JAVA是一个面向对象的编程语言,由SUN公司的程序员所开发、它不仅吸收了C++的各种优点,而且还撇弃了C++中难以理解的概念,如多继承、指针等;因此JAVA语言具有功能强大且简单易用两个特征, JAVA作为静态面向对象语言的代表,是全世界最受欢迎的计算机语言
Java包含四个独立却又彼此相关的技术
1. JVM,Java的虚拟机,在JVM上运行Java的bytecode(字节码)
2. Java的程序编程语言
3. Java Class,Java的类文件格式;其决定Java程序编译出的字节码应该遵循那些规范等
4. JAVA的应用程序接口(Java API);为了能让Java的应用程序得到更快更高效的开发,Java官方提供了Java API
Java展示的文件通常都是Java类的文件格式,而Java的源程序要转换成字节码才能在JVM上运行
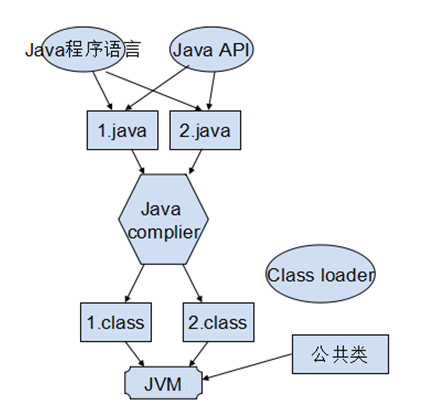
一般Java的程序代码从写到运行要经过以下几个步骤:
1. Java程序语言+Java API
2. X.java源程序经过编译器编译为Java的类文件如X.class(Java的类文件就是Java的字节码)
3. 在JVM中,class loader(类加载器)加载X.class类文件,然后由解释器将X.calss文件由字节码格式解释成对应的OS平台二进制程序,这样Java程序就可以再JVM上运行了
注:.class文件就是字节码,但字节码不能直接运行,仍需在JVM中由解释器解释成对应的OS二进制程序,才能运行(机器只能理解二进制)
JVM进行解释的实现方式:
1. 一次性解释器,解释字节码并执行,但第二次执行需要重新解释字节码
2. 即时编译器,解释完的类(字节码)会缓存再内存中,让下次执行时直接使用,不用再次执行,但这样对所有解释产生的二进制程序都缓存会非常占用内存
3. 自适应解释器,只将执行频率高的代码进行解释然后将解释后的二进制程序进行缓存,下次执行无需解释,一般只缓存20%的代码解释(认为这20%的代码完成了80%的操作)
下面是JAVA的执行过程
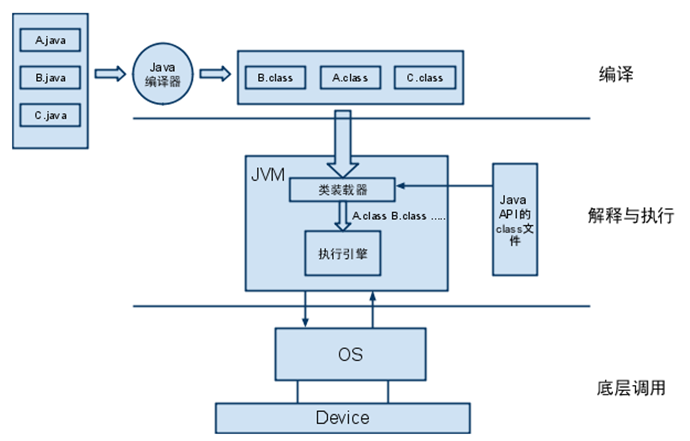
JVM(Java Virtual Machine)即Java虚拟机,是一种用于计算设备的规范,也是Java的核心和基础,是Java解释器和OS平台之间的虚拟处理器,它是一种基于下层的操作系统和硬件平台利用软件方法抽象出的计算机。可以在 上面执行Java的字节码程序,正是因为JVM的存在Java才实现了一次编译到处运行,可实现完全跨平台的运行。
Java的编译器只需面向JVM,生成JVM能理解的字节码文件,然后由JVM将每一条指令翻译成为不同平台的机器代码(二进制程序),然后既可以在对应的平台执行。
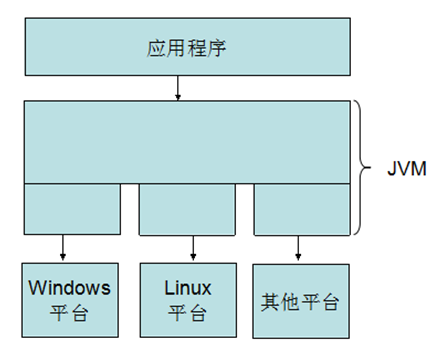
Java平台由Java虚拟机(Java Virtual Machine,简称JVM)和Java 应用编程接口(Application Programming Interface,简称API)构成。Java应用编程接口为此提供了一个独立于操作系统的标准接口,可分为基本部分和扩展部分。在硬件或操作系统平台上安装一个Java平台之后,Java应用程序就可运行。Java平台已经嵌入了几乎所有的操作系统。这样Java程序可以只编译一次,就可以在各种系统中运行。Java应用编程接口已经从1.1x版发展到1.2版。常用的Java平台基于Java1.5,最近版本为Java7.0。
JRE (Java running Environment)Java的运行环境:JRE可以让编译好的类(字节码)运行起来,是让Java运行起来的最小环境。简单来说JRE=JVM+API(不包括与开发有关的API)
JDK (Java Development Kit)是Java语言的软件开发工具包,是实现Java语言开发并让其运行的最小环境。简单来说JDK=Java语言+API+编译器+JVM
依据Java应用领域的不同,JDK有以下几种分类:
• Java SE(J2SE),standard edition,标准版,是我们通常用的一个版本,从JDK 5.0开始,改名为Java SE。
• Java EE(J2EE),enterprise edition,企业版,使用这种JDK开发J2EE应用程序,从JDK 5.0开始,改名为Java EE。
• Java ME(J2ME),micro edition,主要用于移动设备、嵌入式设备上的java应用程序,从JDK 5.0开始,改名为Java ME。
没有JDK的话,无法编译Java程序,如果想只运行Java程序,要确保已安装相应的JRE。
下面来讲Java两个特殊的类Applet和Servlet
Applet是采用Java编程语言编写的,经过编译后Applet小程序可以嵌入到HTML中去(含有Applet的网页的HTML文件代码中部带有<applet> 和</applet>这样一对标记),然后client端的浏览器中只要安装JRE插件就可以在client端运行这个Apple应用小程序,并将结果显示在client上,这便是客户端动态网站
但是客户端动态网站有一很危险的地方,那就是如果有人给你往HTML网页中嵌入的是一个有害的applet程序,你在client一执行会对你的电脑造成破坏,而且applet的执行必须在client端安装有JRE,所以applet现在已经很少见了
HTML文件中关于Applet的信息至少应包含以下三点:
1)字节码文件名(编译后的Java文件,以.class为后缀)
2)字节码文件的地址
3)在网页上显示Applet的方式。
Servlet(Server Applplet)是用Java编写的服务器端程序,其主要功能为交互式的浏览和修改数据,生成动态的Web资源;Servlet可以让Java语言依据类似的CGI(common gateway interface)技术开发运行在服务器端的动态web资源,但在通信量大的服务器上,Java Servlet 的优点在于它们的执行速度更快于 CGI 程序。各个用户请求被激活成单个程序中的一个线程,而无需创建单独的进程,这意味着服务器端处理请求的系统开销将明显降低。
Servlet 的主要功能在于交互式地浏览和修改数据,生成动态 Web 内容。这个过程为:
1.客户端发送请求至服务器端;
2.服务器将请求信息发送至 Servlet;
3.Servlet 生成响应内容并将其传给服务器。响应内容动态生成,通常取决于客户端的请求;
4.服务器将响应返回给客户端。
JSP(Java Server Page)Java的服务器页面,它是Servlet的一个特殊的类,在根本上是一个简化的Servlet设计,JSP是在传统的网页HTML文件(*.html或*.htm)中插入Java的程序段,从而形成了JSP文件(通常为*.jsp);用JSP开发的web应用是支持跨平台的,既能在Linux上运行,也能在其他的操作系统上运行,开发JSP程序的一个著名框架是SSH(Structs、Spring、Hebernate)
JSP实现了Html语法中的java扩展(以 <%, %>形式)。JSP与Servlet一样,是在服务器端执行的。通常返回给客户端的就是一个HTML文本,因此客户端只要有浏览器就能浏览(Applet要在client上装JRE)。
注:Applet只是将一个编译后的Applet小程序嵌入到HTML中然后发送到client,在client端依据JRE运行。
Servlet主要是实现了用Java语言开发运行在server端的Web动态资源;而这些依据Java语言开发的web动态资源大多数都是.jsp资源。
JSP是一种脚本语言,主要实现了将JAVA代码嵌入到HTML中(这也是JSP和Servlet的最主要区别),从而生成了.jsp类的web动态资源,从而实现了基于Java技术的动态网站开发。
