Apache Pulsar是一款由雅虎开发的类似于Kafka的企业级消息订阅系统,在2016将其开源,由Apach基金会孵化,现在已经成长为Apache基金会的顶级项目。Pulsar在雅虎内部已经运行了三年,服务于众多的应用,主要有雅虎邮箱、雅虎财务系统、雅虎运动、Flickr、Gemini广告平台以及雅虎分布式键值对存储系统Sherpa等。
Pulsar相关概念。
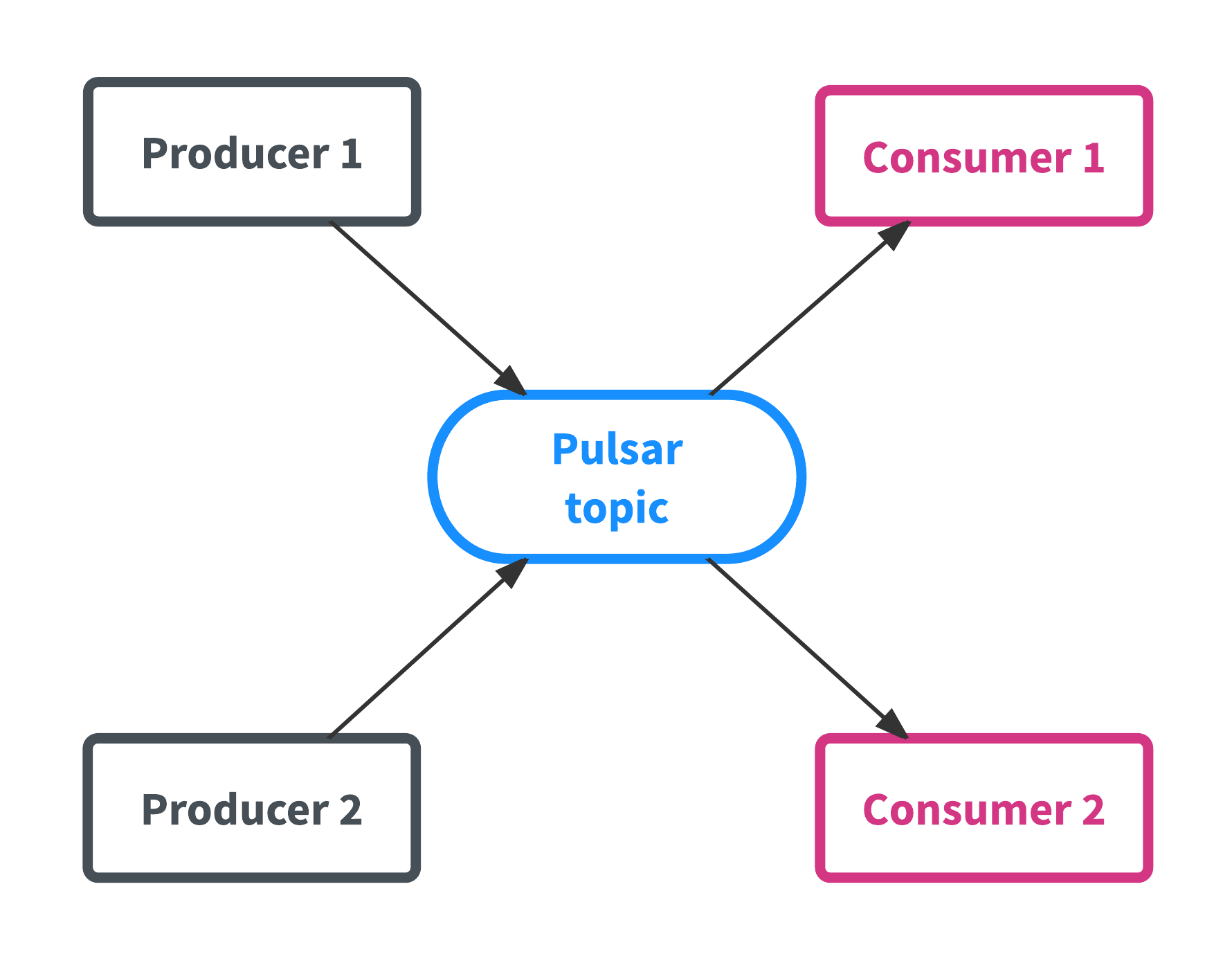
为Pulsar提供数据的应用叫做生产者,而从Pulsar消费数据的应用被称为消费者,有时也称为订阅者。主题Topic是Pulsar的核心资源,这个和Kafka有点类似。主题Topic就像一个管道,生产者往里面写数据,而消费者消费里面的数据。这是Pulsar的特性1,如下图所示:
Pulsar一开始创建时就支持多租户的使用场景。为了支持多租用的功能,Pulsar包含两种资源,分别是“properties”和“namespaces”。property(资产)代表系统中的租户。举个例子,假设部署一个Pulsar集群支持各种各样的应用(就像Pulsar在雅虎公司一样),在Pulsar集群中,每一个资产代表企业中的一个团队,一个核心功能或者一条产品线。每个属性依次包含若干个namespace,例如一个namespace对应每个应用或者使用场景。一个namespace可以包含任意多个主题topic。总的来说,一个Pulsar集群包含多个资产property,一个资产property包含多个namespace,一个namespace包含多个主题topic。Pulsar集群、Property资产、Namespace和主题topic的关系图如下图所示:
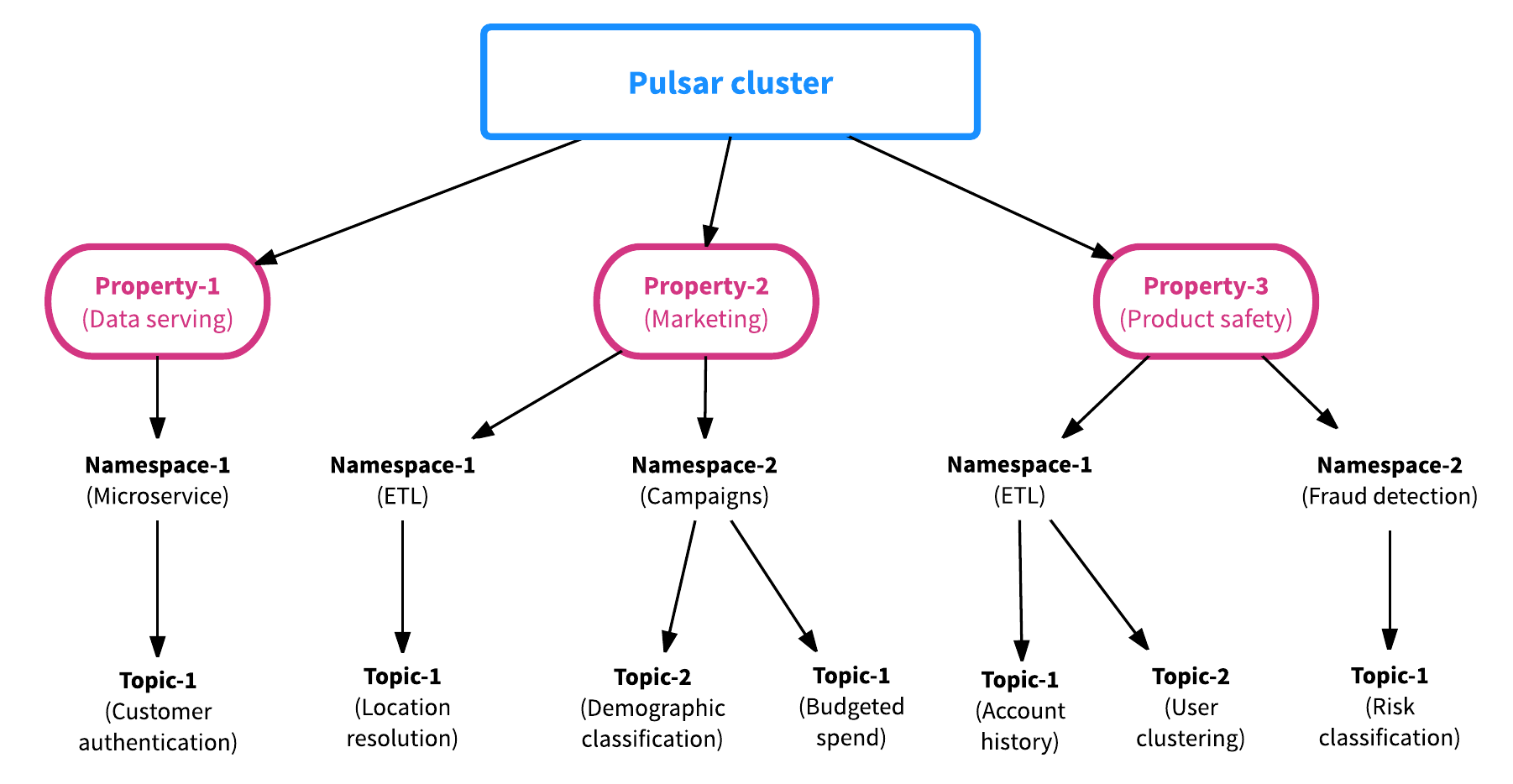
