MySQL 数据库客户端成功建立与服务端的连接和并完成用户认证后,就可以发送 SQL 语句与服务端交互了:
接下来,我们一起来探究当客户端发送一个 SQL 查询语句后,服务端都做了哪些操作,将最终结果返回给客户端。
服务端整体架构
开始之前,我们先来看看 MySQL 服务端的整体架构:
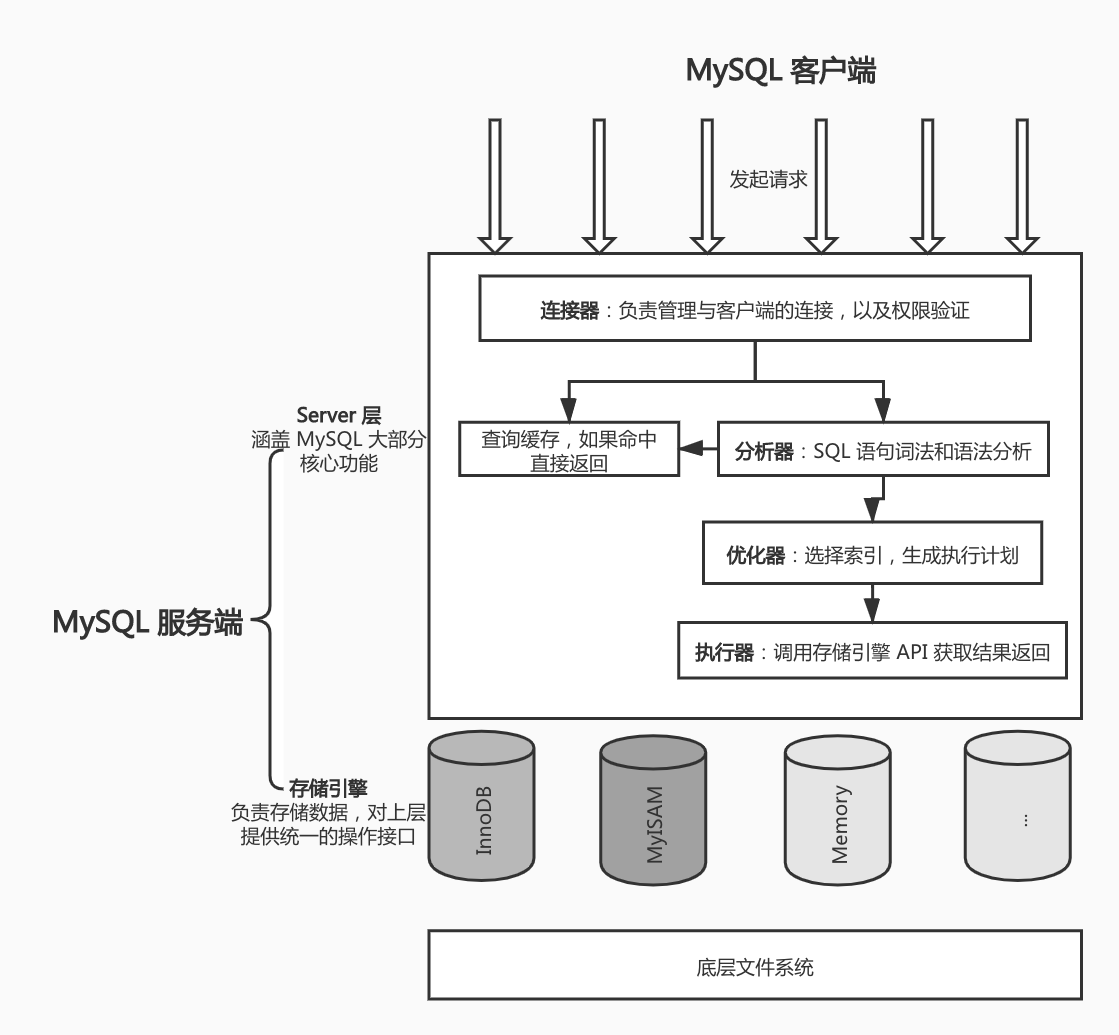
可以看到服务端主要由 Server 层和存储引擎两部分组成:
- Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
- 存储引擎层负责数据的存储和提取,其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。我们后续教程也主要基于 InnoDB 进行讲解。
对 MySQL 服务端架构有了整体了解后,接下来,我们来依次探究一条 SQL 查询语句到达服务端后,在每个组件中都经历了什么。
由于现在客户端已经建立了与服务端的连接,所以连机器这一步就可以跳过了,我们接着往下看。
查询缓存
当 MySQL 服务端拿到一条 SQL 查询语句后,首先会查询缓存,看之前是不是执行过这条语句。如果执行过,会缓存在内存中,这个时候直接返回之前缓存的查询结果给客户端即可;如果在缓存中没有找到对应的记录,就会继续后面的操作,并且在最终执行完成后,将查询结果保存到查询缓存。
可以看到,如果命中查询缓存,MySQL 不需要执行后面的复杂操作就可以直接返回结果,查询效率会很高。但是通常不建议这么做,原因和是否要在业务逻辑中保存模型类查询结果一样:因为这个缓存的 key 是查询语句,只要有一点不同(实际项目中查询字段、查询条件千姿百态)就会导致缓存命中失败,同时,数据表记录本身也是不断更新(插入、更新、删除)的,更新之后,之前的查询缓存就全部失效了,所以从维护成本和实际收益上看,得不偿失。除非这张表创建初始化后不怎么更新,是一个静态表,并且查询语句相对单一。
注:MySQL 8.0 版本开始将不再支持查询缓存功能。
你可以通过 show variables like '%query_cache%'; 语句查看系统查询缓存设置:
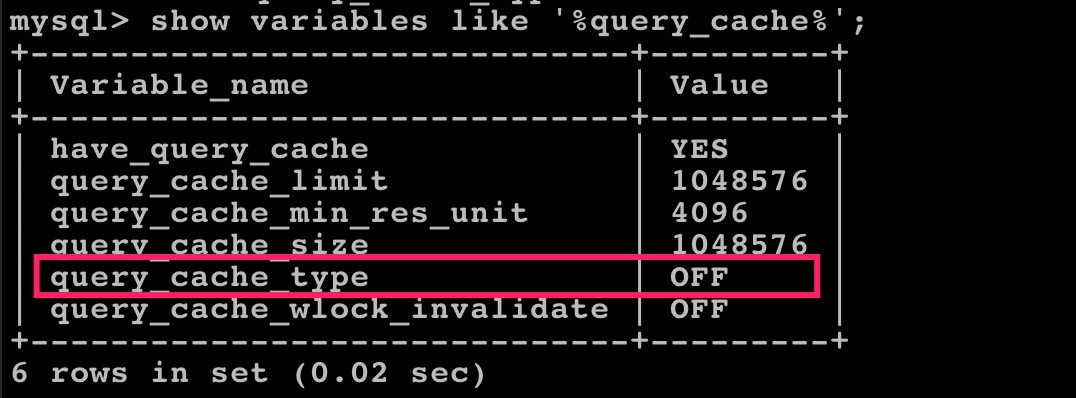
