原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/12697359.html
准备数据
import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_boston from sklearn.linear_model import LinearRegression from sklearn.model_selection import learning_curve from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures # 准备数据 samples = load_boston() samples # dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename']) samples.keys() # (506, 13) samples['data'].shape # (506,) samples['target'].shape # print(samples['DESCR'])
分割训练集和测试集
# 分割训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(samples['data'], samples['target'], test_size=0.2, random_state=3) # (404, 13) X_train.shape
建模训练
# 建模训练 lr_model = LinearRegression(normalize=True) # LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=True) lr_model.fit(X_train, y_train)
评估模型
# 评估模型 train_score = lr_model.score(X_train, y_train) test_score = lr_model.score(X_test, y_test) # 0.7239410298290111 train_score # 0.7952617563243858 test_score
欠拟合,高偏差,构建多项式特征
def polynomial_model(degree=1): polynomial_features = PolynomialFeatures(degree=degree, include_bias=False, interaction_only=False) linear_regression = LinearRegression(normalize=True) pipeline = Pipeline([('polynomial_features', polynomial_features), ('linear_regression', linear_regression)]) return pipeline p2_model = polynomial_model(2) p2_model.fit(X_train, y_train) train_score = p2_model.score(X_train, y_train) test_score = p2_model.score(X_test, y_test) # 0.9305468799409319 print('score on train set: ', train_score) # 0.8600492818189014 print('score on test set: ', test_score)
绘制学习曲线
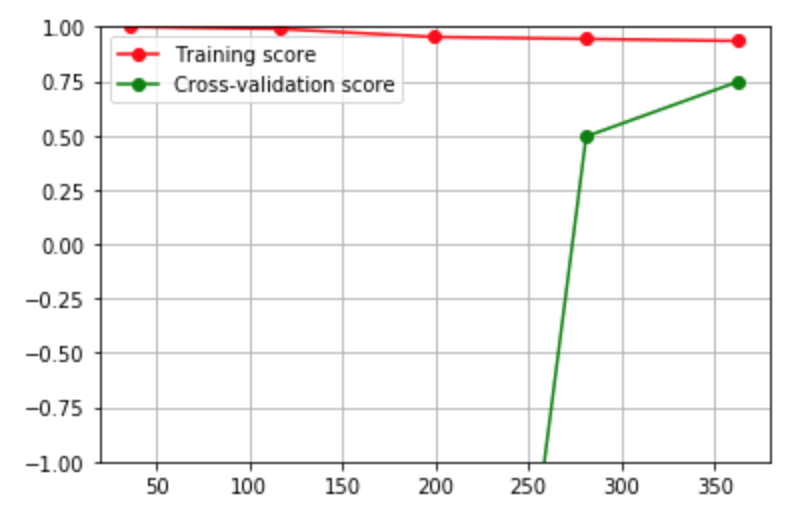
学习曲线是用来判断训练模型的一种方法,通过观察绘制出来的学习曲线图,可以比较直观的了解到模型处于一个什么样的状态,如:过拟合(overfitting)或欠拟合(underfitting)。可以很好的表示,当训练数据集增加时,模型对训练数据集拟合的准确性,以及对交叉验证数据集预测的准确性的变化规律。
# array([0.1 , 0.325, 0.55 , 0.775, 1. ]) train_sizes = np.linspace(0.1, 1.0, 5) train_sizes, train_scores, test_scores = learning_curve(p2_model, X_train, y_train, cv=10, train_sizes=train_sizes) train_scores_mean = np.mean(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) plt.grid() plt.ylim(-1, 1) plt.plot(train_sizes, train_scores_mean, 'ro-', label="Training score") plt.plot(train_sizes, test_scores_mean, 'go-', label="Cross-validation score") plt.legend()
Reference
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.learning_curve.html