说明:用户画像的概念以及意义不在此赘述,这里只探讨如何快速搭建基础架构以及后续工作的注意事项。
用户画像的提出是基于日益发展的业务需要,在相对充分的数据储备之上的进一步理解和提炼数据过程中提出的概念。通过人群的不同画像来做到个性化推荐。
用户画像一般是分为两类的。
一类是实时用户画像,这类画像的处理逻辑一般都很简单,要求迅速响应,实时处理。数据从kafaka过来,通过storm 等实时开源框架处理之后存入redis 当中。这里暂不讨论。
第二类便是离线用户画像,这类用户画像是把当天业务方需要的用户画像提前算好,然后供给业务方使用。由于对数据的时效性要求不是那么的高,可以使用较复杂的处理逻辑或者各种离线机器学习模型来保证画像的准确性。数据一般存在HDFS 和 Hbase 里面。
具体结构如下图:
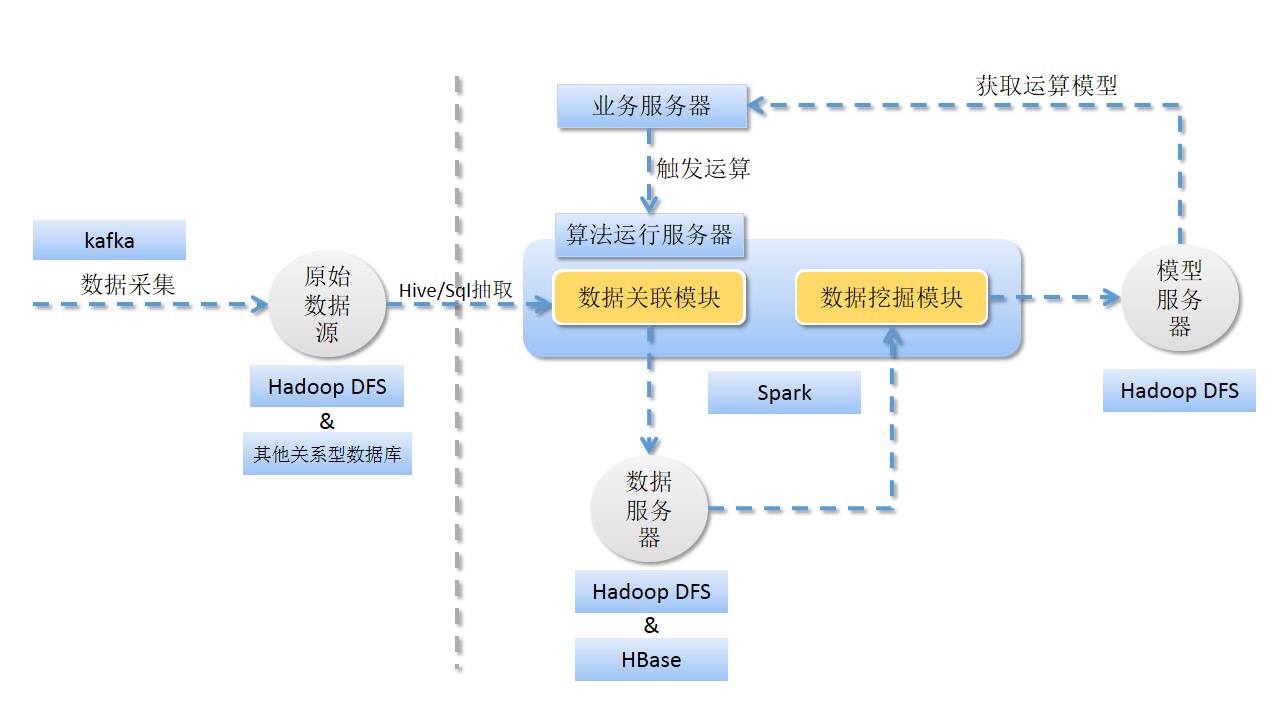
