第一、服务器的吞吐量问题。
我们都知道,基于IOCP的开发是异步IO的,也正是这一技术的本质,决定了IOCP所实现的服务器的高吞吐量。
我们举一个及其简化的例子,来说明这一问题。在网络服务器的开发过程中,影响其性能吞吐量的,有很多因素,在这里,我们只是把关注点放在两个方面,即:网络IO速度与Disk IO速度。我们假设:在一个千兆的网络环境下,我们的网络传输速度的极限是大概125M/s,而Disk IO的速度是10M/s。在这样的前提下,慢速的Disk 设备会成为我们整个应用的瓶颈。我们假设线程A负责从网络上读取数据,然后将这些数据写入Disk。如果对Disk的写入是同步的,那么线程A在等待写完Disk的过程是不能再从网络上接受数据的,在写入Disk的时间内,我们可以认为这时候Server的吞吐量为0(没有接受新的客户端请求)。对于这样的同步读写Disk,一些的解决方案是通过增加线程数来增加服务器处理的吞吐量,即:当线程A从网络上接受数据后,驱动另外单独的线程来完成读写Disk任务。这样的方案缺点是:需要线程间的合作,需要线程间的切换(这是另一个我们要讨论的问题)。而IOCP的异步IO本质,就是通过操作系统内核的支持,允许线程A以非阻塞的方式向IO子系统投递IO请求,而后马上从网络上读取下一个客户端请求。这样,结果是:在不增加线程数的情况下,IOCP大大增加了服务器的吞吐量。说到这里,听起来感觉很像是DMA。的确,许多软件的实现技术,在本质上,与硬件的实现技术是相通的。另外一个典型的例子是硬件的流水线技术,同样,在软件领域,也有很著名的应用。好像话题扯远了,呵呵:)
第二、线程间的切换问题。
服务器的实现,通过引入IOCP,会大大减少Thread切换带来的额外开销。我们都知道,对于服务器性能的一个重要的评估指标就是:System\Context Switches,即单位时间内线程的切换次数。如果在每秒内,线程的切换次数在千的数量级上,这就意味着你的服务器性能值得商榷。Context Switches/s应该越小越好。说到这里,我们来重新审视一下IOCP。
完成端口的线程并发量可以在创建该完成端口时指定(即NumberOfConcurrentThreads参数)。该并发量限制了与该完成端口相关联的可运行线程的数目(就是前面我在IOCP简介中提到的执行者线程组的最大数目)。当与该完成端口相关联的可运行线程的总数目达到了该并发量,系统就会阻塞任何与该完成端口相关联的后续线程的执行,直到与该完成端口相关联的可运行线程数目下降到小于该并发量为止。最有效的假想是发生在有完成包在队列中等待,而没有等待被满足,因为此时完成端口达到了其并发量的极限。此时,一个正在运行中的线程调用GetQueuedCompletionStatus时,它就会立刻从队列中取走该完成包。这样就不存在着环境的切换,因为该处于运行中的线程就会连续不断地从队列中取走完成包,而其他的线程就不能运行了。
完成端口的线程并发量的建议值就是你系统CPU的数目。在这里,要区分清楚的是,完成端口的线程并发量与你为完成端口创建的工作者线程数是没有任何关系的,工作者线程数的数目,完全取决于你的整个应用的设计(当然这个不宜过大,否则失去了IOCP的本意:))。
第三、IOCP开发过程中的消息乱序问题。
使用IOCP开发的问题在于它的复杂。我们都知道,在使用TCP时,TCP协议本身保证了消息传递的次序性,这大大降低了上层应用的复杂性。但是当使用IOCP时,问题就不再那么简单。如下例:
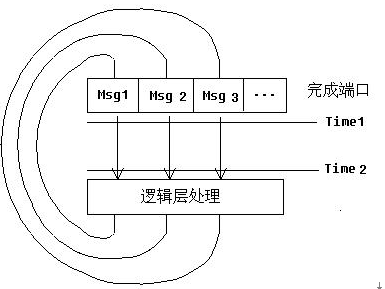 三个线程同时从IOCP中读取Msg1, Msg2,与Msg3。由于TCP本身消息传递的有序性,所以,在IOCP队列内,Msg1-Msg2-Msg3保证了有序性。三个线程分别从IOCP中取出Msg1,Msg2与Msg3,然后三个线程都会将各自取到的消息投递到逻辑层处理。在逻辑处理层的实现,我们不应该假定Msg1-Msg2-Msg3顺序,原因其实很简单,在Time 1~Time 2的时间段内,三个线程被操作系统调度的先后次序是不确定的,所以在到达逻辑处理层,
三个线程同时从IOCP中读取Msg1, Msg2,与Msg3。由于TCP本身消息传递的有序性,所以,在IOCP队列内,Msg1-Msg2-Msg3保证了有序性。三个线程分别从IOCP中取出Msg1,Msg2与Msg3,然后三个线程都会将各自取到的消息投递到逻辑层处理。在逻辑处理层的实现,我们不应该假定Msg1-Msg2-Msg3顺序,原因其实很简单,在Time 1~Time 2的时间段内,三个线程被操作系统调度的先后次序是不确定的,所以在到达逻辑处理层,Msg1,Msg2与Msg3的次序也就是不确定的。所以,逻辑处理层的实现,必须考虑消息乱序的情况,必须考虑多线程环境下的程序实现。
在这里,我把消息乱序的问题单列了出来。其实在IOCP的开发过程中,相比于同步的方式,应该还有其它更多的难题需要解决,这也是与Select方式相比,IOCP的缺点,实现复杂度高。