Mycat安装并实现mysql读写分离,分库分表
原文地址:
CSDN:SophiaLeo:Mycat安装并实现mysql读写分离,分库分表
对于环境要求,先需要安装好JDK,建议1.8及以上。
一、安装Mycat
- 搭建mysql的主从复制,二择其一 :
- 环境:
- mysql主 192.168.21.55
- mysql从 192.168.21.55
- mycat 192.168.21.55
1.1 创建文件夹
mkdir -p /usr/local/mycat
cd /usr/local/mycat
1.2 下载
- 去官网下载,并用xftp把下载的mycat放入/usr/local/mycat
- 解压:
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz

二、mycat具体配置
- server.xml : 是Mycat服务器参数调整和用户授权的配置文件
- schema.xml : 是逻辑库定义和表以及分片定义的配置文件
- rule.xml : 是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件
2.1 server.xml
<property name="sequnceHandlerType">0</property>
<user name="root">
<property name="password">root</property>
<property name="schemas">test</property>
</user>
- sequnceHandlerType
- 0 : 使用本地方式作为数据库自增,设置 sequence_conf.properties配置文件
- GLOBAL.HISIDS=
- GLOBAL.MINID=10001 最小值
- GLOBAL.MAXID=20000 最大值
- GLOBAL.CURID=10000 当前值
- 1 : 使用的是本地数据库的方式,需要在一个分节点创建MYCAT_SEQUENCE表和存储过程,其中MYCAT_SEQUENCE必须为大写
- 2 : 自动生成64为的时间戳,设置配置sequence_db_conf.properties,指定sequence相关配置在哪个节点上
- 0 : 使用本地方式作为数据库自增,设置 sequence_conf.properties配置文件
- name : 用户名
- password : 用户密码
- schemas : mycat逻辑库,对应schemas.xml里schema标签的name属性,多个逻辑库用逗号隔开
2.2 schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="tb_user" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3,dn4" rule="userrule" />
<table name="tb_category" primaryKey="id" dataNode="dn1,dn2,dn3,dn4" rule="categoryrule" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataNode name="dn4" dataHost="localhost1" database="db4" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.0.131:3306" user="root"
password="root">
<readHost host="hostS2" url="192.168.0.108:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
- schema : 是实际逻辑库的配置,多个schema代表多个逻辑库
- table : 是逻辑表的配置
- name : 代表表名
- primaryKey : 主键
- autoIncrement : 开启自动增长,不使用自动增长就不要加
- dataNode : 代表表对应的分片,Mycat默认采用分库方式,也就是一个表映射到不同的库上,对应dataNode标签的name,多个用逗号隔开