namespace是Pulsar中最基本的管理单元,在namespace这一层面,可以设置权限,调整副本设置,管理跨集群的消息复制,控制消息策略和执行关键操作。一个主题topic可以继承其所对应的namespace的属性,因此我们只需对namespace的属性进行设置,就可以一次性设置该namespace中所有主题topic的属性。
namespace有两种,分别是本地的namespace和全局的namespace:
- 本地namespace——仅对定义它的集群可见。
- 全局namespace——跨集群可见,可以是同一个数据中心的集群,也可以是跨地域中心的集群,这依赖于是否在namespace中设置了跨集群拷贝数据的功能。
虽然本地namespace和全局namespace的作用域不同,但是只要对他们进行适当的设置,都可以跨团队和跨组织共享。一旦生产者获得了namespace的写入权限,那么它就可以往namespace中的所有topic主题写入数据,如果某个主题不存在,则在生产者第一次写入数据时动态创建。
之前提到过,每个namespace会一个或多个主题topic,每个主题会被多个消费者订阅,每个订阅者会从其所订阅的主题topic发布的所有消息中检索和接收数据。为了给每个应用增加更多的灵活性,Pulsar支持三种不同的类型的订阅,并且它们可以在同一个主题topic中共存:
- 独享型订阅(Exclusive subscription)——这种类型的订阅在任何时候都只能有一个消费者。
- 共享型订阅(Share subscription)——多个消费者消费同一个主题topic的数据,每个消费者会接收到一小部分数据。
- 失效型订阅(Failover subscription)——多个消费者连接到一个主题topic,但是只有一个消费者能接收数据,其他消费者只有在当前消费者失效之后才会开始接收数据。
Pulsar提供三种不同类型的订阅subscriptions。subscription提供一个最重要的功能就是解耦消息的生产和消费。通过支持不同类型的subscription,无需增加开发的复杂度就可以增强应用的弹性。下图展现了三种不同类型的订阅:

数据分区
topic主题中的数据有时会很小,小到几KB,有时会很大,大道几十TB。这意这意味着主题topic需要具备在某些情况下保持稳定的低吞吐量,在另一些情况下保持非常高的吞吐量的能力,这取决于使用者的数量。因此,当一个主题需要高吞吐率而例外一个主题需要低吞吐率时,会发生什么呢?为了解决该问题Pulsar允许你当将一个主题topic中的数据分成不同的区域然后存储在不同的机器中。这就是Pulsar的分区功能。
对于处理跨多个节点的大量数据,使用分区是一个非常普通的做法,同时还可以实现高吞吐率。默认情况下,创建的主题topic是没有分区的,但是创建有分区的主题topic也很容易,使用简单的CLI命令或者通过调用API,并且指定分区数量即可。
当你创建有分区的主题时,Pulsar自动将数据分区,确保消费者和生产者与分区无关。对一个还没分区但是已经写入数据的主题进行分区之后,无需对原来的代码进行修改,即可继续将数据写入该主题topic。也就是说分区和应用无关
Pulsar使用一个叫做broker的进程来处理主题的分区,Pulsar集群中的每个节点都运行一个自己的broker进程,下图显示了broker节点如何如果处理分区的细节。
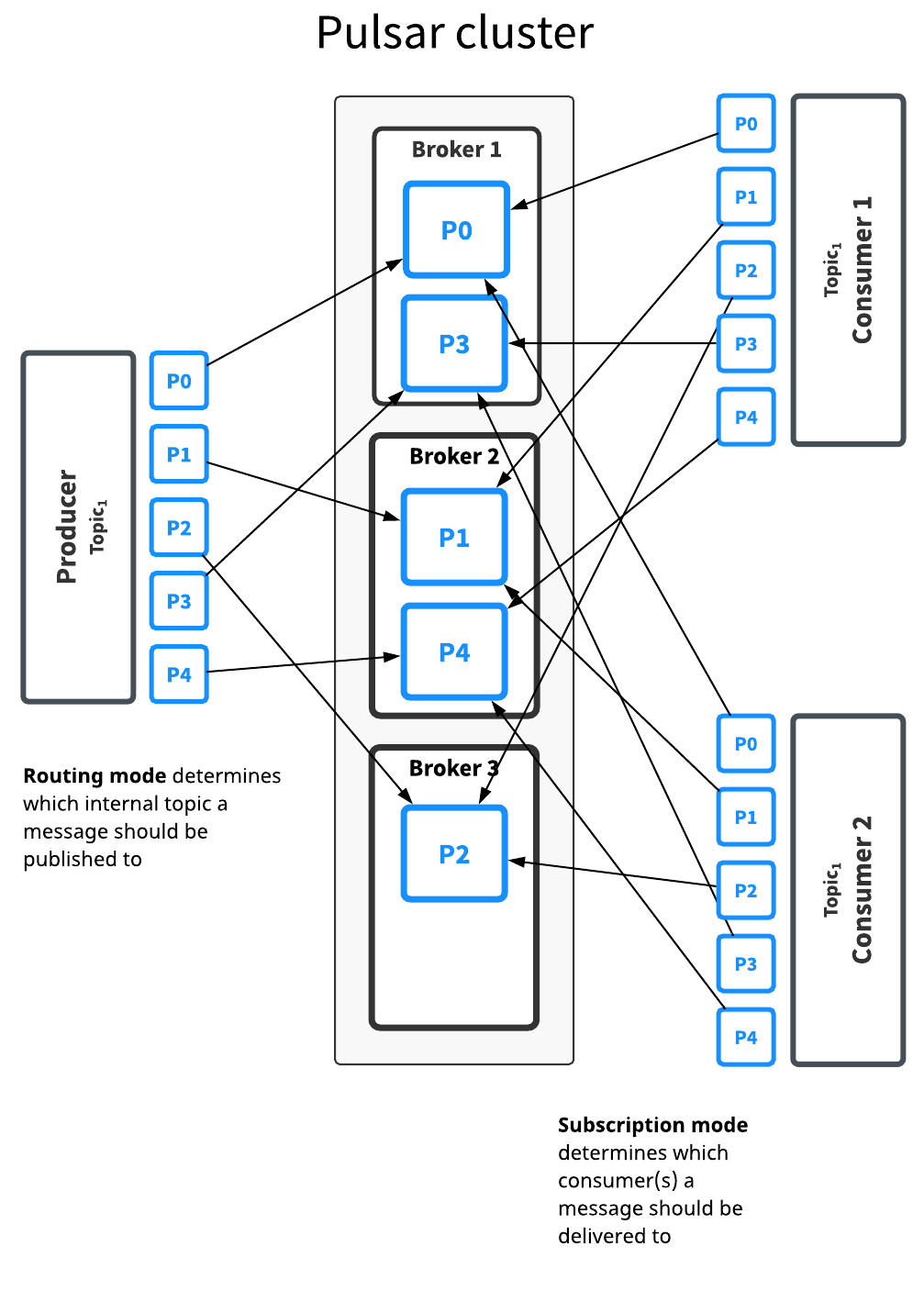
应用程序无需修改代码即可使用分区的优点,Pulsar还额外提供了一些hooks让数据在不同分区和不同消费者之间的分布能达到最佳的效果。Pulsar提供四种不同的路由策略,根据你选择的路由策略决定数据是如何路由到指定的分区。四种分区策略如下:
- Single partitioning(单一分区):生产者随机获取一个分区,并将数据写入到该分区。该模式和无分区主题提供一样的保证,但是对多个生产者写入数据到主题topic的场景非常有用。
- Round robin partitioning(轮询调度分区):在该应用场景,生产者将数据均匀的分布到所有的分区,第一条消息写入到第一个分区,第二条消息写入到第二个分区,以此类推。
