1-1 -用户行为日志概述
为什么要记录用户访问行为日志?
网站页面的访问量
网站的粘性
推荐
用户行为日志
Nginx ajax
用户行为日志:用户每次访问网站时所有的行为数据(访问、浏览、搜索、点击...)
用户行为轨迹、流量日志
日志数据内容
1)访问的系统属性:操作系统,浏览器等等
2)访问特征:点击的url,从哪个URL跳转过来的(referer),页面上的停留时间等
3) 访问信息:session_id,访问ip(访问城市)等
用户行为日志分析的意义
网站的眼睛 网站的神经 网站的大脑
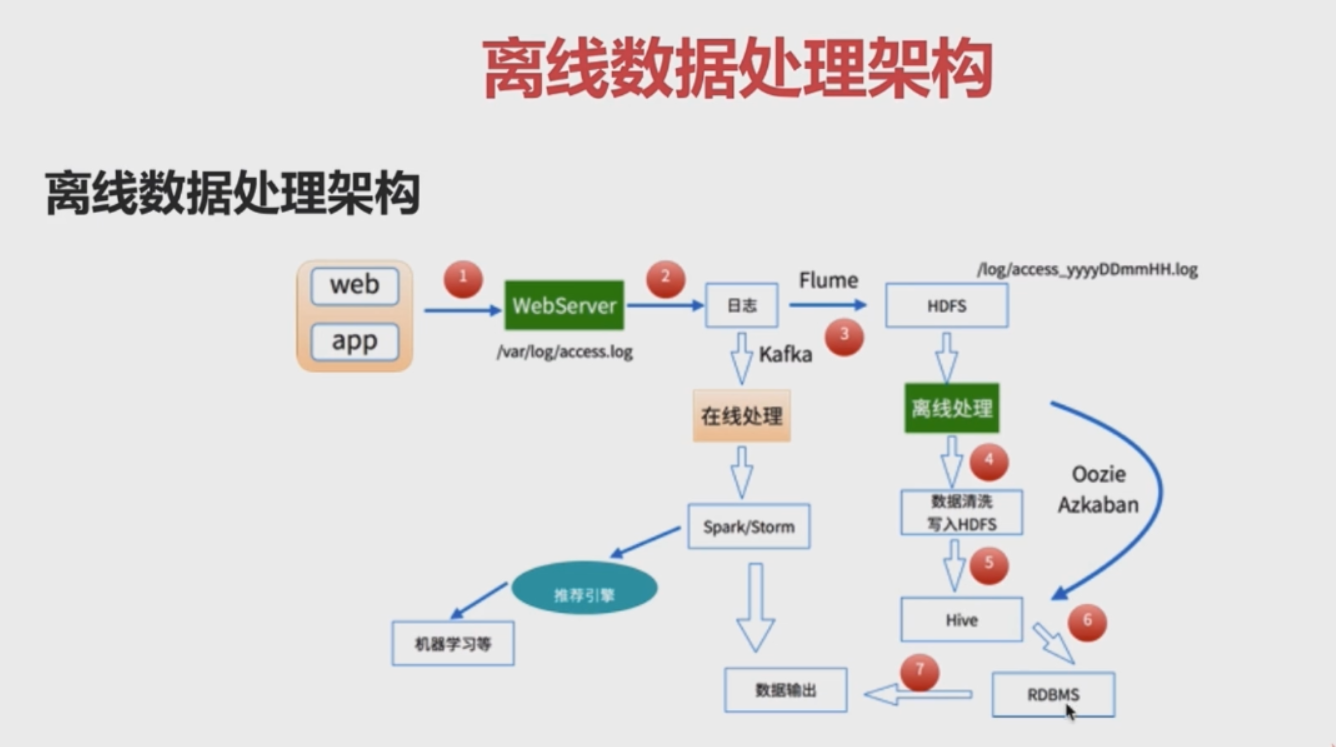
1-2 -离线数据处理架构
数据处理流程
1)数据采集
flume: web日志写入到HDFS
2)数据清洗
脏数据
spark、hive、MapReduce 或者是其他的一些分布式计算框架
清洗完之后的数据可以存放到HDFS(Hive/spark sql)
3)数据处理
按照我们的需要进行相应的统计和分析
spark、hive、MapReduce 或者是其他的一些分布式计算框架
4)处理结果入库
结果可以存放在RDBMS、Nosql
5)数据的可视化
通过图形化展示出来:饼图、柱状图、地图、折线图
ECharts、HUE、Zepplin6
1-3-项目需求



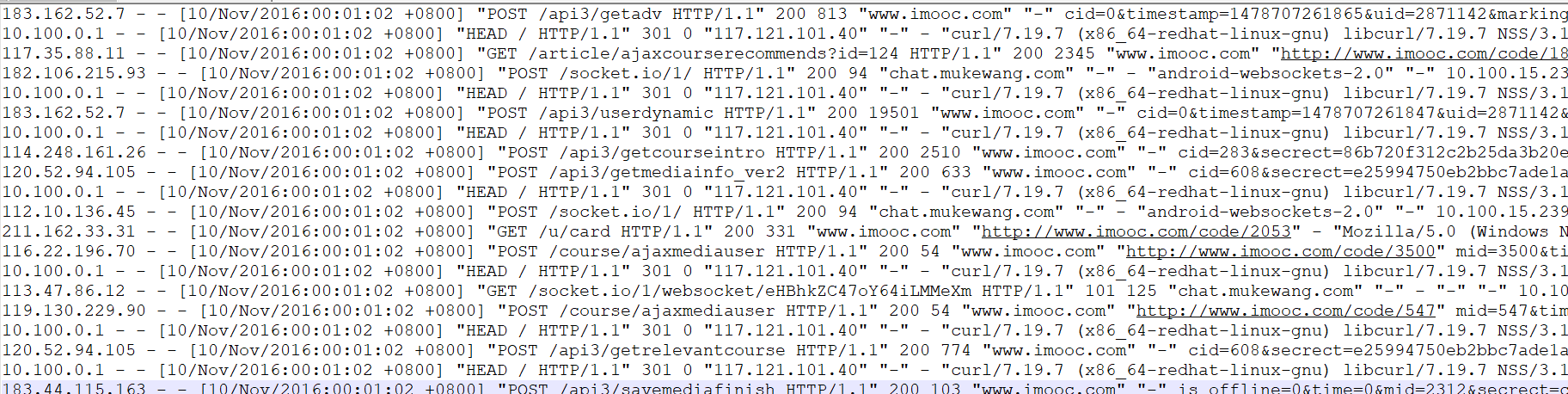
1-4 日志内容构成
1-5 数据清洗之第一步原始日志解析
日志解析代码(使用spark完成数据清洗操作)
package com.log
import org.apache.spark.sql.SparkSession
/**
*第一步清洗:抽取出我们所需要的指定列的数据
*/
object SparkStatFormatJob {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("SparkStatFormatJob")
.master("local[2]").getOrCreate()
val access=spark.sparkContext.textFile("E:\data\10000_access.log")
//access.take(10).foreach(println)
access.map(line=>{
val splits=line.split(" ")
val ip=splits(0)
/**
* [10/Nov/2016:00:01:02 +0800]=>yyyy-mm-dd hh:mm:ss
*/
try{
val time=splits(3)+" "+splits(4)
val url=splits(11).replaceAll(""","")
val traffic =splits(9)
(ip,DataUtils.parse(time),url,traffic)
DataUtils.parse(time)+" "+url+" "+traffic+" "+ip
}catch {
case e:Exception=>{
0l
}
}
}).saveAsTextFile("E:\data\output")
spark.stop()
}
}
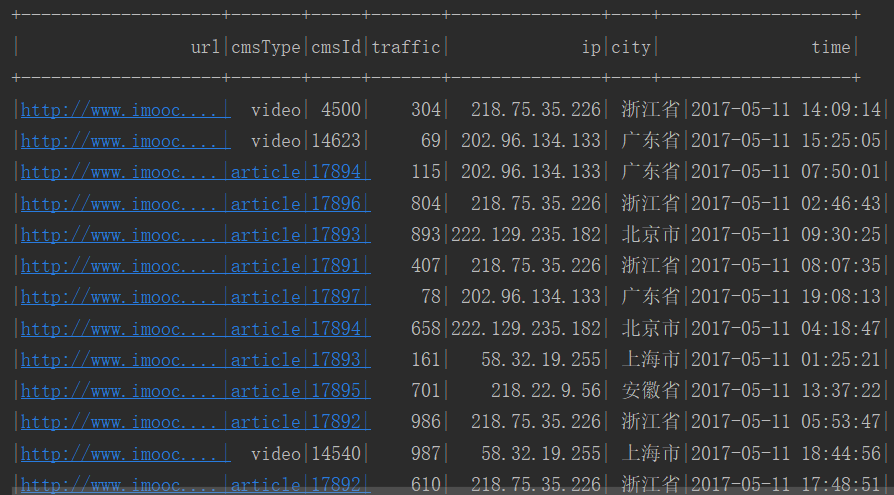
数据清洗结果:

1-6 -二次清洗
package com.log import org.apache.spark.sql.{SaveMode, SparkSession} /** *使用spark完成数据清洗操作 */ object SparkStatCleanJob { def main(args: Array[String]): Unit = { val spark=SparkSession.builder().appName("SparkStatCleanJob") .master("local[2]").getOrCreate() val accessRDD=spark.sparkContext.textFile("E:\data\spark\access.log") // accessRDD.take(10).foreach(println) val