JSP的运行性能要比PHP好,所以一些大型站点都用JSP开发,.jsp程序执行流程如下
1. .jsp由Jasper处理未.java源程序
2. .java由编译器编译为.class
3. .class类在jvm上进行加载解释并运行
JSP 的运程过程
一个JSP页面有多个客户访问,下面是第一个客户访问JSP页面时候,JSP页面的执行流程:
客户通过浏览器向服务器端的JSP页面发送请求
• JSP引擎检查JSP文件对应的Servlet源代码是否存在,若不存在转向第4步,否则执行下一步
• JSP引擎检查JSP页面是否需要修改,若没修改,转向第5步,否则执行下一步
• JSP引擎将JSP页面文件转译为Servlet源代码(相应的 .java 代码)
• JSP引擎将Servlet源代码编译为相应字节码( .class代码 )
• JSP引擎加载字节码到内存
• 字节码处理客户请求,并将结果返回给客户
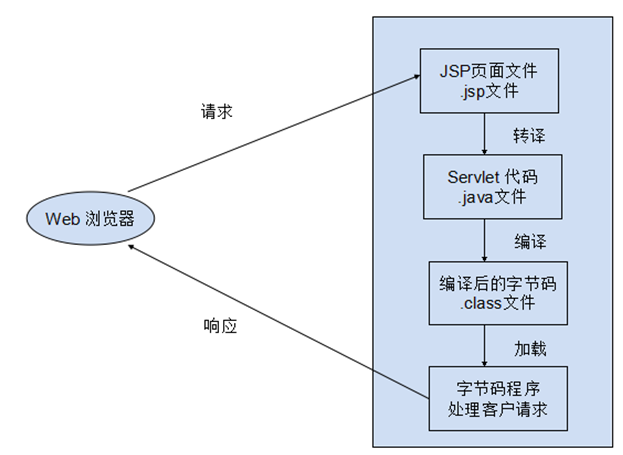
在不修改JSP页面的情况下,除了第一个客户访问JSP页面需要经过以上几个步骤外,以后访问该JSP页面的客户请求,直接发送给JSP对应的字节码程序处理,并将处理结果返回给客户,这种情况下,JSP页面既不需要启动服务器,以便重新加载修改后的JSP页面。
CGI(Common Gateway Interface)通用网关接口,CGI是外部应用程序(CGI程序)和Web服务器之间的接口标准(也可以理解为一种协议或机制),是在CGI程序和Web服务器之间传递信息的过程;CGI可以让一个客户端,从网页浏览器向执行在网络服务器上的程序传输数据CGI描述了客户端和服务器之间传输的一种标准
下面列子可以理解CGI的作用
客户端请求服务器,web服务器响应一个HTML静态的表单,而用户填写完表单后又将此表单交给了web服务器(相当于又一次http请求),web服务器收到client端填写的表单后会以CGI协议的方式提交给后端的应用程序让其处理
很多应用程序都可以传递参数,CGI可以让用户通过表单提供一些数据,然后把这些数据当做参数传递给相应的后端应用程序(如PHP)让程序对其加工处理(不过后端应用程序是PHP、C、C++甚至是一个脚本CGI都可以与其交互)让后端程序或脚本来处理数据,处理完后,后端程序再次通过CGI机制返回给前段的web服务器(httpd/Nginx)再由web服务器将结果封装响应给客户端
在LAMP和LNMP架构中PHP与前段Apache/Nginx之间就是通过CGI机制结合的,用于将客户端的动态请求(主要为php的动态资源请求)从前端web_server传递到后端的PHP,让PHP处理。
Servlet Container(Servlet容器):包含JDK及JDK所不具备的功能,可以让一个Servlet运行起来,有相应的Servlet进程,Servlet进程负责接收前端CGI传递来的请求,并在本地的JVM上运行处理,并且负责监控本地的.java程序是否发生了修改,一旦发生修改则重新让编译器(由JDK提供)编译成.class类
Web Container (Web容器)是一个包含Jasper和Servlet相关的技术的框架,其中Jasper负责监控本地的.jsp程序是否发生修改,一旦修改就根据需求将其装换为.java源代码,而.java就交给Servlet处理
注:Web Container比Servlet Container多了一个Jasper
而现在很多的Web容器都可以直接和用户的请求直接进行交互(即前端没有web server解码http请求和封装http响应)web容器可以完全依靠自己的组件(对Tomcat来说为web container的连接器)实现直接与client进行交互。但是让连接器直接面对用户的请求,可能会造成压力过大处理不过来的情况(如果连接器的性能不是很好),所以一般会在前端加一个web代理(如Nginx),让Nginx建立、维持、释放用户的请求和连接,而当用户的请求资源在前端web server(Nginx)上没有缓存时,再由Nginx将请求转发到后端web Container(如Tomcat)处理。而对应的这种架构叫:
Nginx + Java的Web Container(有时也成为应用程序服务器)
但无论是Web Container还是Servlet Container或者是JDK都是在JVM中运行的,Web Container|Servlet Container|JDK真正启动后再OS中表现的都是一个JVM进程(JVM实例),即在JVM中如果你是一个Web Containter它就有Web Container的功能,是JDK就有JDK的功能,负责只有JVM自身的功能
JVM实例可以在同一个JVM实例中启动多个线程,从而完成并发响应,JVM中还包括:
线程私有内存区
1. 程序计数器
2. Java虚拟机栈(主要用来保存本地变量)
线程共享内存区
1. 方法区
2. 堆(堆占用的内存最大)主要用来存储对象,当计数器为0时就认为对象已死,然后由GC(Garbage Collector)进行清除,避免堆溢出
而GC对对象的清理要依据一定的算法,有以下几种
1. 标记清除算法(哪个对象死了先进行标记,然后统一清除),但这种机制有个弊端就是在GC进行垃圾清除时会让CPU飙升,造成服务器性能忽然下降,且会产生大量的内存碎片
2. 复制算法,每个对象存两份,不会产生内存碎片但是内存使用率只有1/2
GC的种类
1. serial 一次只能回收一个对象,串行
2. parNew 一次可以回收读个,并行回收
3. CMS(Concurrent Mark Sweet)并行标记清除,多线程,尽可能降低清除对JVM中程序的停顿,但缺点是无法收集浮动垃圾(只要线程在运行,就不能收集)
4. G 1 特点是不会产生内存碎片、可以定义停顿的时间
数据库技术相关,这一部分主要讲解sql,毕竟现有的关系型数据库都支持sql,并且生产环境大部分还是使用关系型数据库。再者总结下mysql与oracle的优缺点,使用场景,注意事项。
- sql基础:库、表的创建,修改,删除,查询,索引,主从表,权限,事务,运算符,函数
- 常用查询技术:多表连接,子查询
- 触发器,存储过程
- 数据库优化
- 备份,恢复
总结完这一部分,然后在归纳写javaweb常用的技术,包括:
- web基础:xml,html/css/js,jsp/serlvet,jstl/EL,json,ajax
- 主流框架:spring/springmvc,log4j,junit,mybatis,maven
- 常用服务器:tomcat
- 常用第三方接口:如,支付宝支付接口,充值缴费接口等
上述内容只是基础,而且还是术的方面。我觉得要写出优雅,健壮,可扩展的代码。除了基础扎实外,还需要了解,体会,感悟道的方面,比如说编程思想,规范,设计模式,软件工程等相关的内容。因此下一个部分就是:
- 常用设计模式:例如工厂、单例、代理等
- 修炼数据:《clean code》,《java编程思想》,《代码重构》,《effective java》,《敏捷技能修炼》,《think in java》
一、基础篇
1.1 JVM
1.1.1. Java内存模型,Java内存管理,Java堆和栈,垃圾回收
1.1.2. 了解JVM各种参数及调优
1.1.3. 学习使用Java工具
jps, jstack, jmap, jconsole, jinfo, jhat, javap, …
http://kenai.com/projects/btrace
http://www.crashub.org/
https://github.com/taobao/TProfiler
https://github.com/CSUG/HouseMD
http://wiki.cyclopsgroup.org/jmxterm
