【设计思想】
(1)输入待分析的字符串。
语法如下:
a.关键字:begin,if,then,while,do,end.
b.运算符和界符::= + - * / < <= > >= <> = ; ( ) #
c.其他单词是标识符(ID)和整形常数(NUM):ID=letter(letter|digit)*,NUM=digitdigit*
d.空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
(2)扫描字符串,采用递归向下进行分析。
主要函数如下:
a.scaner()//词法分析函数,char token[8]用来存放构成单词符号的字符串;
b.parser()//语法分析,在语法分析的基础上插入相应的语义动作:将输入串翻译成四元式序列。只对表达式、赋值语句进行翻译。
c.emit(char *result,char *arg1,char *op,char *ag2)//该函数功能是生成一个三地址语句返回四元式表中。
d.char *newtemp()//该函数返回一个新的临时变量名,临时变量名产生的顺序为T1,T2,…。
【要求】
四元式表的结构如下:
struct {char result[8];
char ag1[8];
char op[8];
char ag2[8];
}quad[20];
(3)输出为三地址指令形式的四元式序列。
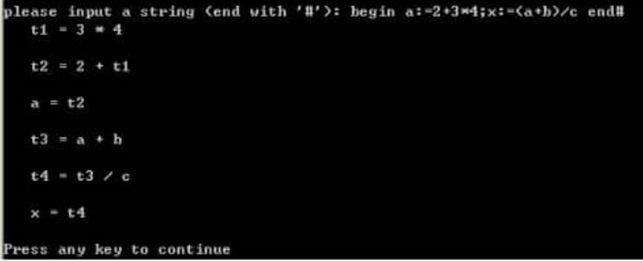
例如:语句串begin a:=2+3*4;x:=(a+b)/c;end#,
输出的三地址指令如下:
t1=3*4
t2=2+t1
a=t2
t3=a+b
t4=t3/c
x=t4
源程序
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<stdlib.h>
using namespace std;
struct {
char result[12];
char ag1[12];
char op[12];
char ag2[12];
}quad;
//变量的定义
char prog[80], token[12];
char ch; int syn, p, m = 0, n, sum = 0, kk; //p 是缓冲区 prog 的指针, m 是 token 的指针
char *rwtab[6] = { "begin", "if", "then", "while", "do", "end" };
void scaner();
char *factor(void);
char *term(void);
char *expression(void);
int yucu();
void emit(char *result, char *ag1, char *op, char *ag2);
char *newtemp();
int statement();
int k = 0;
void emit(char *result, char *ag1, char *op, char *ag2) {
strcpy_s(quad.result, result);
strcpy_s(quad.ag1, ag1);
strcpy_s(quad.op, op);
strcpy_s(quad.ag2, ag2);
//cout<<quad.result<<"="<<quad.ag1<<quad.op<<quad.ag2<<endl;
cout << "( " << quad.op << ", " << "entry(" << quad.ag1 << "), " << "entry(" << quad.ag2 << "), "<<quad.result<<") "<<endl;
//cout<<"entry("<<quad.ag1<<"entry("<<quad.op<<quad.ag2<<endl;
}
char *newtemp() {
char *p;
char m[12];
p = (char *)malloc(12);
k++;
_itoa_s(k, m, 10);
strcpy_s(p + 1, m);
p[0] = 't';
return (p);
}
//对字符的扫描
void scaner() {
for (n = 0; n<8; n++)
token[n] = NULL;
ch = prog[p++];
while (ch == ' ') {
ch = prog[p];
p++;
}
if ((ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z')) {
if ((ch >= 'a'&&ch <= 'c') || (ch >= 'A'&&ch <= 'C')){
m = 0;
while ((ch >= '0'&&ch <= '9') || (ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z')) {
token[m++] = ch;
ch = prog[p++];
}
token[m++] = '�';
p--;
syn = 10;
for (n = 0; n<6; n++) {
if (strcmp(token, rwtab[n]) == 0) {
syn = n + 1;
break;
}
}
}
else
cout << "Error!" << endl;
}
else if ((ch >= '0'&&ch <= '9')) {
{
sum = 0;
while ((ch >= '0'&&ch <= '9')) {
sum = sum * 10 + ch - '0';
ch = prog[p++];
}
}
p--;
syn = 11;
if (sum>32767)
syn = -1;
}
else switch (ch)
{
case'<':
m = 0;
token[m++] = ch;
ch = prog[p++];
if (ch == '>') {
syn = 21;
token[m++] = ch;
}
else if (ch == '=')
{
syn = 22;
token[m++] = ch;
}
else {
syn = 23;
p--;
}
break;
case'>':
m = 0;
token[m++] = ch;
ch = prog[p++];
if (ch == '=') {
syn = 24;
token[m++] = ch;
}
else {
syn = 20;
p--;
}
break;
case':':
m = 0; token[m++] = ch;
ch = prog[p++];
if (ch == '=') {