accessDF=spark.createDataFrame(accessRDD.map(line=>AccessConverUtil.parseLog(line)), AccessConverUtil.struct) // accessDF.printSchema() // accessDF.show() //coalesce文件输出数量(默认是多个文件) // mode(SaveMode.Overwrite)默认每次重写文件 accessDF.coalesce(1).write.format("parquet").partitionBy("day") .mode(SaveMode.Overwrite).save("E:\data\spark\clean") spark.stop() } }
访问日志转换工具类(输入=》输出)


package com.log import org.apache.spark.sql.Row import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType} /** * 访问日志转换工具类(输入=》输出) */ object AccessConverUtil { val struct=StructType( Array( StructField("url", StringType), StructField("cmsType", StringType), StructField("cmsId", LongType), StructField("traffic", LongType), StructField("ip", StringType), StructField("city", StringType), StructField("time", StringType), StructField("day", StringType) ) ) /** * 根据输入的每一行信息转换成输出的样式 * log 输入的每一行记录信息 */ def parseLog(log:String)={ try{ val splits=log.split(" ") val url=splits(1) val traffic=splits(2).toLong val ip=splits(3) val domain="http://www.imooc.com/" val cms=url.substring(url.indexOf(domain)+domain.length) val cmsTypeId=cms.split("/") var cmsType="" var cmsId=0l if(cmsTypeId.length>1){ cmsType=cmsTypeId(0) cmsId=cmsTypeId(1).toLong } val city=IpUtils.getCity(ip) val time=splits(0) val day=time.substring(0,10).replaceAll("-","") //Row字段与Strut字段对应 Row(url, cmsType, cmsId, traffic, ip, city, time, day) }catch { case e:Exception=>Row(0) } } }
清洗结果
1-7-需求功能实现
1.使用DataFreame API完成统计分析
2.使用SQL API完成统计分析
3.将统计分析结果写入到MySQL数据库
