一、背景
熟悉MySQL数据库的朋友们都知道,查询数据常见模式有三种:
1. select ... :快照读,不加锁
2. select ... in share mode:当前读,加读锁
3. select ... for update:当前读,加写锁
从技术层面理解三种方式的应用场景其实并不困难,下面我们先快速复习一下这三种读取模式的在技术层面上的区别。
注:为了简化问题的描述,下面所有结论均是针对MySQL数据库InnoDB储存引擎RR隔离级别的。
1.1 select ...
读取当前事务开始时结果集的快照版本,快照版本也可以理解为历史版本。
因为只需读取一个历史版本,而历史不会被修改,故历史版本本身就是一个不可变版本,所以本读取模式对读取前后的资源处理相对简单:
1. 读取行为发生之前,如果有其他尚未提交的事务已经修改了结果集,本读取模式不会等待这些事务结束,自然也读取不到这些修改。
2. 读取行为发生之后,当前事务提交之前,本读取模式也不会阻止其他事务修改数据,产生更新版本的结果集。
1.2 select ... in share mode
读取结果集的最新版本,同时防止其他事务产生更新的数据版本。
由于数据的最新版本是不断变化的,所以本读取模式需要强制阻断最新版本的变化,保证自己读取到的是所有人都一致认可的名副其实的最新版本。
本读取模式在读取前后对资源处理如下:
1. 读取行为发生之前,获取读锁。这意味着如果有其他尚未提交的事务已经修改了结果集,本读取模式会等待这些事务结束,以确保自己稍后可以读取到这些事务对结果集的修改,同时等待期间会阻塞其他事务对结果集的修改。
2. 读取行为发生之后,当前事务提交之前,本读取模式会持续阻塞其他事务对结果集的修改。
3. 当前事务提交后,释放读锁。这意味着所有之前被阻塞的事务可恢复继续执行。
1.3 select ... for update
本读取模式拥有select ... in share mode的一切功能,同时它还额外具备阻止其他事务读取最新版本的能力。
本读取模式在读取前后对资源的处理如下:
1. 读取行为发生之前,获取写锁。这意味着如果有其他尚未提交的事务已经修改了结果集,本读取模式会等待这些事务结束,以确保自己稍后可以读取到这些事务对结果集的修改,同时等待其他会组织其他事务对结果集最新版本的读取和修改。
2. 读取行为发生之后,当前事务提交之前,本读取模式会持续阻塞其他事务对结果集的修改,也会阻塞其他事务对结果集最新版本的读取。
3. 当前事务提交后,释放写锁。这意味着所有之前被阻塞的事务可恢复继续执行。
三种读取模式在技术层面的区别到此就复习完了,可是我们在实际业务编程过程中,读取数据库中的记录到底什么时候要加读锁,什么时候要加写锁呢?
读取快照版本的历史数据和读取最新版本的数据映射到业务层面是怎样的一种业务逻辑需求?难道每写一处数据库查询代码,都要从技术层面去细细思考不同读取模式其读取行为发生之前、之后对资源的处理是否符合业务需求吗?这样编程也太辛苦啦。
带着上述疑问,本文将尝试从每种读取模式的技术性功能出发,将不同模式下的技术功能差异转换为业务需求差异,从而总结出不同功能的应用场景,最终产出少数的操作性强的场景判定规则,用于快速回答不同业务场景下查询数据库是否应该加读锁或写锁这一问题。
不过在讨论数据库加锁的应用场景之前,我们先弄清楚一个问题,应用层可以加锁,数据库也可以加锁,他们之间的功能似乎有一点重叠,那么什么情况下需要使用数据库锁而不是应用层锁呢?
二、应用层加锁 vs 数据库加锁
应用层加锁,指的是在同一个进程内,通过同步代码块(临界区)、信号量、Lock锁对象等编程组件,实现并发资源的有序访问。
理论上来说,数据库加锁需要解决的问题,通过应用层锁都能解决。
但是应用层加锁最大的局限在于其作用范围是单进程内。在分布式集群系统盛行的今天,绝大部分模块都有可能会启动多个进程实例,以实现负载均衡功能。如果两个进程并发访问数据库,通过进程内的应用层锁,是无法将跨进程的多个处理流程协调成有序执行的。
同时我们也应该认识到,数据库锁是稀缺资源,因为储存着状态的数据库难以横向扩展,几乎是整个系统的最终瓶颈。而无状态的计算处理模块可以轻松的弹性伸缩,一个性能不够启动两个,两个不够启动三个。。。
所以,我们可以得出如下结论:
结论1:只会在单进程内形成的资源争用,进程内部应优先使用应用层锁自己解决,而不应该将其转嫁给数据库锁(虽然很多时候用巧妙地使用数据库锁可能编程更加方便)。数据库锁应主要用于解决多进程间并发处理数据库中的数据时可能形成的混乱。
下面我们讨论的数据库加锁应用场景,其间提及的多个事务,均是指的这些事务在不同进程中开启的情况。
三、技术功能差异到业务需求差异的转换
2.1 select ... for update vs select ... in share mode
select ... for update相对于select ... in share mode而言,对读取到的结果集的最新版本具有更强的独占性。select ... in share mode只是阻塞其他事务对结果集产生更新版本,而select .. for update还会阻塞其他事务对结果集最新版本的读取。
业务层面在什么情况下需要阻塞其他事务对结果集最新版本的读取呢?