- Hash partitioning(哈希分区):在该应用场景下是如何选择分区接入数据的呢?每条消息都有一个key,然后对key调用哈希函数生成一个哈希值,根据该值来选择消息要写入的分区。哈希分区保证消息的按照key的顺序分布。
- Custom partitioning(自定义分区):生产者使用自定义的函数接收消息并生成分区号,下次直接写入对应的分区中,自定义分区模式保证应用程序完全控制分区逻辑。
数据持久性
一旦Pulsar broker接收并确认数据是来自生成者写入到主题topic中的,它需要保证数据在任何情况下都不丢失,不像其他的消息管理系统,Pulsar使用Apache BookKeeper提供的低延迟持久化存储特性保证数据的持久性。一旦Pulsar接收到数据,它会数据发送到多个BookKeeper节点,接收到数据的BookKeeper节点会数据写入到内存和预写日志(write-ahead log)中。在对数据确认之前会强制将日志写入到持久化存储设备中。通过将数据写入到存储设备中,即使出现断电的情况,数据也不会丢失。只有当数据写入到大多数的BookKeeper节点中,Pulsar才会发送确认消息给生产者。
零数据丢失和满足性能要求是消息管理系统的最基本的两个功能,这两个功能在雅虎公司内部已经得到了验证,自从2015年正式在生产环境中使用以来,Pulsar服务了雅虎公司多个重要的系统,例如雅虎财经、雅虎运动、雅虎邮箱、Gemini广告平台以及雅虎分布式存储服务平台Sherpa,目前Pulsar已经在雅虎公司大规模的使用:
- 部署在全球10大数据中心,具有全网复制能力。
- 每天处理超过100亿的数据发布。
- 服务超过140万个主题。
- 发布延迟时间的平均值低于5毫秒。
本文只是简单介绍了Pulsar一些简单的特性,以后将会写一些文章介绍如何搭建Pulsar集群及其用法。
关注本人的公众号获取更多关于大数据和机器学习方面的知识