https://github.com/jlusdy/TBJMap
1.1.4. 学习Java诊断工具
http://www.eclipse.org/mat/
http://visualvm.java.net/oqlhelp.html
1.1.5. 自己编写各种outofmemory,stackoverflow程序
HeapOutOfMemory
Young OutOfMemory
MethodArea OutOfMemory
ConstantPool OutOfMemory
DirectMemory OutOfMemory
Stack OutOfMemory
Stack OverFlow
1.1.6. 使用工具尝试解决以下问题,并写下总结
当一个Java程序响应很慢时如何查找问题
当一个Java程序频繁FullGC时如何解决问题,如何查看垃圾回收日志
当一个Java应用发生OutOfMemory时该如何解决,年轻代、年老代、永久代解决办法不同,导致原因也不同
1.1.7. 参考资料
http://docs.oracle.com/javase/specs/jvms/se7/html/
http://www.cs.umd.edu/~pugh/java/memoryModel/
http://gee.cs.oswego.edu/dl/jmm/cookbook.html
1.2. Java基础知识
1.2.1. 阅读源代码
java.lang.String
java.lang.Integer
java.lang.Long
java.lang.Enum
java.math.BigDecimal
java.lang.ThreadLocal
java.lang.ClassLoader & java.net.URLClassLoader
java.util.ArrayList & java.util.LinkedList
java.util.HashMap & java.util.LinkedHashMap & java.util.TreeMap
java.util.HashSet & java.util.LinkedHashSet & java.util.TreeSet
1.2.2. 熟悉Java中各种变量类型
1.2.3. 熟悉Java String的使用,熟悉String的各种函数
1.2.4. 熟悉Java中各种关键字
1.2.5. 学会使用List,Map,Stack,Queue,Set
上述数据结构的遍历
上述数据结构的使用场景
Java实现对Array/List排序
java.uti.Arrays.sort()
java.util.Collections.sort()
Java实现对List去重
Java实现对List去重,并且需要保留数据原始的出现顺序
Java实现最近最少使用cache,用LinkedHashMap
1.2.6. Java IO&Java NIO,并学会使用
java.io.*
java.nio.*
nio和reactor设计模式
文件编码,字符集
1.2.7. Java反射与javassist
反射与工厂模式
java.lang.reflect.*
1.2.8. Java序列化
java.io. Serializable
什么是序列化,为什么序列化
序列化与单例模式
google序列化protobuf
1.2.9. 虚引用,弱引用,软引用
java.lang.ref.*
实验这些引用的回收
1.2.10. 熟悉Java系统属性
java.util.Properties
1.2.11. 熟悉Annotation用法
java.lang.annotation.*
1.2.12. JMS
javax.jms.*
1.2.13. JMX
java.lang.management.*
javax.management.*
1.2.14. 泛型和继承,泛型和擦除
1.2.15. 自动拆箱装箱与字节码
1.2.16. 实现Callback
1.2.17. java.lang.Void类使用
1.2.18. Java Agent,premain函数
java.lang.instrument
1.2.19. 单元测试
Junit, http://junit.org/
Jmockit, https://code.google.com/p/jmockit/
djUnit, http://works.dgic.co.jp/djunit/
1.2.20. Java实现通过正则表达式提取一段文本中的电子邮件,并将@替换为#输出
java.lang.util.regex.*
1.2.21. 学习使用常用的Java工具库
commons.lang, commons.*…
guava-libraries
netty
1.2.22. 什么是API&SPI
http://en.wikipedia.org/wiki/Application_programming_interface
http://en.wikipedia.org/wiki/Service_provider_interface
1.2.23. 参考资料
JDK src.zip 源代码
http://openjdk.java.net/
http://commons.apache.org/
https://code.google.com/p/guava-libraries/
http://netty.io/
http://stackoverflow.com/questions/2954372/difference-between-spi-and-api
http://stackoverflow.com/questions/11404230/how-to-implement-the-api-spi-pattern-in-java
1.3. Java并发编程
1.3.1. 阅读源代码,并学会使用
java.lang.Thread
java.lang.Runnable
java.util.concurrent.Callable
java.util.concurrent.locks.ReentrantLock
java.util.concurrent.locks.ReentrantReadWriteLock
java.util.concurrent.atomic.Atomic*
java.util.concurrent.Semaphore
java.util.concurrent.CountDownLatch
java.util.concurrent.CyclicBarrier
java.util.concurrent.ConcurrentHashMap
java.util.concurrent.Executors
1.3.2. 学习使用线程池,自己设计线程池需要注意什么
1.3.3. 锁
什么是锁,锁的种类有哪些,每种锁有什么特点,适用场景是什么
在并发编程中锁的意义是什么
1.3.4. synchronized的作用是什么,synchronized和lock
1.3.5. sleep和wait
1.3.6. wait和notify
1.3.7. 写一个死锁的程序
1.3.8. 什么是守护线程,守护线程和非守护线程的区别以及用法
1.3.9. volatile关键字的理解
C++ volatile关键字和Java volatile关键字
happens-before语义
编译器指令重排和CPU指令重排
http://en.wikipedia.org/wiki/Memory_ordering
http://en.wikipedia.org/wiki/Volatile_variable
http://preshing.com/20130702/the-happens-before-relation/
1.3.10. 以下代码是不是线程安全?为什么?如果为count加上volatile修饰是否能够做到线程安全?你觉得该怎么做是线程安全的?