syn = 18;
token[m++] = ch;
}
else {
syn = 17;
p--;
}
break;
case'*':
syn = 13;
token[0] = ch;
break;
case'/':
syn = 14;
token[0] = ch;
break;
case'+':
syn = 15;
token[0] = ch;
break;
case'-':
syn = 16;
token[0] = ch;
break;
case'=':
syn = 25;
token[0] = ch;
break;
case';':
syn = 26;
token[0] = ch;
break;
case'(':
syn = 27;
token[0] = ch;
break;
case')':
syn = 28;
token[0] = ch;
break;
case'#':
syn = 0;
token[0] = ch;
break;
default:
syn = -1;
break;
}
}
int lrparser()
{
//cout<<" 调用 lrparser"<<endl;
int schain = 0;
kk = 0;
if (syn == 1) {
scaner();
schain = yucu();
//cout<<"SYN= "<<syn<<endl;
if (syn == 6) {
scaner();
if (syn == 0 && (kk == 0))
cout << "success!" << endl;
}
/* else
{
if(kk!=1)
cout<<"缺 end!"<<endl;
kk=1;
} */
}
else
{
cout << "Error!" << endl;
kk = 1;
}
return(schain);
}
int yucu() { // cout<<" 调用 yucu"<<endl;
int schain = 0;
schain = statement();
while (syn == 26) {
scaner();
schain = statement();
}
return(schain);
}
int statement()
{
//cout<<" 调用 statement"<<endl;
char *eplace, *tt;
eplace = (char *)malloc(12);
tt = (char *)malloc(12);
int schain = 0;
switch (syn) {
case 10:
strcpy(tt, token);
scaner();
// if(syn==18) {
scaner();
strcpy(eplace, expression());
emit(tt, eplace, "", "");
schain = 0;
/* }
else { cout<<"缺少赋值符 !"<<endl;
kk=1;
} */
return (schain);
break;
}
return (schain);
}
char *expression(void) {
char *tp, *ep2, *eplace, *tt;
tp = (char *)malloc(12);
ep2 = (char *)malloc(12);
eplace = (char *)malloc(12);
tt = (char *)malloc(12);
strcpy(eplace, term()); //调用 term 分析产生表达式计算的第一项 eplace
while ((syn == 15) || (syn == 16)) {
if (syn == 15)
strcpy(tt, "+");
else
strcpy(tt, "-");
scaner();
strcpy(ep2, term()); //调用 term 分析产生表达式计算的第二项 ep2
strcpy(tp, newtemp()); // 调用 newtemp 产生临时变量 tp 存储计算结果
emit(tp, eplace, tt, ep2); //生成四元式送入四元式表
strcpy(eplace, tp);
}
return(eplace);
}
char *term(void) {
// cout<<" 调用 term"<<endl;
char *tp, *ep2, *eplace, *tt;
tp = (char *)malloc(12);
ep2 = (char *)malloc(12);
eplace = (char *)malloc(12);
tt = (char *)malloc(12);
strcpy(eplace, factor());
while ((syn == 13) || (syn == 14)) {
if (syn == 13)strcpy(tt, "*");
else strcpy(tt, "/");
scaner(); strcpy(ep2, factor()); // 调用 factor 分析产生表达式计算的第二项 ep2
strcpy(tp, newtemp());
//调用 newtemp产生临时变量 tp 存储计算结果 emit(tp,eplace,tt,ep2); //生成四元式送入四元式表
strcpy(eplace, tp);
}
return(eplace);
}
char *factor(void) {
char *fplace;
fplace = (char *)malloc(12);
strcpy(fplace, "");
if (syn == 10) {
strcpy(fplace, token);
scaner();
}
else if (syn == 11) {
itoa(sum, fplace, 10);
scaner();
}
else if (syn == 27) {
scaner();
fplace = expression(); //调用 expression分析返回表达式的值
if (syn == 28)
scaner();
else {
cout << "缺)错误 !" << endl;
kk = 1;
}
}
else {
cout << "缺(错误 !" << endl;
kk = 1;
}
return(fplace);
}
void main() {
p = 0;
cout << "Please input a string<end with '#':" << endl;
do {
cin.get(ch);
prog[p++] = ch;
} while (ch != '#');
p = 0;
scaner();
lrparser();
}
- 实验结果