离线的用户画像的数据来源一般是来自采集或者数据仓库,按照数据源的存在形式不同,可用不同方式HiveSql抽取。这里的数据仓库是指通过前端页面埋点,用户访问采集到的流量日志。在获取到需要的数据以后,首先经过用户连线将同一个用户的行为全部连线到一起,然后利用 mapreduce 按照一定的处理逻辑进行处理。然后储存到数据库中(HBase或其他关系型数据库)。
对采集的数据进一步挖掘,将数据归纳出标签。算法服务作为整个用户画像的核心,可以按照如下思路构建。
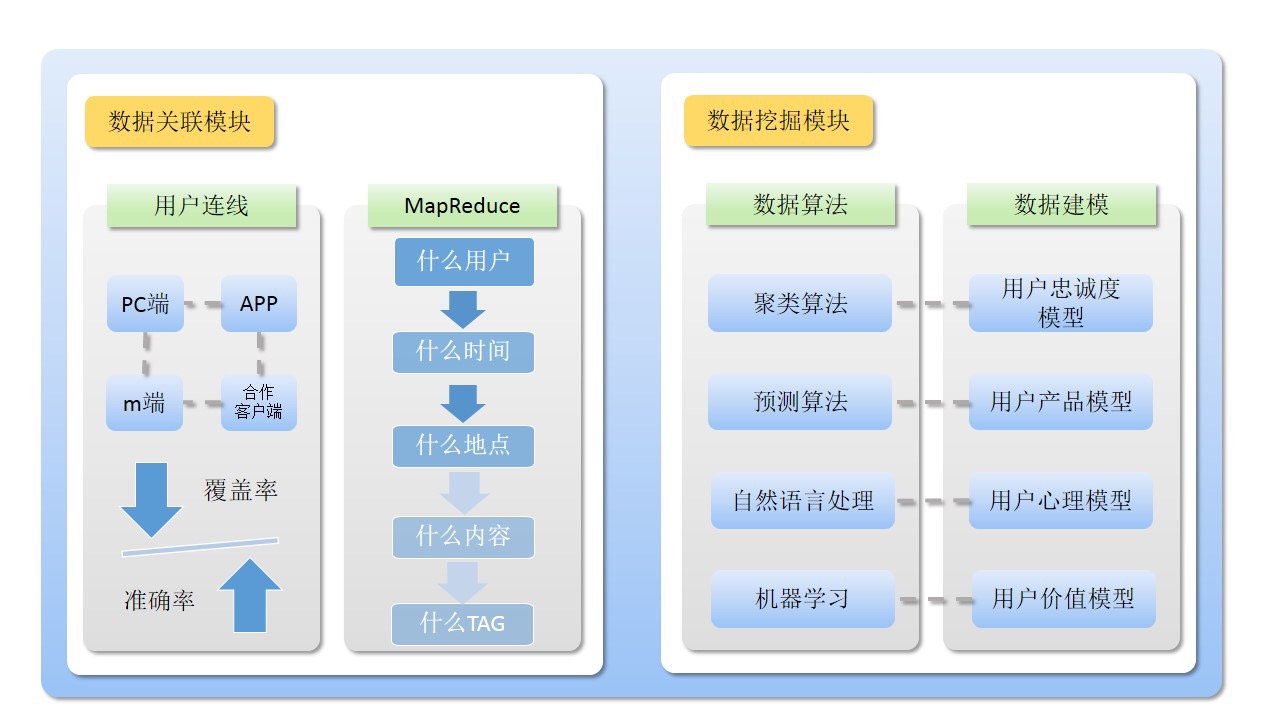
需要注意的是用户画像前期每天重复性的工作很容易让人疲倦,但确实也非常的重要,是整个数据挖掘方向最靠近业务的一个方向。很多时候,深度学习也好,机器学习也罢都离业务太远了,有时候是无法落地给公司带来直接的产出,非常容易就被边缘化。所以就个人理解来说,技术固然是很重要的,但是技术本身是没有产出的,所以我要尽量去想办法让我的技术有产出并且是可以度量的。在选择业务的时候,我更多的也会考虑这是不是个很有前景的业务。这样能够最大限度保证技术有落地,有产出,不至于被边缘化,同时也能一直保持对技术的热情。