public class Sample{
private static int count =0;
public static void increment(){
count++;
}
}
1.3.11. 解释一下下面两段代码的差别
// 代码1
public class Sample {
private static int count = 0;
synchronized public static void increment() {
count++;
}
}
// 代码2
public class Sample {
private static AtomicInteger count = new AtomicInteger(0);
public static void increment() {
count.getAndIncrement();
}
}
1.3.12. 参考资料
http://book.douban.com/subject/10484692/
http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
二、 进阶篇
2.1. Java底层知识
2.1.1. 学习了解字节码、class文件格式
http://en.wikipedia.org/wiki/Java_class_file
http://en.wikipedia.org/wiki/Java_bytecode
http://en.wikipedia.org/wiki/Java_bytecode_instruction_listings
http://www.csg.ci.i.u-tokyo.ac.jp/~chiba/javassist/
http://asm.ow2.org/
2.1.2. 写一个程序要求实现javap的功能(手工完成,不借助ASM等工具)
如Java源代码:
public static void main(String[] args) {
int i = 0;
i += 1;
i *= 1;
System.out.println(i);
}
编译后读取class文件输出以下代码:
public static void main(java.lang.String[]);
Code:
Stack=2, Locals=2, Args_size=1
0: iconst_0
1: istore_1
2: iinc 1, 1
5: iload_1
6: iconst_1
7: imul
8: istore_1
9: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream;
12: iload_1
13: invokevirtual #3; //Method java/io/PrintStream.println:(I)V
16: return
LineNumberTable:
line 4: 0
line 5: 2
line 6: 5
line 7: 9
line 8: 16
2.1.3. CPU缓存,L1,L2,L3和伪共享
http://duartes.org/gustavo/blog/post/intel-cpu-caches/
http://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html
2.1.4. 什么是尾递归
2.1.5. 熟悉位运算
用位运算实现加、减、乘、除、取余
2.1.6. 参考资料
http://book.douban.com/subject/1138768/
http://book.douban.com/subject/6522893/
http://en.wikipedia.org/wiki/Java_class_file
http://en.wikipedia.org/wiki/Java_bytecode
http://en.wikipedia.org/wiki/Java_bytecode_instruction_listings
2.2. 设计模式
2.2.1. 实现AOP
CGLIB和InvocationHandler的区别,http://cglib.sourceforge.net/
动态代理模式
Javassist实现AOP,http://www.csg.ci.i.u-tokyo.ac.jp/~chiba/javassist/
ASM实现AOP,http://asm.ow2.org/
2.2.2. 使用模板方法设计模式和策略设计模式实现IOC
2.2.3. 不用synchronized和lock,实现线程安全的单例模式
2.2.4. nio和reactor设计模式
2.2.5. 参考资料
http://asm.ow2.org/
http://cglib.sourceforge.net/
2.3. 网络编程知识
2.3.1. Java RMI,Socket,HttpClient
2.3.2. 用Java写一个简单的静态文件的HTTP服务器
实现客户端缓存功能,支持返回304
实现可并发下载一个文件
使用线程池处理客户端请求
使用nio处理客户端请求
支持简单的rewrite规则
上述功能在实现的时候需要满足“开闭原则”
2.3.3. 了解nginx和apache服务器的特性并搭建一个对应的服务器
http://nginx.org/
http://httpd.apache.org/
2.3.4. 用Java实现FTP、SMTP协议
2.3.5. 什么是CDN?如果实现?DNS起到什么作用?
搭建一个DNS服务器
搭建一个 Squid 或 Apache Traffic Server 服务器
http://www.squid-cache.org/
http://trafficserver.apache.org/
http://en.wikipedia.org/wiki/Domain_Name_System
2.3.6. 参考资料
http://www.ietf.org/rfc/rfc2616.txt
http://tools.ietf.org/rfc/rfc5321.txt
http://en.wikipedia.org/wiki/Open/closed_principle
2.4. 框架知识
spring,spring mvc,阅读主要源码
ibatis,阅读主要源码
用spring和ibatis搭建java server
2.5. 应用服务器知识
熟悉使用jboss, https://www.jboss.org/overview/
熟悉使用tomcat, http://tomcat.apache.org/
熟悉使用jetty, http://www.eclipse.org/jetty/
三、 高级篇
3.1. 编译原理知识
3.1.1. 用Java实现以下表达式解析并返回结果(语法和Oracle中的select sysdate-1 from dual类似)
sysdate
sysdate -1
sysdate -1/24
sysdate -1/(12*2)
3.1.2. 实现对一个List通过DSL筛选
QList<Map<String, Object>> mapList = new QList<Map<String, Object>>;
mapList.add({"name": "hatter test"});
mapList.add({"id": -1,"name": "hatter test"});
mapList.add({"id": 0, "name": "hatter test"});
mapList.add({"id": 1, "name": "test test"});
mapList.add({"id": 2, "name": "hatter test"});
mapList.add({"id": 3, "name": "test hatter"});
mapList.query("id is not null and id > 0 and name like '%hatter%'");
要求返回列表中匹配的对象,即最后两个对象;
3.1.3. 用Java实现以下程序(语法和变量作用域处理都和JavaScript类似):
代码:
var a = 1;
var b = 2;
var c = function() {
var a = 3;
println(a);
println(b);
};
c();
println(a);
println(b);
输出:
3212
3.1.4. 参考资料
http://en.wikipedia.org/wiki/Abstract_syntax_tree
https://javacc.java.net/
http://www.antlr.org/
3.2. 操作系统知识
Ubuntu
Centos
使用linux,熟悉shell脚本
3.3. 数据存储知识
3.3.1. 关系型数据库
MySQL
如何看执行计划
如何搭建MySQL主备
binlog是什么
Derby,H2,PostgreSQL
SQLite
3.3.2. NoSQL
Cache
Redis
Memcached
Leveldb
Bigtable
HBase
Cassandra
Mongodb
图数据库
neo4j
3.3.3. 参考资料
http://db-engines.com/en/ranking
http://redis.io/
https://code.google.com/p/leveldb/
http://hbase.apache.org/
http://cassandra.apache.org/
http://www.mongodb.org/
