-
回归问题:利用大量的样本D=(xi, yi),i是1到N,通过有监督的学习,学习到由x到y的映射f,利用该映射关系对未知的数据进行预估,因为y是连续值,所以是回归问题
-
如果只有一个变量
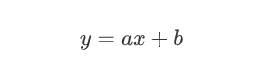
-
如果是n个变量
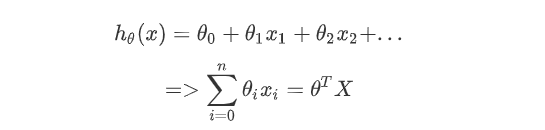
-
-
线性回归表达式:机器学习是数据驱动的算法,数据驱动=数据+模型,模型就是输入到输出的映射关系
模型 = 假设函数(不同的学习方式) + 优化
-
假设函数
线性回归的假设函数(θ0表示截距项,x0=1,θ,X表示列向量)
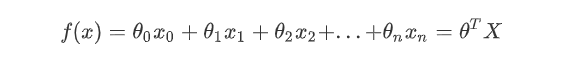
-
优化方法:监督学习的优化方法=损失函数+对损失函数的优化
-
损失函数:损失函数度量预测值和标准答案的偏差,不同的参数有不同的偏差,所以要通过最小化损失函数,也就是最小化偏差来得到最好的参数
映射函数:hθ(x)
损失函数:(由于有m个样本,所以要平均,分母的2是为了方便求导),是一个凹函数
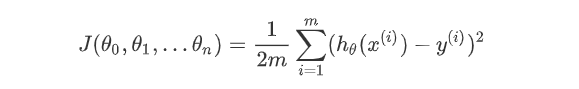
-
损失函数的优化:只有最小值,损失函数的值最小。但是如果存在3维及以上,计算量很大,极值难求
-
梯度下降法:求极值(3维及以上)
[梯度求解过程] https://blog.csdn.net/weixin_34266504/article/details/94540839 -
过拟合和欠拟合:导致模型泛化能力不高的两种常见的原因,都是模型学习能力与数据复杂度之间失配的结果
-
过拟合的定义:在训练集上表现良好,在测试集上表现糟糕
-
过拟合的原因:如果我们有很多的特征或者模型很复杂,则假设函数曲线可以对训练样本你和的非常好,学习能力太强了,但是丧失了一般性。眼见不一定为实,训练样本中肯定存在噪声点,如果全都学习的话肯定会将噪声学习进去。
-
过拟合的后果:过拟合是给参数的自由空间太大了,可以通过简单的方式让参数变化太快,并未学习到底层的规律,模型抖动太大,很不稳定,方差变大,对新数据没有泛化能力
-
过拟合的预防:获取更多数据,减少特征变量,限制权值(正则化),贝叶斯方法,结合多种模型
-
欠拟合的定义:在训练集和测试集上表现都糟糕
-
欠拟合的原因:由于数据复杂度较高的情况的出现,此时模型的学习能力不足,无法学习到数据集的“一般规律”
-
欠拟合的预防:引入新的特征,添加多项式特征,,减少正则化参数
-
-
利用正则化解决过拟合问题
-
正则化的作用:控制参数变化幅度,对变化大的参数惩罚;限制参数搜索空间
-
添加正则化的损失函数
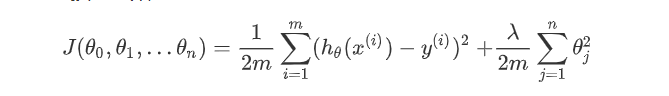
函数说明:m表示样本个数,n表示n个参数,对n个参数进行惩罚,λ表示对误差的惩罚程度,λ越大对误差的惩罚越大,容易出现过拟合,λ越小对误差的惩罚越小,对误差的容忍度的越大,泛化能力越好
-
-
-
编码实现
import pandas as pd import numpy as np from matplotlib import pyplot as plt from sklearn.linear_model import LinearRegression from mpl_toolkits.mplot3d import axes3d import seaborn as sns class MyRegression: def __init__(self): pd.set_option("display.notebook_repr_html", False) pd.set_option("display.max_columns", None) pd.set_option("display.max_rows", None) pd.set_option("display.max_seq_items", None) sns.set_context("notebook") sns.set_style("white") self.warmUpExercise = np.identity(5) self.data = np.loadtxt("testSet.txt", delimiter=" ") # 100*2 self.x = np.c_[np.ones(self.data.shape[0]), self.data[:, 0]] # 100*1 self.y = np.c_[self.data[:, 1]] def data_view(self): plt.scatter(self.x[:, 1], self.y, s=30, c="r", marker="x", linewidths=1) plt.xlabel("x轴") plt.ylabel("y轴") plt.show() # 计算损失函数 def compute_cost(self, theta=[[0], [0]]): m = self.y.size h = self.x.dot(theta) J = 1.0 / (2*m) * (np.sum(np.square(h - self.y))) return J # 梯度下降 def gradient_descent(self, theta=[[0], [0]], alpha=0.01, num_iters=100): m = self.y.size J_history = np.zeros(num_iters) for iters in np.arange(num_iters): h = self.x.dot(theta) # theta的迭代计算 theta = theta - alpha * (1.0 / m) * (self.x.T.dot(h-self.y)) J_history[iters] = self.compute_cost(theta) return theta, J_history def result_view1(self): theta, J_history = self.gradient_descent() plt.plot(J_history) plt.ylabel("Cost J") plt.xlabel("Iterations") plt.show() def result_view2(self): theta, J_history = self.gradient_descent() xx = np.arange(-5, 10) yy = theta[0] + theta[1] * xx # 画出我们自己写的线性回归梯度下降收敛的情况 plt.scatter(self.x[:, 1], self.y, s=30, c="g", marker="x", linewidths=1) plt.plot(xx, yy, label="Linear Regression (Gradient descent)") # 和Scikit-learn中的线性回归对比一下 regr = LinearRegression() regr.fit(self.x[:, 1].reshape(-1, 1), self.y.ravel()) plt.plot(xx, regr.intercept_+regr.coef_*xx, label="Linear Regression (Scikit-learn GLM)") plt.xlabel("x轴") plt.ylabel("y轴") plt.legend(loc=4) plt.show() if __name__ == '__main__': my_regression = MyRegression() # my_regression.result_view1() my_regression.result_view2()