原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/12668372.html
准备数据
import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import make_blobs from sklearn.neighbors import KNeighborsClassifier centers = [[1, 1], [-1, -1], [1, -1]] X, y = make_blobs(n_samples=100, n_features=2, centers=centers, cluster_std=0.4, random_state=0) # (100, 2) X.shape # (100,) y.shape plt.figure(figsize=(12, 8)) plt.scatter(X[:, 0], X[:, 1], s=100, c=y)
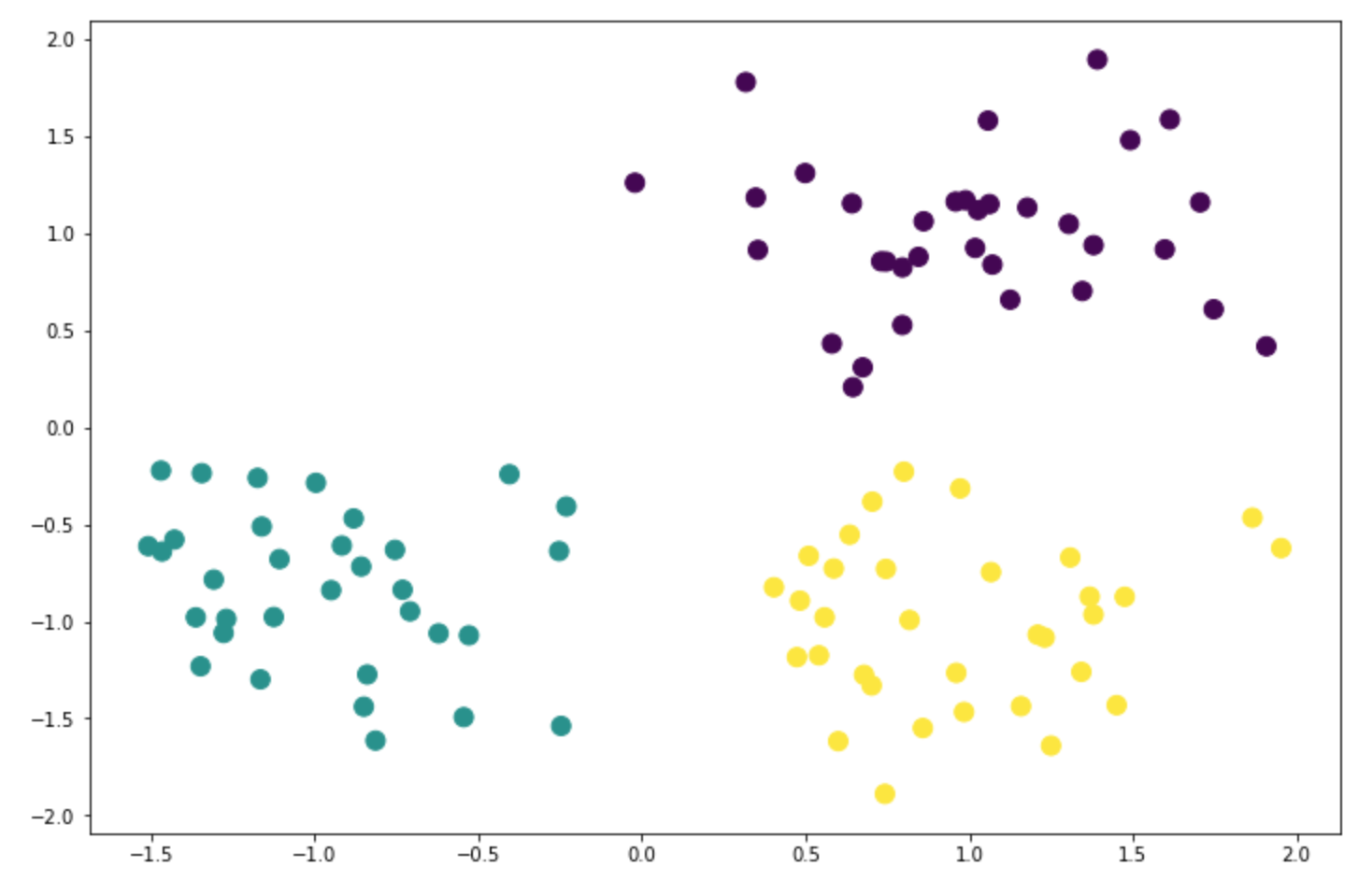
建模训练
# KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', # metric_params=None, n_jobs=None, n_neighbors=10, p=2, # weights='uniform') knn = KNeighborsClassifier(n_neighbors=10) knn.fit(X, y)
评价模型
X_test = np.array([0.25, 0]) # (2,) X_test.shape X_test = X_test.reshape(1, -1) # (1, 2) X_test.shape # 0.25 X_test[0][0] # 0.0 X_test[0][1] y_test = knn.predict(X_test) # (1,) y_test.shape