http://www.neo4j.org/
3.4. 大数据知识
3.4.1. Zookeeper,在linux上部署zk
3.4.2. Solr,Lucene,ElasticSearch
在linux上部署solr,solrcloud,新增、删除、查询索引
3.4.3. Storm,流式计算,了解Spark,S4
在linux上部署storm,用zookeeper做协调,运行storm hello world,local和remote模式运行调试storm topology。
3.4.4. Hadoop,离线计算
Hdfs:部署NameNode,SecondaryNameNode,DataNode,上传文件、打开文件、更改文件、删除文件
MapReduce:部署JobTracker,TaskTracker,编写mr job
Hive:部署hive,书写hive sql,得到结果
Presto:类hive,不过比hive快,非常值得学习
3.4.5. 分布式日志收集flume,kafka,logstash
3.4.6. 数据挖掘,mahout
3.4.7. 参考资料
http://zookeeper.apache.org/
https://lucene.apache.org/solr/
https://github.com/nathanmarz/storm/wiki
http://hadoop.apache.org/
http://prestodb.io/
http://flume.apache.org/
http://logstash.net/
http://kafka.apache.org/
http://mahout.apache.org/
3.5. 网络安全知识
3.5.1. 什么是DES、AES
3.5.2. 什么是RSA、DSA
3.5.3. 什么是MD5,SHA1
3.5.4. 什么是SSL、TLS,为什么HTTPS相对比较安全
3.5.5. 什么是中间人攻击、如果避免中间人攻击
3.5.6. 什么是DOS、DDOS、CC攻击
3.5.7. 什么是CSRF攻击
3.5.8. 什么是CSS攻击
3.5.9. 什么是SQL注入攻击
3.5.10. 什么是Hash碰撞拒绝服务攻击
3.5.11. 了解并学习下面几种增强安全的技术
http://www.openauthentication.org/
HOTP http://www.ietf.org/rfc/rfc4226.txt
TOTP http://tools.ietf.org/rfc/rfc6238.txt
OCRA http://tools.ietf.org/rfc/rfc6287.txt
http://en.wikipedia.org/wiki/Salt_(cryptography)
3.5.12. 用openssl签一个证书部署到apache或nginx
3.5.13. 参考资料
http://en.wikipedia.org/wiki/Cryptographic_hash_function
http://en.wikipedia.org/wiki/Block_cipher
http://en.wikipedia.org/wiki/Public-key_cryptography
http://en.wikipedia.org/wiki/Transport_Layer_Security
http://www.openssl.org/
https://code.google.com/p/google-authenticator/
四、 扩展篇
4.1. 相关知识
4.1.1. 云计算,分布式,高可用,可扩展
4.1.2. 虚拟化
https://linuxcontainers.org/
http://www.linux-kvm.org/page/Main_Page
http://www.xenproject.org/
https://www.docker.io/
4.1.3. 监控
http://www.nagios.org/
http://ganglia.info/
4.1.4. 负载均衡
http://www.linuxvirtualserver.org/
4.1.5. 学习使用git
https://github.com/
https://git.oschina.net/
4.1.6. 学习使用maven
http://maven.apache.org/
4.1.7. 学习使用gradle
http://www.gradle.org/
4.1.8. 学习一个小语种语言
Groovy
Scala
LISP, Common LISP, Schema, Clojure
R
Julia
Lua
Ruby
4.1.9. 尝试了解编码的本质
了解以下概念
ASCII, ISO-8859-1
GB2312, GBK, GB18030
Unicode, UTF-8
不使用 String.getBytes() 等其他工具类/函数完成下面功能
public static void main(String[] args) throws IOException {
String str = "Hello, 我们是中国人。";
byte[] utf8Bytes = toUTF8Bytes(str);
FileOutputStream fos = new FileOutputStream("f.txt");
fos.write(utf8Bytes);
fos.close();
}
public static byte[] toUTF8Bytes(String str) {
return null; // TODO
}
想一下上面的程序能不能写一个转GBK的?
写个程序自动判断一个文件是哪种编码
4.1.10. 尝试了解时间的本质
时区 & 冬令时、夏令时
http://en.wikipedia.org/wiki/Time_zone
ftp://ftp.iana.org/tz/data/asia
http://zh.wikipedia.org/wiki/%E4%B8%AD%E5%9C%8B%E6%99%82%E5%8D%80
闰年, http://en.wikipedia.org/wiki/Leap_year
闰秒, ftp://ftp.iana.org/tz/data/leapseconds
System.currentTimeMillis() 返回的时间是什么
4.1.11. 参考资料
http://git-scm.com/
http://en.wikipedia.org/wiki/UTF-8
http://www.iana.org/time-zones
4.2. 扩展学习
4.2.1. JavaScript知识
4.2.1.1. 什么是prototype
修改代码,使程序输出“1 3 5”: http://jsfiddle.net/Ts7Fk/
4.2.1.2. 什么是闭包
看一下这段代码,并解释一下为什么按Button1时没有alert出“This is button: 1”,如何修改:
http://jsfiddle.net/FDPj3/1/
4.2.1.3. 了解并学习一个JS框架
jQuery
ExtJS
ArgularJS
4.2.1.4. 写一个Greasemonkey插件
http://en.wikipedia.org/wiki/Greasemonkey
4.2.1.5. 学习node.js
http://nodejs.org/
4.2.2. 学习html5
ArgularJS, https://docs.angularjs.org/api
4.2.3. 参考资料
http://www.ecmascript.org/
http://jsfiddle.net/
http://jsbin.com/
http://runjs.cn/
http://userscripts.org/
五、 推荐书籍
《深入Java虚拟机》 《深入理解Java虚拟机》 《Effective Java》 《七周七语言》 《七周七数据》 《Hadoop技术内幕》 《Hbase In Action》 《Mahout In Action》 《这就是搜索引擎》 《Solr In Action》 《深入分析Java Web技术内幕》 《大型网站技术架构》 《高性能MySQL》 《算法导论》 《计算机程序设计艺术》 《代码大全》 《JavaScript权威指南》