query_cache_type 为 OFF 表示默认关闭。你可以在配置文件中配置该值来决定是否启用查询缓存。
分析器
如果查询缓存没有启用或者没有命中,就开始真正执行 SQL 查询语句了。
MySQL 会通过分析器对 SQL 语句做词法分析,以确定到底要做什么,比如 select 表示查询语句,update 表示更新语句等,表名是什么,查询的字段有哪些,查询的条件是什么。
确定要做的事情之后,分析器还会对 SQL 语句进行语法分析,以确保符合 MySQL 语法,你可能对 You have an error in your SQL syntax 这个报错很熟悉,这就是 SQL 语句语法错误的提示(重点关注「use near」后面的错误原因):

优化器
如果 SQL 语句词法和语法分析都没有问题,接下来,会经由优化器生成执行计划,这里面主要的工作是数据表包含索引的时候,判定是否使用索引,以及使用哪些索引效率最高(扫描行数最少),我们可以在执行一个 SQL 查询语句之前通过 explain 语句查看它的执行计划:

注:关于返回结果字段的解释我们在后面会专门介绍,这里先了解即可。
执行器
通过分析器可以知道客户端发送的 SQL 语句要做什么,通过优化器可以确定要怎么做,最后就是真正去执行了,这一步通过服务端的执行器完成。
在根据执行计划执行 SQL 查询语句时,会先验证权限,有相应的权限才会继续执行,否则会报权限错误。
在具体执行查询操作时,是通过调用存储引擎提供的 API 接口完成的,MySQL 支持不同的存储引擎,虽然这些存储引擎存取数据的底层实现不尽相同,但是对 Server 层提供了统一的接口,执行器调用这些接口可以完成诸如读取下一行记录、插入记录、更新记录之类的日常数据库操作,执行 SQL 查询返回所有满足条件的结果集也是如此。
在存储引擎中进行查询操作时,如果 SQL 语句没有使用索引,则需要一条条遍历数据表的所有记录(全表扫描),然后将满足条件的记录存放到结果集,直到数据表最后一行,最后再把这个结果集返回给客户端。如果数据表非常大,表记录非常多时,这种查询的效率会很低下,这是我们在优化数据库查询效率时所要极力避免的现象。
反之,如果 SQL 查询语句中使用了索引,则可以极大提升查询效率,至于底层的原因,我们后面介绍存储引擎底层实现和索引时,会专门进行介绍。