neighbors = knn.kneighbors(X_test, return_distance=False) # array([[78, 37, 69, 89, 87, 71, 96, 46, 58, 21]]) neighbors plt.figure(figsize=(12, 8)) plt.scatter(X[:, 0], X[:, 1], c=y, s=100, cmap='cool') plt.scatter(X_test[0][0], X_test[0][1], s=200, c='orange') for i in neighbors[0]: plt.plot([X[i][0], X_test[0][0]], [X[i][1], X_test[0][1]], 'g', linewidth=1) # 1.0 knn.score(X, y)
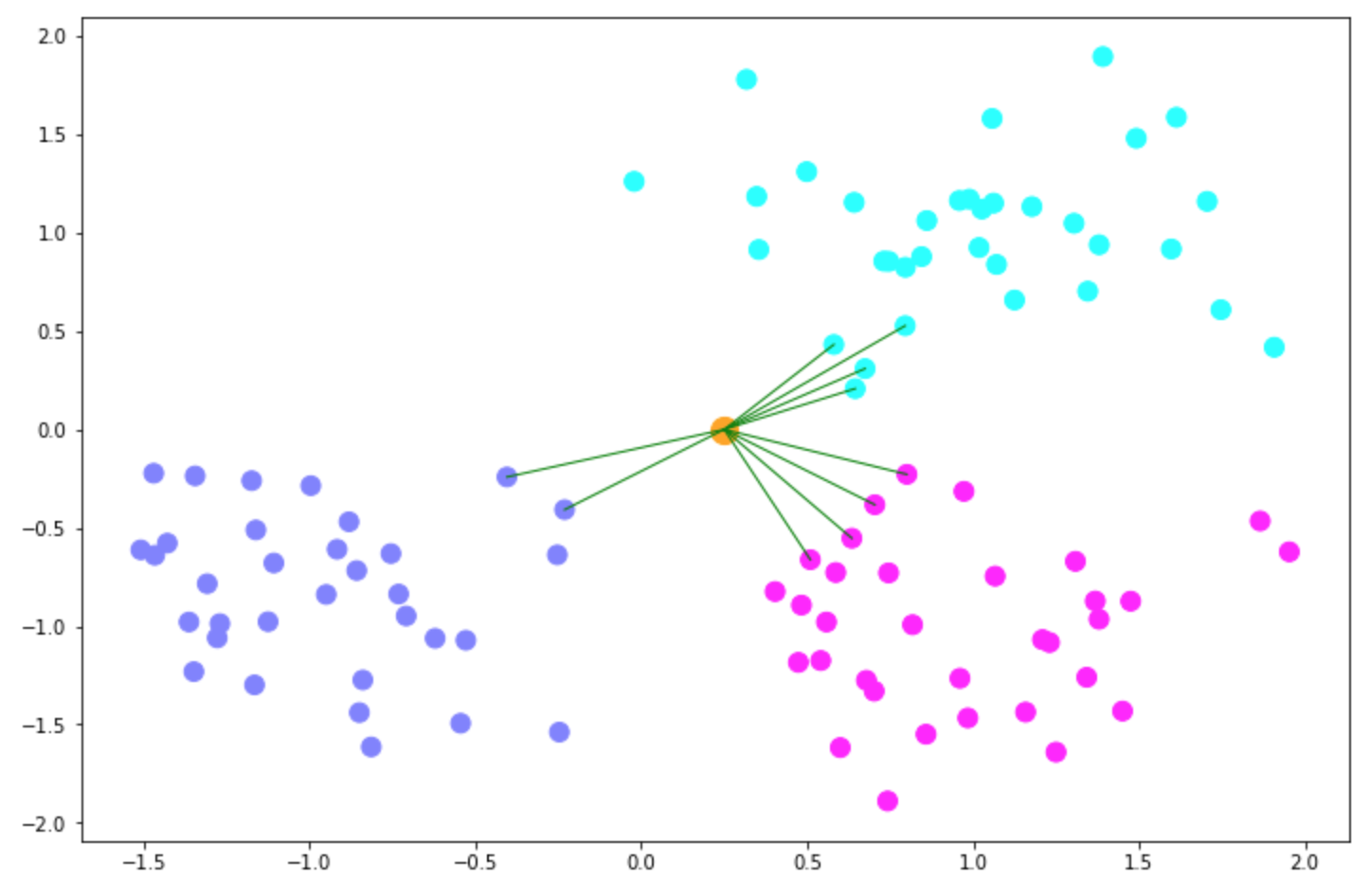
Note: 当前测试样本显示最近的有2类,具体划分给哪一类是根据样本的索引来定的,样本在X中都有对应的索引号。
- 如果 weights=uniform,不会考虑距离的大小,只要进入了前N名,只看个数,个数一样就看索引号较小的。
- 如果 weights=distance,会考虑距离的大小,不同距离不同权重。

Reference
https://matplotlib.org/3.2.1/api/_as_gen/matplotlib.pyplot.figure.html
https://matplotlib.org/3.2.1/api/_as_gen/matplotlib.pyplot.scatter.html
https://docs.w3cub.com/scikit_learn/modules/generated/sklearn.datasets.make_blobs/
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html