JAVA程序员技术栈、业务栈、工具栈 目录: 1、技术栈 2、业务栈 3、工具栈 今天是实习期以来将近100天了,感谢公司给予的期望与同事们提供的帮助。好久没更新博客了,一是懒于写,二是文章写得不够深刻、自身的知识体系还较零乱、理解不够全面和精湛,甚至存在偏差和误导,距离小目标的实现之路还很远很远,现总结一下我自身这三个月来作为一名研发部->项目组->实习JAVA开发工程师用到的一些技术栈、业务栈及工具栈。 三个月来,共参与项目四个: 架构管控项目一个; 开发维护项目一个; 新开发项目一个; 维保项目一个; 针对自己参与的项目,下面列出三个月来我涉及的一些技术栈、业务栈及工具栈概述: 1、技术栈: Java: SSM(Spring + Spring MVC + Mybatis): Spring: Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架; Spring MVC: Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制; Mybatis: MyBatis是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO)MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的 XML或注解用于配置和原始映射,将接口和 Java 的POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录; Java基础 多线程、Future、Callable 内部类、闭包和回调 并发、Executor Apache Commons CLI 开发命令行工具 JVM: 类加载机制; 线程安全; 垃圾回收机制——新生代、老年代、永久代,能够对需要执行的程序配置相关参数; JAVA堆; HaaS:统一Hadoop资源池平台,基于Hadoop等大数据技术,提供统一数据存储、计算能力 HDFS(Hadoop Distributed File System):海量数据存储 存储并管理PB级数据; 处理非结构化数据; 注重数据处理的吞吐量; 应用模式Write_Once_Read_Many; YARN(Yet Another Resource Negotiator):统一资源调度和分配 ResourceManager:负责集群资源管理和调度; ApplicationMaster:替代JobTracker负责计算任务的管理和调度; Nodemanager:替代TaskTracker负责每个节点上计算Task的管理和调度; MapReduce:非结构化、半结构化数据的海量批处理 Map:映射,用来把一组键值对映射成一组新的键值对; Reduce:归约,用来保证所有映射的键值对中的每一个共享相同的键组,并进行聚合计算; 核心思想: 利用成百上千个CPU并行处理海量数据; 移动计算比移动数据更划算; Spark:分布式内存计算框架 Spark是一种与Hadoop相似的开源集群计算环境,Spark使用了内存内运算技术,能在数据尚未写入硬盘时即在内存内分析运算,而相对于传统的大数据解决方案Hadoop的MapReduce会在运行完工作后将中介数据存放在磁盘中,Spark在内存内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍; Spark Streaming:实时/准实时流的计算框架 Spark Streaming将数据划分为一个一个的数据块(batch),每个数据块通过微批处理的方式对数据进行处理,在Spark Streaming中,数据处理的单位是一批而不是单条,而数据采集确是逐条进行的,因此Spark Streaming系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是Spark Streaming的核心概念和关键参数,它决定了Spark Streaming提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能; HBase:Key/Value、半结构化数据的海量存储和检索 分布式的、面向列的开源数据库; Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和故障转移机制。这使得HBase可以用于支撑亿级的海量数据存储和应用; Hive:结构化数据的查询和分析 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行; Hive擅长的是非实时的、离线的、对响应实时性要求不高的海量数据即席查询(SQL查询); Hive和传统关系型数据库有很大区别,Hive将外部的任务解析成一个MapReduce可执行计划,每次提交任务和执行任务都需要消耗很多时间(可以换用Tez计算框架来提升性能),这也就决定Hive只能处理一些高延迟的应用。 Zookeeper:分布式协同工具 Zookeeper是利用Paxos算法解决消息传递一致性的分布式服务框架; Zookeeper通过部署多台机器,能够实现分布式的负载均衡的访问服务。不同的Client向Zookeeper中不同机器请求数据; 为了实现集群中配置数据的增删改查保证一致性问题,需要有主节点,由主节点来做出修改的动作,并同步到其它节点上面; 当主节点出现故障时,将在其他节点中自动通过一定的选举方法选举出新的主节点; Oozie:任务调度工具 Oozie是Hadoop平台的一种工作流调度引擎,Oozie是一种Java Web应用程序,它运行在Java Servlet容器(Tomcat),并使用数据库来存储以下内容: 工作流定义; 当前运行的工作流实例,包括实例的状态和变量; Oozie工作流是放置在控制依赖DAG中的一组动作,其中指定了动作执行的顺序; Ambari:可视化集群管理工具 部署、启动、监控、查看、关闭Hadoop集群,可视化监控、运维、告警; Ambari主要由两部分组成: Ambari Server; Ambari Client; 用户通过Ambari Server通知Ambari Agent安装对应的软件,Ambari Agent会定时地发送各个机器每个软件模块的状态给Ambari Server,最终这些状态信息会呈现在Ambari的GUI,方便用户了解到集群的各种状态,并进行相应的维护; Kafka:分布式消息总线 Kafka是一个低延迟高吞吐的分布式消息队列,适用于离线和在线消息消费,用于低延迟地收集和发送大量的事件和日志数据; 消息队列(Message Queue)用于将消息生产的前端和后端服务架构解耦,它是一种pub-sub结构,前端消息生产者不需要知道后端消息消费者的情况,只需要将消息发布到消息队列中,且只用发布一次,即可认为消息已经被可靠存储了,不用再维护消息的一致性和持久化,同时消息只传输一次就可以给后端多个消费者,避免了每个消费者都直接去前端获取造成的前端服务器计算资源和带宽的浪费,甚至影响生产环境; 消息队列分为以下几种角色: Producer:生产者,即消息生产者,比如实时信令数据; Consumer: 消费者,即消息的消费者,比如后端的实时统计程序和批量挖掘程序; Consumer Group:消费者组,即消费者的并发单位,在数据量比较大的时候,需要分布式集群来处理消息,针对同一种消息,一组消费者各自消费某一Topic(话题,代表一些消息,Topic 是一个逻辑单位,一个 Topic 被划分成 N 个 Partition,在数据量大的时候通过 Partition 来实现分布式传输)的一部分,来协作处理; Broker:存储节点,Kafka支持将消息进行短暂的持久化,比如存储最近一周的数据,以便下游集群故障时,重新订阅之前丢失的数据。 在Kafka中,Producer自动通过Zookeeper获取到Broker列表,通过Partition算法自动负载均衡将消息发送到Broker集群。Broker 收到消息后自动分发到副本 Broker 上保证消息的可靠性。下游消费者通过 Zookeeper获取Broker集群位置和Topic等信息,自动完成订阅消费等动作。 Kerberos & Ranger:安全加固 Kerberos: 通过密钥系统为客户机/服务器应用程序提供强大的认证服务; Apache Ranger: 集中式安全管理框架,并解决授权和审计; 身份验证(Authentication):基于Kerberos的用户、服务身份验证; 统一账户(Account):使用统一应用账号访问平台众多服务; 访问授权(Authorization):基于Ranger的精细粒度访问权限; 操作审计(Audit):基于Ranger的集中式审计日志; DBaaS:开箱即用的关系型数据库服务 MySQL高可用: 主从复制: 一主一从 + Keepalived + VRRP((Virtual Router Redundancy Protocol,虚拟路由冗余协议): Keepalived: Keepalived是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。 VRRP: 解决静态路由单点故障问题,VRRP通过一竞选(election)协议来动态的将路由任务交给LAN中虚拟路由器中的某台VRRP路由器。 采用一主一从构建高可用MySQL服务,当主机宕机时,可以自动触发主从节点切换。通过使用VIP + Keepalived组件,实现主从切换时MySQL服务IP自动漂移,主从库自动切换。 MHA(一主一从一只读) + Keepalived + VRRP: MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。 