package com.log import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.sql.functions._ import org.apache.spark.sql.expressions.Window import scala.collection.mutable.ListBuffer /** * TopN统计spark作业 */ object TopNStatJob { def main(args: Array[String]): Unit = { val spark=SparkSession.builder().appName("TopNStatJob") .config("spark.sql.sources.partitionColumnTypeInference.enabled","false") .master("local[2]").getOrCreate() val accessDF=spark.read.format("parquet").load("E:\data\spark\clean") //accessDF.show() val day="20170511" StatDao.deleteData(day) //最受欢迎的TopN课程 videoAccessTopNStat(spark,accessDF,day) // // //按照地市进行统计TopN课程 cityAccessTopNStat(spark,accessDF,day) // // //按照流量进行统计TopN课程 videoTrafficsTopNStat(spark,accessDF,day) spark.stop() } /** * 按照流量进行统计TopN课程 * @param spark * @param accessDF */ def videoTrafficsTopNStat(spark:SparkSession,accessDF:DataFrame,day:String)= { accessDF.createOrReplaceTempView("access_logs") val TrafficsAccessTopNDF = spark.sql("select day,cmsId,sum(traffic) as " + "traffics from access_logs where day="+day+" and cmsType='video' " + "group by day,cmsId order by traffics desc") //TrafficsAccessTopNDF.show() try{ TrafficsAccessTopNDF.foreachPartition(partitionOfRecords => { val list=new ListBuffer[DayVideoTrafficsStat] partitionOfRecords.foreach(info => { val day=info.getAs[String]("day") val cmsId=info.getAs[Long]("cmsId") val traffics=info.getAs[Long]("traffics") list.append(DayVideoTrafficsStat(day,cmsId,traffics)) }) StatDao.insertDayTrafficsVideoAccessTopN(list) }) }catch{ case e:Exception=>e.printStackTrace() } } /** * 按照地市进行统计TopN课程 * @param spark * @param accessDF */ def cityAccessTopNStat(spark:SparkSession,accessDF:DataFrame,day:String)={ accessDF.createOrReplaceTempView("access_logs") val cityAccessTopNDF = spark.sql("select day,city,cmsId, count(1) as " + "times from access_logs where day="+day+" and cmsType='video' " + "group by day,city,cmsId order by times desc") // cityAccessTopNDF.show() //window函数在spark sql的使用 val