不想让别人也可以读取到最新版本,往往是因为自己想在最新版本上进行修改,同时担心其他人也和自己一样。因为大家在修改数据时,总是希望自己的修改与数据的最新版本(而不是历史版本)合并后存入数据库中,所以大家在修改数据前,都会尝试获取数据的最新版本,基于最新版本进行修改。如果每个人都可以同时获取到数据的最新版本并在最新版本上加入自己的修改,最后大家一起提交数据,必然会出现一个人的修改覆盖了其他人修改的情况,这就是经典的“更新丢失”问题。如下图所示:

其实这个问题还可以反过来问,什么情况下不必阻塞其他事务对结果集的读取呢?
试想如果无论你阻不阻塞读取,其他事务读取到的结果集都是一样的,你又何必阻塞它呢?如果你不修改读取出的结果集,那么别人早读晚读又有什么区别?
通过上面的思考,我们可以得出如下结论:
结论2:如果读取出的数据自己不需要修改它,是肯定不需要使用select ... for update的。
结论3:如果读取出的数据自己需要修改它,“更新丢失”问题在绝大部分业务场景中都是应该避免的,所以此时需要使用select ... for update。
2.2 select ... in share mode vs select ...
select ... in share mode相对于select ... 而言,主要新增了两点约束:
1. 读取数据之前,等待修改了这些数据的事务提交。
2. 读取数据之后,防止其他事务修改这些数据。
我们先用业务层面的语言将上述两点约束合并简述为:希望读取到所有人都一致认可的最新版本的数据(即没有其他人还正在修改这些数据)并锁定它。
那么什么样的业务场景下,我们需要达到这样的效果呢?
我能想到的有如下两个典型的场景:
例1. 基于更新时间戳增量处理数据
我此次读取并处理了时间点A之前的数据,下次就不会再读取并处理这个范围内的数据了,这就是增量处理的要求。如果我读取之前有人已经修改这个范围内的数据,只是事务尚未提交(由于修改行为发生在时间点A之前,所以这些数据的更新时间戳也在时间点A之前),我读取之后这些修改提交了。
若我采用的是普通的select ... 意味着虽然我读取并处理了时间点A之前的数据,但是在我读取之后这个范围内又出现了新的数据。这就会漏掉部分尚未处理的数据。如下图所示:
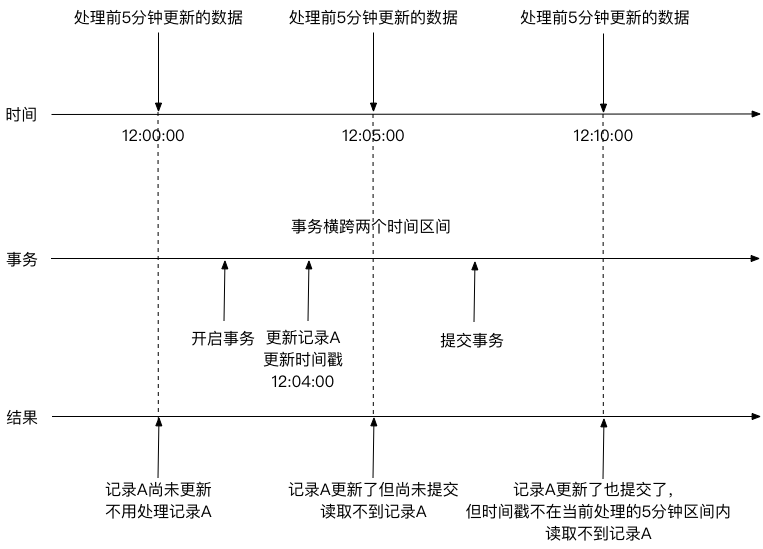
如果我采用的是select ... in share mode,则会等待待查询时间范围内的修改均提交后,再处理这个范围内的数据,就可以避免漏处理问题。
本例中出现的问题隐含了一个前提条件,那就是新的数据提交时,新增数据的一方并没有主动通知我进行处理,而是由我去基于时间戳扫描新增数据。相当于业务逻辑的完整性由我单方面保证,而另外一方并不愿意为此事效劳。事实上基于更新时间戳增量处理数据的场景中,通常处理程序是第三方,基于时间戳扫描增量数据只是为了尽量保证原数据表上应用系统无需修改,即减少侵入性。
(注:基于更新时间戳处理新增数据时,设置安全读取时延是更加常用的解决方式。即每次读取的时间点设置为当前时间X分钟前,X分钟大于系统中事物持续的最大时间,以保证抽取时间点之前的所有修改都已提交。但是这种方式会降低数据处理的实时性。)
那么,假设修改数据的每一方都愿意通力配合,竭尽全力地保证数据的一致性和业务逻辑的完整性时,就不会出问题了么?请看下面这个例子。
例2. 更新关联关系
比如,比如有Books和Students两张表,一张BooksToStudents的多对多关联表。新增Book需要让每个Studuent都有这个Book。新增Student需要让所有Book都属于该Student。无论何时,对数据一致性的要求是:所有Student都拥有所有的Book。
如果两个人A和B,同时开启事务,一人新增BookA,一人新增StuduentB,大家各自严格按照数据一致性要求去维护BooksToStudents关联表。
如果不使用select ... in share mode而是使用select ... ,由于每个事务都无法读取到对方的尚未提交的新增实体,A不知道有StudentB,所以A的BookA不会属于StudentB;B不知道有BookA,所以B的StudentB下不会有BookA。最终两个事务提交后,结果就是StudentB没有拥有BookA。如下图所示:
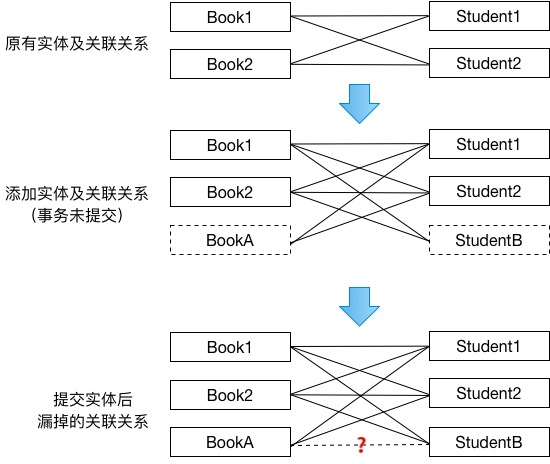
A和B都有机会建立起StudentB下拥有BookA这一关联记录,但是这份关联记录的建立只在A添加BookA时,以及B添加StudentB时处理,如果这两个时刻均读取不到需要的记录,这份关联记录的建立将永远不会再被触发。
但是,如果使用select ... in share mode,当A读取Students表时,发现没有StudentB后,B也无法再往Students表中添加StudentB,直至A的事务提交。届时,B再读取Books表时,也能发现A提交的BookA,进而正确新增StudentB下拥有BookA这一关联记录。
本例虽以多对多关联关系为例,其实在一对多、多对一关联关系中也可能存在类似问题。原理都大同小异,只不过一对多、多对一的关联关系通常直接储存在关联实体的某一列中,而不是储存在独立的关联关系表中。
例1呈现出来的场景可以总结为:
结论4:当数据一致性和业务逻辑完整性只能由自己单方面保证时,且自己利用了数据的某种单调性增量处理数据时,需使用select ... in share mode查询更新数据。
例2呈现出来的场景可以总结为:
结论5:当有关联关系的两个实体可能同时新增时,一方因新增实体修改关联关系,需使用select ... in share mode查询另一方数据进行关联关系的更新。
2.3 select ... 快照读有那么危险吗?
看了上面的介绍,大家可能恨不得所有查询都使用最严格的select ... for update,这样至少不会错。但是作为最常见的普通select语句,真的有那么危险吗?
快照读意味着读取历史数据,其实把时间放长远了看,基本上绝大部分数据后续都有更新的可能。所以即便是使用最严格的select ... for update读取模式,读到的数据也终究抵不过时间的流逝,沦为历史数据。用户更多关注的并不是某份数据有多新,而是某份数据不要太过时,快照读读取的历史数据通常也就是最近几十毫秒到几秒前的历史版本,完全能够满足用户的查看需求。
当读取数据是为了后台严格的逻辑控制判定时,我们会担心读取过程中出现的更新版本的数据会错过本次事务中的处理逻辑,但是这个担心一般来说也是多余的,因为别人产生新版本的数据时,必然也会触发一系列的处理来保证数据的一致性和业务逻辑的完整性,不必在自己的事务中过于操心别人的事情。
四、总结
我们的原则通常是,优先使用锁范围小的查询模式,以尽量提升数据库的并发性能。即先选select ... ,不行再用select ... in share mode,再不行再提升为select ... for update。而结论2告诉我们何时无需用select ... for update,在此原则下,我们需要搞清楚的是何时需要用select ... for update,所以这个结论可以忽略。
我们的日常开发中,大部分情况下不需要自己单方面保证数据的一致性和业务逻辑的完整性,所有数据的修改方都可以通力合作。所以结论4可以暂时忽略。
综上,日常开发过程中,我们需记住:
1. 只会在单进程内形成的资源争用,进程内部应优先使用应用层锁自己解决,而不应该将其转嫁给数据库锁。数据库锁应主要用于解决多进程间并发处理数据库中的数据时可能形成的混乱。
2. 优先使用select ...
3. 当有关联关系的两个实体可能同时新增时,一方因新增实体修改关联关系,需使用select ... in share mode查询另一方数据进行关联关系的更新。
4. 如果读取出来的数据需要修改后再提交,需使用select ... for update读取数据。
如果你不幸需要与第三方系统(或难以修改的遗留系统)以数据库的方式进行集成时,需再多记住一点:
5. 当数据一致性和业务逻辑完整性只能由自己单方面保证时,且自己利用了数据的某种单调性增量处理数据时,需使用select ... in share mode查询更新数据。