- rule代表表要采用的数据切分方式,名称对应到rule.xml中tableRule标签的name属性,如果要分片必须配置
- table : 是逻辑表的配置
- dataNode : 是逻辑库对应的分片,如果配置多个分片只需要多个dataNode即可
- name : dataNode的名
- dataHost : 是实际的物理库配置地址,可以配置多主主从等其他配置,对应dataHost标签的name属性
- database : 映射实际的物理库
- dataHost : 配置物理库分片映射
- balance : 读的负载均衡类型
- balance=“0” : 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
- balance=“1” : 全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡
- balance=“2” : 所有读操作都随机的在writeHost、readhost上分发
- balance=“3” : 所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost不负担读压力注意,只在 1.4 及其以后版本有
- writeType : 写的负载均衡类型
- writeType=“0” : 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 ,writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties
- writeType=“1” : 所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐
- switchType : 切换的模式
- switchType="-1" : 表示不自动切换
- switchType=“1” : 默认值,表示自动切换
- switchType=“2” : 基于MySQL主从同步的状态决定是否切换,心跳语句为 show slave status;
- switchType=“3” : 基于MySQL galary cluster的切换机制(适合集群)心跳语句为 show status like ‘wsrep%’;
- writeHost : 逻辑主机(dataHost)对应的后端的物理主机映射.mysql主
- readHost : mysql从
- balance : 读的负载均衡类型
2.3 sequence_conf.properties
- “sequnceHandlerType” 0
- autoIncrement=“true”
TB_USER.HISIDS=
TB_USER.MINID=1
TB_USER.MAXID=20000
TB_USER.CURID=1
2.4 rule.xml
<tableRule name="userrule">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="categoryrule">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
- tableRule
- name : schema.xml中table标签中对应的rule属性,也就是配置表的分片规则
- columns : 是表的切分字段
- algorithm : 是规则对应的切分规则,对应function标签的name属性
- function : 配置是分片规则的配置
- name : 切分规则的名称,对应tableRule标签的algorithm属性
- class : 是切分规则对应的切分类,写死,需要哪种规则则配置哪种
- property : 标签是切分规则对应的不同属性,不同的切分规则配置不同
三、启动mycat
- 配置实际mysql数据库,在mysql主上建4个数据库db1,db2,db3,db4(不要操作从机)
- 放行端口号
firewall-cmd --zone=public --add-port=8066/tcp --permanent
firewall-cmd --zone=public --add-port=9066/tcp --permanent