top3DF=cityAccessTopNDF.select(cityAccessTopNDF("day"), cityAccessTopNDF("city"),cityAccessTopNDF("cmsId"), cityAccessTopNDF("times"), row_number().over(Window.partitionBy(cityAccessTopNDF("city")) .orderBy(cityAccessTopNDF("times").desc) ).as("times_rank") ).filter("times_rank<=3")//.show(false) //Top3 try{ top3DF.foreachPartition(partitionOfRecords => { val list=new ListBuffer[DayCityVideoAccessStat] partitionOfRecords.foreach(info => { val day=info.getAs[String]("day") val cmsId=info.getAs[Long]("cmsId") val city=info.getAs[String]("city") val times=info.getAs[Long]("times") val timesRank=info.getAs[Int]("times_rank") list.append(DayCityVideoAccessStat(day,cmsId,city,times,timesRank)) }) StatDao.insertDayCityVideoAccessTopN(list) }) }catch{ case e:Exception=>e.printStackTrace() } } /** * 最受欢迎的TopN课程 * @param spark * @param accessDF */ def videoAccessTopNStat(spark:SparkSession,accessDF:DataFrame,day:String)={ //使用DataFrame方式进行统计 import spark.implicits._ // val videoAccessTopNDF=accessDF.filter($"day"==="20170511"&&$"cmsType"==="video") // .groupBy("day","cmsId").agg(count("cmsId") // .as("times")).orderBy($"times".desc) // //使用sql方式进行统计 accessDF.createOrReplaceTempView("access_logs") val videoAccessTopNDF = spark.sql("select day,cmsId, count(1) as " + "times from access_logs where day="+day+" and cmsType='video' " + "group by day,cmsId order by times desc") // videoAccessTopNDF.show() try{ videoAccessTopNDF.foreachPartition(partitionOfRecords => { val list=new ListBuffer[DayVideoAccessStat] partitionOfRecords.foreach(info => { val day=info.getAs[String]("day") val cmsId=info.getAs[Long]("cmsId") val times=info.getAs[Long]("times") list.append(DayVideoAccessStat(day,cmsId,times)) }) StatDao.insertDayVideoAccessTopN(list) }) }catch{ case e:Exception=>e.printStackTrace() } } }
1-8-统计结果可视化展示