CssS:提供标准化的容器技术和容器管理方案,支撑无状态应用的标准化打包和部署 Docker:开源应用容器引擎 Docker是Docker公司开源的一个基于轻量级虚拟化技术的容器引擎项目,整个项目 基于 Go 语言开发,并遵从 Apache 2.0 协议; 当前,Docker可以在容器内部快速自动化部署应用,并可以通过内核虚拟化技术 (namespaces及cgroups等) 来提供容器的资源隔离与安全保障等; Docker通过操作系统层的虚拟化实现隔离,所以Docker容器在运行时,不需要类似 虚拟机(VM)额外的操作系统开销,提高资源利用率,并且提升诸如I/O等方面的性能; Docker彻底释放了虚拟化的潜力和威力,极大降低了云计算资源供应的成本,同时让业务应用的开发、测试、部署都变得前所未有敏捷、高效和轻松; Kubernetes:容器集群管理系统 Kubernetes是Google开源的容器集群管理系统,其提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,其主要功能如下: 使用Docker对应用程序包装(package)、实例化(instantiate)、运行(run); 以集群的方式运行、管理跨机器的容器; 解决Docker跨机器容器之间的通讯问题; Kubernetes的自我修复机制使得容器集群总是运行在用户期望的状态; DevOps:开发运维一体化 第一阶段:核心实践和试点; 第二阶段:持续集成和测试; 第三阶段:持续部署和交付; 第四阶段:持续运维; 第五阶段:持续评估改进; 统一日志服务:提供多租户安全的系统、应用海量日志分析、交互式查询和可视化 核心能力: 规划构建的统一日志平台核心能力包括: 多租户安全:支持多租户端到端业务日志的存储、分析、可视化能力,支持多租户数据安全; 分析挖掘能力:通过Elasticsearch的结构化查询,实现复杂的多维度联合查询及数据聚合,深度挖掘日志数据; 可视化能力:支持图表可视化呈现分析结果,支持Dashboard实时监控关键指标; Filebeat: 轻量级的日志采集器,部署于应用侧,负责实时采集日志; Logstash: 负责日志解析和转发,灵活的正则配置可同时处理不同数据结构的日志,并写入Elasticsearch不同索引; Kafka: 分布式消息队列,在Filebeat和Logstash中引入分布式消息队列Kafka,可以从容的应对峰值数据的高负载,并且在Logstash出现故障时,具备良好的恢复能力,可直接从Kafka做数据回放,避免回溯至若干上游应用; Elasticsearch: 负责日志(原始数据、分析数据)的存储、索引和搜索,是实时分析数据流程的核心组件; Kibana: 前端可视化工具,Elasticsearch的皮肤,结合Elasticsearch丰富的查询逻辑,可定制多种图表; Linux命令行: FTP、不同服务器之间、服务器与本地上传/下载、进程监控、内存监控、JVM监控、打包部署、Vim编辑、文件授权、审阅日志文件等等; Bash脚本开发: 能够阅读并编写简单的脚本; Python: 能够阅读一般的Python脚本,深入后可学习爬虫; 机器学习算法: 逻辑回归算法; 基于特征的推荐算法; 分类算法; 聚类算法; 2、工具栈: 版本管理工具:Git,SVN; JAVA开发IDE:Intellij IDEA; 项目构建工具:Maven; 文本编辑器:Subline、NotePad等; 数据库管理工具:Navicat、SQLite Free等; 终端仿真程序:SecureCRT、Xshell5等; 3、业务栈: Tower化记录: 做好任务的Tower化记录,包括: 需求由来; 任务的具体描述; 解决问题的过程中关键细节记录; 抄送给相关的项目负责人,并给出制定出解决问题的时间; 任务结论及相关解决方案文件的上传; CPS工作清单: 对于维护过程中出现的每一个相关问题,应养成记录的良好习惯,方便未来进行整理和排查。因此建立DMP项目维护工作清单,对于维护项的类别、详细描述、维护时间、维护耗时、处理结果、维护相关人员及对应的Tower任务链接进行记录; 现有任务梳理: 梳理遗留任务清单并标注优先级; 评估还需要多少人天可以完成问题及Bug; 评估未来的运维(不含新需求)每周需要投入的人力; 每周工作明细: bug修复:总数 + 清单明细(包括分工、人天耗时); 新功能增加:总数 + 清单明细; 功能优化:总数 + 清单明细; 下周工作计划: 遇到的问题: 解决方案: XXX 求助: XXX
1 java基础: 1.1 算法 1.1 排序算法:直接插入排序、希尔排序、冒泡排序、快速排序、直接选择排序、堆排序、归并排序、基数排序 1.2 二叉查找树、红黑树、B树、B+树、LSM树(分别有对应的应用,数据库、HBase) 1.3 BitSet解决数据重复和是否存在等问题 1.2 基本 2.1 字符串常量池的迁移 2.2 字符串KMP算法 2.3 equals和hashcode 2.4 泛型、异常、反射 2.5 string的hash算法 2.6 hash冲突的解决办法:拉链法 2.7 foreach循环的原理 2.8 static、final、transient等关键字的作用 2.9 volatile关键字的底层实现原理 2.10 Collections.sort方法使用的是哪种排序方法 2.11 Future接口,常见的线程池中的FutureTask实现等 2.12 string的intern方法的内部细节,jdk1.6和jdk1.7的变化以及内部cpp代码StringTable的实现 1.3 设计模式 单例模式 工厂模式 装饰者模式 观察者设计模式 ThreadLocal设计模式 。。。 1.4 正则表达式 4.1 捕获组和非捕获组 4.2 贪婪,勉强,独占模式 1.5 java内存模型以及垃圾回收算法 5.1 类加载机制,也就是双亲委派模型 5.2 Java内存分配模型(默认HotSpot) 线程共享的:堆区、永久区 线程独享的:虚拟机栈、本地方法栈、程序计数器 5.3 内存分配机制:年轻代(Eden区、两个Survivor区)、年老代、永久代以及他们的分配过程 5.4 强引用、软引用、弱引用、虚引用与GC 5.5 happens-before规则 5.6 指令重排序、内存栅栏 5.7 Java 8的内存分代改进 5.8 垃圾回收算法: 标记-清除(不足之处:效率不高、内存碎片) 复制算法(解决了上述问题,但是内存只能使用一半,针对大部分对象存活时间短的场景,引出了一个默认的8:1:1的改进,缺点是仍然需要借助外界来解决可能承载不下的问题) 标记整理 5.8 常用垃圾收集器: 新生代:Serial收集器、ParNew收集器、Parallel Scavenge 收集器 老年代:Serial Old收集器、Parallel Old收集器、CMS(Concurrent Mark Sweep)收集器、 G1 收集器(跨新生代和老年代) 5.9 常用gc的参数:-Xmn、-Xms、-Xmx、-XX:MaxPermSize、-XX:SurvivorRatio、-XX:-PrintGCDetails 5.10 常用工具: jps、jstat、jmap、jstack、图形工具jConsole、Visual VM、MAT 1.6 锁以及并发容器的源码 6.1 synchronized和volatile理解 6.2 Unsafe类的原理,使用它来实现CAS。因此诞生了AtomicInteger系列等 6.3 CAS可能产生的ABA问题的解决,如加入修改次数、版本号 6.4 同步器AQS的实现原理 6.5 独占锁、共享锁;可重入的独占锁ReentrantLock、共享锁 实现原理 6.6 公平锁和非公平锁 6.7 读写锁 ReentrantReadWriteLock的实现原理 6.8 LockSupport工具 6.9 Condition接口及其实现原理 6.10 HashMap、HashSet、ArrayList、LinkedList、HashTable、ConcurrentHashMap、TreeMap的实现原理 6.11 HashMap的并发问题 6.12 ConcurrentLinkedQueue的实现原理 6.13 Fork/Join框架 6.14 CountDownLatch和CyclicBarrier 1.7 线程池源码 7.1 内部执行原理 7.2 各种线程池的区别 2 web方面: 2.1 SpringMVC的架构设计 1.1 servlet开发存在的问题:映射问题、参数获取问题、格式化转换问题、返回值处理问题、视图渲染问题 1.2 SpringMVC为解决上述问题开发的几大组件及接口:HandlerMapping、HandlerAdapter、HandlerMethodArgumentResolver、HttpMessageConverter、Converter、GenericConverter、HandlerMethodReturnValueHandler、ViewResolver、MultipartResolver 1.3 DispatcherServlet、容器、组件三者之间的关系 1.4 叙述SpringMVC对请求的整体处理流程 1.5 SpringBoot 2.2 SpringAOP源码 2.1 AOP的实现分类:编译期、字节码加载前、字节码加载后三种时机来实现AOP 2.2 深刻理解其中的角色:AOP联盟、aspectj、jboss AOP、spring自身实现的AOP、Spring嵌入aspectj。特别是能用代码区分后两者 2.3 接口设计: AOP联盟定义的概念或接口:Pointcut(概念,没有定义对应的接口)、Joinpoint、Advice、MethodInterceptor、MethodInvocation SpringAOP针对上述Advice接口定义的接口及其实现类:BeforeAdvice、AfterAdvice、MethodBeforeAdvice、AfterReturningAdvice;针对aspectj对上述接口的实现AspectJMethodBeforeAdvice、AspectJAfterReturningAdvice、AspectJAfterThrowingAdvice、AspectJAfterAdvice。 