firewall-cmd --reload
- 启动mycat
cd /usr/local/mycat/mycat/bin
./mycat start
- 连接mycat
- Linux
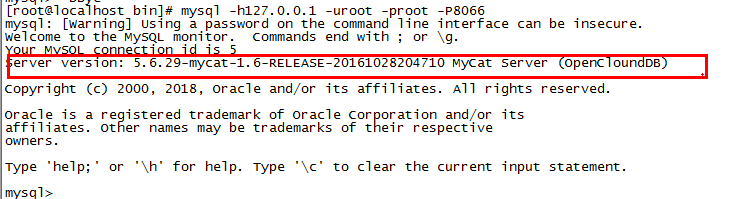
mysql -h127.0.0.1 -uroot -proot -P8066
出现mycat就表示成功:
- 可视化工具
- 如果有错误,查看logs/wrapper.log
tail -f /usr/local/mycat/mycat/logs/wrapper.log
- 管理端口执行管理命令
mysql -h127.0.0.1 -uroot -proot -P9066
- 查看所有命令
show @@help;
- 开始创建刚刚配置的逻辑库,逻辑表
show databases;
use test;
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户名',
`password` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '密码,加密存储',
`phone` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册手机号',
`email` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '注册邮箱',
`created` datetime(0) NOT NULL,
`updated` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `username`(`username`) USING BTREE,
UNIQUE INDEX `phone`(`phone`) USING BTREE,
UNIQUE INDEX `email`(`email`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 54 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '用户表' ROW_FORMAT = Compact;
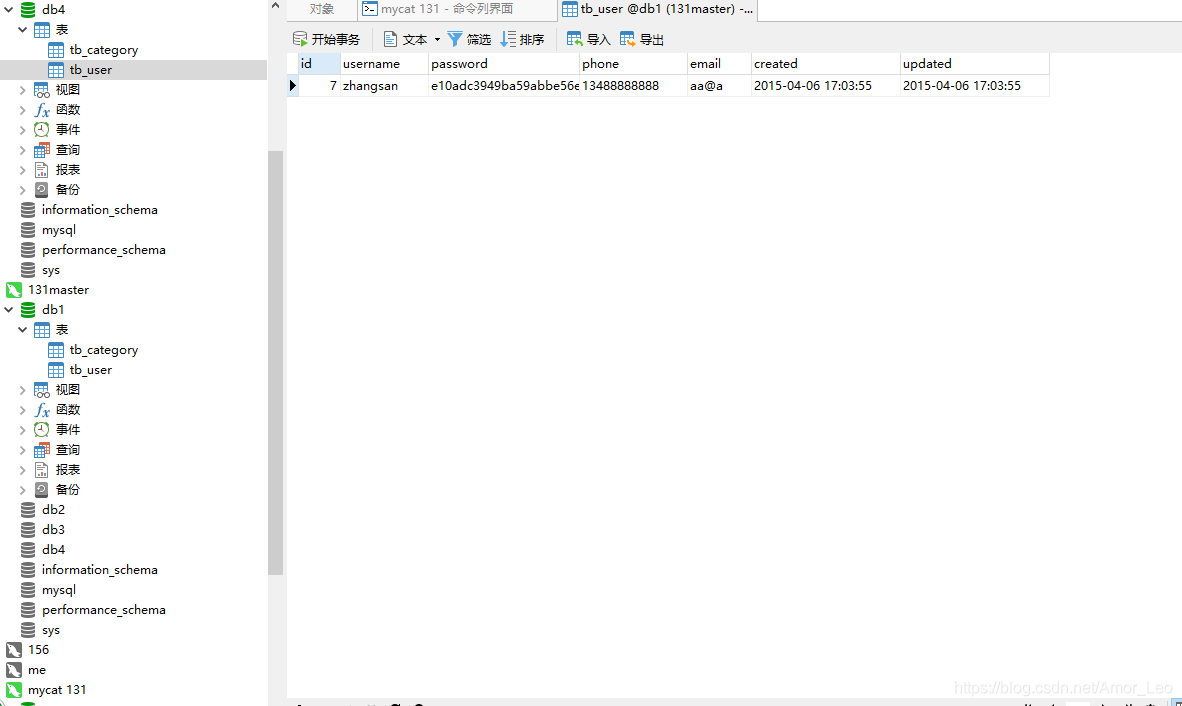
可以看到mycat,mysql主从都创建了该表:
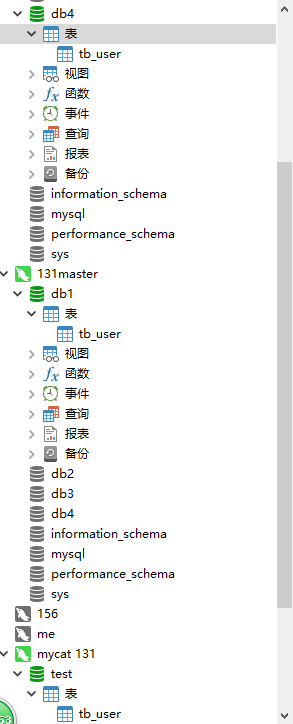
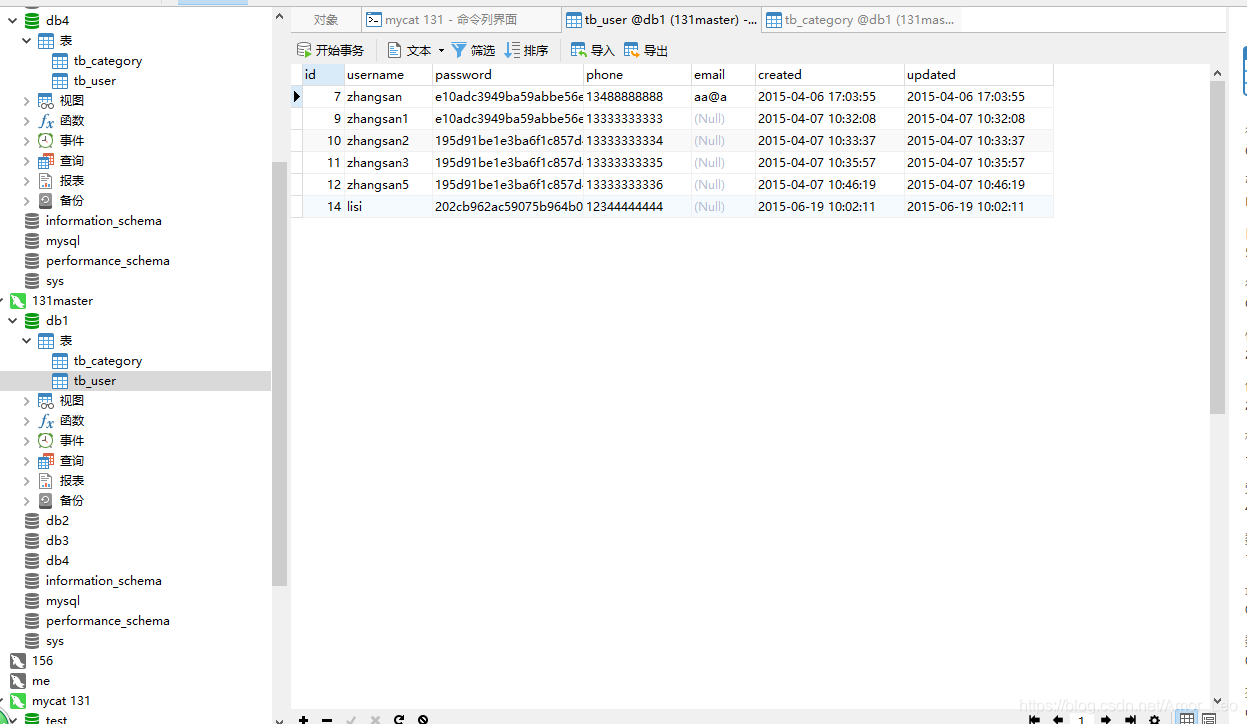
- 再建一张表
CREATE TABLE `tb_category` (
`id` varchar(5) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`name` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '名字',
`sort_order` int(4) NOT NULL DEFAULT 1 COMMENT '排列序号,表示同级类目的展现次序,如数值相等则按名称次序排列。取值范围:大于零的整数',
`created` datetime(0) NULL DEFAULT NULL,
`updated` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `updated`(`updated`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
再插入数据:
INSERT INTO `tb_user`(id,username,password,phone,email,created,updated) VALUES (7, 'zhangsan', 'e10adc3949ba59abbe56e057f20f883e', '13488888888', 'aa@a', '2015-04-06 17:03:55', '2015-04-06 17:03:55');
如果报ERROR 1064 (HY000): insert must provide ColumnList
插入数据时一定要把所有字段带上
- 可以看到mysql主从里已经添加了数据