实验一个Python实例,将一个文本文件转换为HTML文件的例子。看了例子的解法,时刻感受到面向对象,不是一般水平的人能掌握的。
一般面对问题的直接解法,通常不是最通用的解法,该解法只这对这一种情况,难扩展。
比如这个例子,我看到后,想到的直接解法是:取出文件中所有的块,然后依次对每个块进行正则式过滤,添加HTMLtag

等书中讲解第二种解法时,我一时还看不懂,等我看明白了,才知道面向对象的伟大和难以掌握,需要继续修炼。
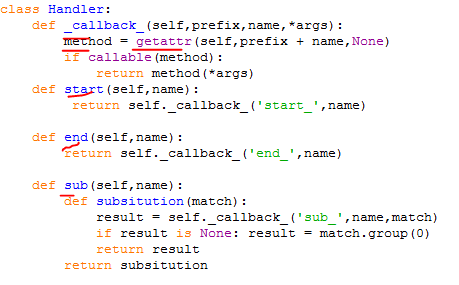
他的解法是,
1. 创建一个解析类,用来对文本的每一块进行处理
2. 如何处理? 有按什么规则添加深Tag的,有替换文本内容应用模式的。所以就有了一个规则类,这个类用来判断该应用什么规则
3. 知道规则了,怎么应用?就提到了处理类,处理类,无法就是添加 开始tag, 结束tag, 替换内容: sub
具体什么tag,什么内容,该用到子类中具体实现。如何调用子类具体实现?可巧的一个解法