer.start
- 2:启动kafka-server-start.sh /config/server.properties
- 3:在Kafka集群中创建主题(或者通过写一个Producer创建主题,若当前主题没有,则自动创建)
- 4:写一个Producer主题随机发送a-z的单词
- 5:写一个Streaming从Kafka的主题消费数据
- 6:对接收的数据进行切分做wordCount统计
- 7:将算好的当前批次的wordCount存储到redis
pom.xml
<properties>
<spark.version>2.3.0</spark.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<!--kafka_2.12-2.2.0-->
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
随机单词生成器
import java.util.{Properties, Random}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
/**
* 随机单词生成器
* SparkStreaming与Kafka整合
* 1:启动zkServer.start
* 2:启动kafka-server-start.sh /config/server.properties
* 3:在Kafka集群中创建主题(或者通过写一个Producer创建主题,若当前主题没有,则自动创建)
* 4:写一个Producer主题随机发送a-z的单词
* 5:写一个Streaming从Kafka的主题消费数据
* 6:对接收的数据进行切分做wordCount统计
* 7:将算好的当前批次的wordCount存储到redis
*/
object RandomWordGenerator {
def main(args: Array[String]): Unit = {
val props = new Properties()
//告诉客户端,Kafka服务器在哪里
props.setProperty("bootstrap.servers", " ")
//设置Key和value的序列化方式
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//[all,-1,0,1]
props.setProperty("acks", "1")
val producerClient = new KafkaProducer[String, String](props)
while (true) {
Thread.sleep(100)
val wordIndex = new Random().nextInt(26)
val assiCode = (wordIndex + 97).asInstanceOf[Char]
val word = String.valueOf(assiCode)
val record = new ProducerRecord[String, String]("wordcount", word, word)
producerClient.send(record)
}
}
}
JPools连接池
import redis.clients.jedis.{JedisPool, JedisPoolConfig}
object JPools {
private val jedisPoolConfig = new JedisPoolConfig()
jedisPoolConfig.setMaxTotal(2000)
jedisPoolConfig.setMaxIdle(1000)
jedisPoolConfig.setTestOnBorrow(true)
jedisPoolConfig.setTestOnReturn(true)
private val jedisPool = new JedisPool(jedisPoolConfig, "host")
def getJedis = jedisPool.getResource
}
SparkStreaming与Kafka整合
import Utils.JPools
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.codehaus.jackson.map.deser.std.StringDeserializer
/**
* SparkStreaming与Kafka整合
* 1:启动zkServer.start
* 2:启动kafka-server-start.sh /config/server.properties
* 3:在Kafka集群中创建主题(或者通过写一个Producer创建主题,若当前主题没有,则自动创建)
* 4:写一个Producer主题随机发送a-z的单词
* 5:写一个Streaming从Kafka的主题消费数据
* 6:对接收的数据进行切分做wordCount统计
* 7:将算好的当前批次的wordCount存储到redis
*/
object WordCountKafka {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("WordCountKafka")
.setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "text-consumer-group",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("wordcount")
//获取数据
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd => {
rdd.map(record => (record.value(), 1))
.reduceByKey(_ + _) //当前的批次结果
.foreachPartition(iter => {
val jedis = JPools.getJedis
//插入到redis
iter.foreach(tp => {
jedis.hincrBy("wordcount", tp._1, tp._2)
})
jedis.close()
})
})
ssc.start()
ssc.awaitTermination()
}
}
七、Springboot最简单的实战介绍 整合kafka-生产者与消费者(消息推送与订阅获取)
该实例出处:Springboot最简单的实战介绍 整合kafka-生产者与消费者(消息推送与订阅获取
(1)pom.xml添加kafka的依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
(2)application.properties
#============== kafka ===================
# 指定kafka 代理地址,可以多个
#spring.kafka.bootstrap-servers=123.xxx.x.xxx:19092,123.xxx.x.xxx:19093,123.xxx.x.xxx:19094
spring.kafka.bootstrap-servers=192.168.x.xxx:9092
#=============== producer生产者 =======================
spring.kafka.producer.retries=0
# 每次批量发送消息的数量
spring.kafka.producer.batch-size=16384
# 缓存容量
spring.kafka.producer.buffer-memory=33554432
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#=============== consumer消费者 =======================
# 指定默认消费者group id
spring.kafka.consumer.group-id=test-app
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100ms
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
#spring.kafka.consumer.bootstrap-servers=192.168.8.111:9092
#spring.kafka.consumer.zookeeper.connect=192.168.8.103:2181
#指定tomcat端口
server.port=8063
(3)application.yml:
spring:
# KAFKA
kafka:
# ָkafka服务器地址,可以指定多个
bootstrap-servers: 123.xxx.x.xxx:19092,123.xxx.x.xxx:19093,123.xxx.x.xxx:19094
#=============== producer生产者配置 =======================
producer:
retries: 0
# 每次批量发送消息的数量
batch-size: 16384
# 缓存容量
buffer-memory: 33554432
# ָ指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
#=============== consumer消费者配置 =======================
consumer:
#指定默认消费者的group id
group-id: test-app
#earliest
#当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
#latest
#当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
#none
#topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: latest
enable-auto-commit: true
auto-commit-interval: 100ms
#指定消费key和消息体的编解码方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
(4)KafkaSender:kafka生产者
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.sun.scenario.effect.impl.sw.sse.SSEBlend_SRC_OUTPeer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
@Component
public class KafkaSender {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
private final Logger logger = LoggerFactory.getLogger(KafkaSender.class);
public void send(String topic, String taskid, String jsonStr) {
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, taskid, jsonStr);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
//推送成功
public void onSuccess(SendResult<String, Object> result) {
logger.info(topic + " 生产者 发送消息成功:" + result.toString());
}
@Override
//推送失败
public void onFailure(Throwable ex) {
logger.info(topic + " 生产者 发送消息失败:" + ex.getMessage());
}
});
}
}
创建个controller,搞个接口试试推送下消息,
@GetMapping("/sendMessageToKafka")
public String sendMessageToKafka() {
Map<String,String> messageMap=new HashMap();
messageMap.put("message","我是一条消息");
String taskid="123456";
String jsonStr=JSONObject.toJSONString(messageMap);
//kakfa的推送消息方法有多种,可以采取带有任务key的,也可以采取不带有的(不带时默认为null)
kafkaSender.send("testTopic",taskid,jsonStr);
return "hi guy!";
}
(5)KafkaConsumer :kafka的消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Controller;
import javax.servlet.http.HttpSession;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@Component
public class KafkaConsumer {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
//下面的主题是一个数组,可以同时订阅多主题,只需按数组格式即可,也就是用“,”隔开
@KafkaListener(topics = {"testTopic"})
public void receive(ConsumerRecord<?, ?> record){
logger.info("消费得到的消息---key: " + record.key());
logger.info("消费得到的消息---value: " + record.value().toString());
}
}