无索引的表就是无顺序的行集。比如下面的数据:
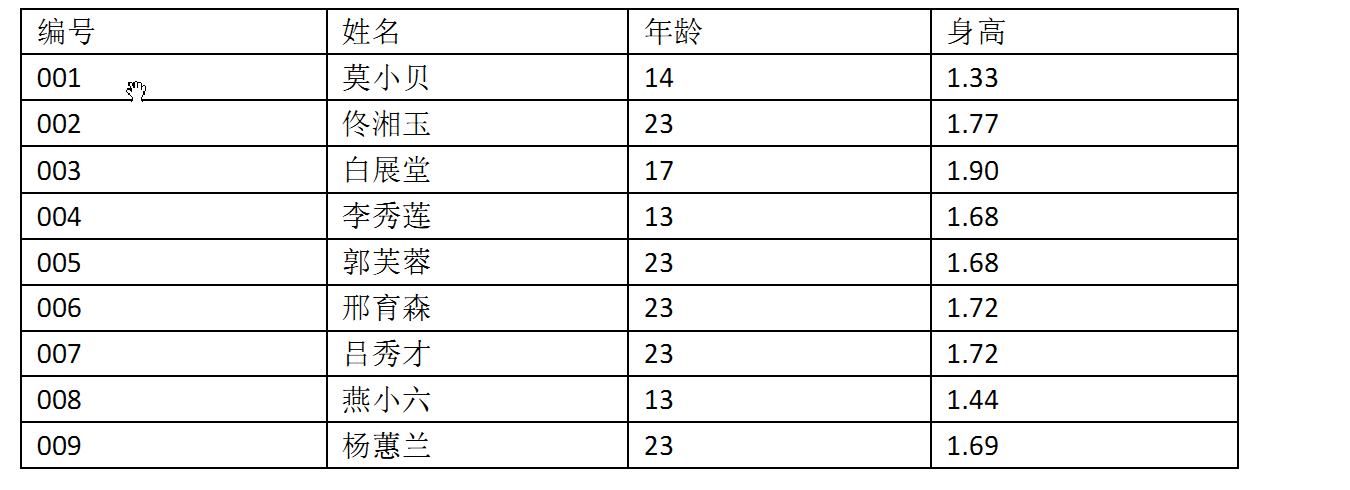
上面没有索引,当我查询17岁的人员时,必须查看表中的每一行,看是否与所需的值匹配。是一个全表扫描,如果只有几个记录与之吻合,效率是非常低的。
如果我们为年龄列建一个索引,注意这里的索引采用的值是排序的
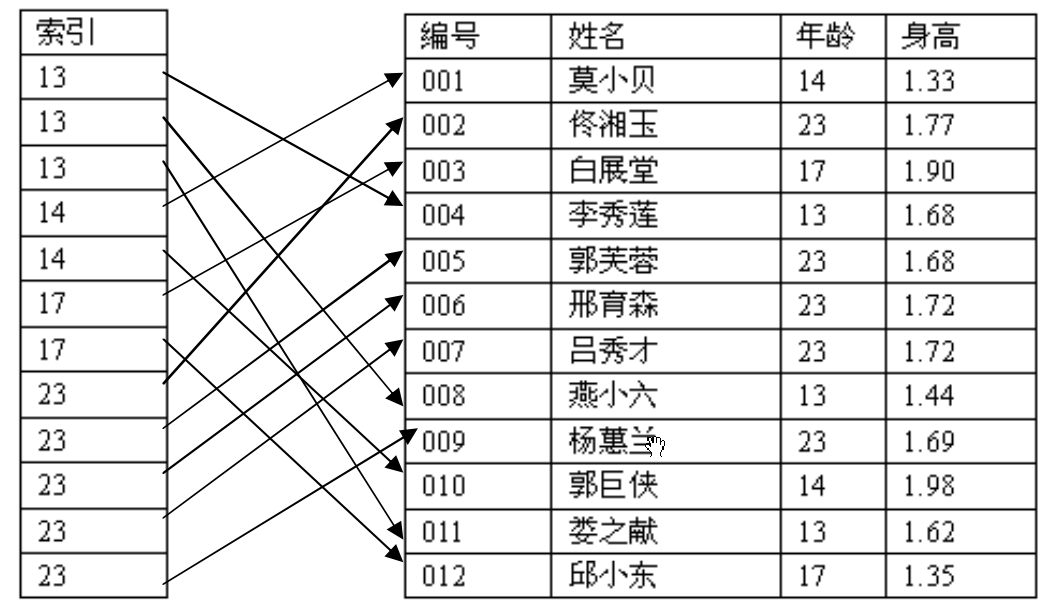
假如要查找年龄为13岁的成员,则可以扫描索引,得出结果是前3行。索引值是排序的,因此到了14的时候就知道下面没有匹配的记录,可以退出了。如果查找某个值,它在索引表中某个中间位置以前不会出现,那么也有找到第一个匹配索引的定位算法,而不用进行表的顺序扫描(如二分法)。这样可以快速定位到第一个匹配的值,以节省大量搜索时间。
可以把索引想象成汉语词典中按笔画查找的目录。汉语词典中汉子是按照拼音次序排列在书页中的,如果要查询笔画数为18的汉子,就必须挨个查找给个汉子来比较每个汉子的笔画数,如果我们创建一个按照笔画数查找的目录,那么查找起来就非常快速了。
虽然索引可以提高数据查询的速度,但是任何事情都是一把双刃剑,它也有一些缺点:
1、索引要占据一定的磁盘空间
2、索引减慢了数据更改的速度,因为每一次更改都需要更新索引,一个表拥有的索引越多,则写操作的平均性能下降就越大。
文章来自书籍:《程序员的SQL金典》