SpringAOP定义的定义的AdvisorAdapter接口:将上述Advise转化为MethodInterceptor SpringAOP定义的Pointcut接口:含有两个属性ClassFilter(过滤类)、MethodMatcher(过滤方法) SpringAOP定义的ExpressionPointcut接口:实现中会引入aspectj的pointcut表达式 SpringAOP定义的PointcutAdvisor接口(将上述Advice接口和Pointcut接口结合起来) 2.4 SpringAOP的调用流程 2.5 SpringAOP自己的实现方式(代表人物ProxyFactoryBean)和借助aspectj实现方式区分 2.3 Spring事务体系源码以及分布式事务Jotm Atomikos源码实现 3.1 jdbc事务存在的问题 3.2 Hibernate对事务的改进 3.3 针对各种各样的事务,Spring如何定义事务体系的接口,以及如何融合jdbc事务和Hibernate事务的 3.4 三种事务模型包含的角色以及各自的职责 3.5 事务代码也业务代码分离的实现(AOP+ThreadLocal来实现) 3.6 Spring事务拦截器TransactionInterceptor全景 3.7 X/Open DTP模型,两阶段提交,JTA接口定义 3.8 Jotm、Atomikos的实现原理 3.9 事务的传播属性 3.10 PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED的实现原理以及区别 3.11 事物的挂起和恢复的原理 2.4 数据库隔离级别 4.1 Read uncommitted:读未提交 4.2 Read committed : 读已提交 4.3 Repeatable read:可重复读 4.4 Serializable :串行化 2.5 数据库 5.1 数据库性能的优化 5.2 深入理解MySQL的Record Locks、Gap Locks、Next-Key Locks 例如下面的在什么情况下会出现死锁: start transaction; DELETE FROM t WHERE id =6; INSERT INTO t VALUES(6); commit; 5.3 insert into select语句的加锁情况 5.4 事务的ACID特性概念 5.5 innodb的MVCC理解 5.6 undo redo binlog 1 undo redo 都可以实现持久化,他们的流程是什么?为什么选用redo来做持久化? 2 undo、redo结合起来实现原子性和持久化,为什么undo log要先于redo log持久化? 3 undo为什么要依赖redo? 4 日志内容可以是物理日志,也可以是逻辑日志?他们各自的优点和缺点是? 5 redo log最终采用的是物理日志加逻辑日志,物理到page,page内逻辑。还存在什么问题?怎么解决?Double Write 6 undo log为什么不采用物理日志而采用逻辑日志? 7 为什么要引入Checkpoint? 8 引入Checkpoint后为了保证一致性需要阻塞用户操作一段时间,怎么解决这个问题?(这个问题还是很有普遍性的,redis、ZooKeeper都有类似的情况以及不同的应对策略)又有了同步Checkpoint和异步Checkpoint 9 开启binlog的情况下,事务内部2PC的一般过程(含有2次持久化,redo log和binlog的持久化) 10 解释上述过程,为什么binlog的持久化要在redo log之后,在存储引擎commit之前? 11 为什么要保持事务之间写入binlog和执行存储引擎commit操作的顺序性?(即先写入binlog日志的事务一定先commit) 12 为了保证上述顺序性,之前的办法是加锁prepare_commit_mutex,但是这极大的降低了事务的效率,怎么来实现binlog的group commit? 13 怎么将redo log的持久化也实现group commit?至此事务内部2PC的过程,2次持久化的操作都可以group commit了,极大提高了效率 2.6 ORM框架: mybatis、Hibernate 6.1 最原始的jdbc->Spring的JdbcTemplate->hibernate->JPA->SpringDataJPA的演进之路 2.7 SpringSecurity、shiro、SSO(单点登录) 7.1 Session和Cookie的区别和联系以及Session的实现原理 7.2 SpringSecurity的认证过程以及与Session的关系 7.3 CAS实现SSO(详见Cas(01)——简介) 2.8 日志 8.1 jdk自带的logging、log4j、log4j2、logback 8.2 门面commons-logging、slf4j 8.3 上述6种混战时的日志转换 2.9 datasource 9.1 c3p0 9.2 druid 9.3 JdbcTemplate执行sql语句的过程中对Connection的使用和管理 2.10 HTTPS的实现原理 3 分布式、java中间件、web服务器等方面: 3.1 ZooKeeper源码 1.1 客户端架构 1.2 服务器端单机版和集群版,对应的请求处理器 1.3 集群版session的建立和激活过程 1.4 Leader选举过程 1.5 事务日志和快照文件的详细解析 1.6 实现分布式锁、分布式ID分发器 1.7 实现Leader选举 1.8 ZAB协议实现一致性原理 3.2 序列化和反序列化框架 2.1 Avro研究 2.2 Thrift研究 2.3 Protobuf研究 2.4 Protostuff研究 2.5 Hessian 3.3 RPC框架dubbo源码 3.1 dubbo扩展机制的实现,对比SPI机制 3.2 服务的发布过程 3.3 服务的订阅过程 3.4 RPC通信的设计 3.4 NIO模块以及对应的Netty和Mina、thrift源码 4.1 TCP握手和断开及有限状态机 4.2 backlog 4.3 BIO NIO 4.4 阻塞/非阻塞的区别、同步/异步的区别 4.5 阻塞IO、非阻塞IO、多路复用IO、异步IO 4.6 Reactor线程模型 4.7 jdk的poll、epoll与底层poll、epoll的对接实现 4.8 Netty自己的epoll实现 4.9 内核层poll、epoll的大致实现 4.10 epoll的边缘触发和水平触发 4.11 Netty的EventLoopGroup设计 4.12 Netty的ByteBuf设计 4.13 Netty的ChannelHandler 4.13 Netty的零拷贝 4.14 Netty的线程模型,特别是与业务线程以及资源释放方面的理解 3.5 消息队列kafka、RocketMQ、Notify、Hermes 5.1 kafka的文件存储设计 5.2 kafka的副本复制过程 5.3 kafka副本的leader选举过程 5.4 kafka的消息丢失问题 5.5 kafka的消息顺序性问题 5.6 kafka的isr设计和过半对比 5.7 kafka本身做的很轻量级来保持高效,很多高级特性没有:事务、优先级的消息、消息的过滤,更重要的是服务治理不健全,一旦出问题,不能直观反应出来,不太适合对数据要求十分严苛的企业级系统,而适合日志之类并发量大但是允许少量的丢失或重复等场景 5.8 Notify、RocketMQ的事务设计 5.9 基于文件的kafka、RocketMQ和基于数据库的Notify和Hermes 5.10 设计一个消息系统要考虑哪些方面 5.11 丢失消息、消息重复、高可用等话题 3.6 数据库的分库分表mycat 3.7 NoSql数据库mongodb 3.8 KV键值系统memcached redis 8.1 redis对客户端的维护和管理,读写缓冲区 8.2 redis事务的实现 8.3 Jedis客户端的实现 8.4 JedisPool以及ShardedJedisPool的实现 8.5 redis epoll实现,循环中的文件事件和时间事件 8.6 redis的RDB持久化,save和bgsave 8.7 redis AOF命令追加、文件写入、文件同步到磁盘 8.8 redis AOF重写,为了减少阻塞时间采取的措施 8.9 redis的LRU内存回收算法 8.10 redis的master slave复制 8.11 redis的sentinel高可用方案 8.12 redis的cluster分片方案 3.9 web服务器tomcat、ngnix的设计原理 9.1 tomcat的整体架构设计 9.2 tomcat对通信的并发控制 9.3 http请求到达tomcat的整个处理流程 3.10 ELK日志实时处理查询系统 10.1 Elasticsearch、Logstash、Kibana 3.11 服务方面 11.1 SOA与微服务 11.2 服务的合并部署、多版本自动快速切换和回滚 详见基于Java容器的多应用部署技术实践 11.3 服务的治理:限流、降级 具体见 张开涛大神的架构系列 服务限流:令牌桶、漏桶 服务降级、服务的熔断、服务的隔离:netflix的hystrix组件 11.4 服务的线性扩展 无状态的服务如何做线性扩展: 如一般的web应用,直接使用硬件或者软件做负载均衡,简单的轮训机制 有状态服务如何做线性扩展: 如Redis的扩展:一致性hash,迁移工具 11.5 服务链路监控和报警:CAT、Dapper、Pinpoint 3.12 Spring Cloud 12.1 Spring Cloud Zookeeper:用于服务注册和发现 12.2 Spring Cloud Config:分布式配置 12.2 Spring Cloud Netflix Eureka:用于rest服务的注册和发现 12.3 Spring Cloud Netflix Hystrix:服务的隔离、熔断和降级 12.4 Spring Cloud Netflix Zuul:动态路由,API Gateway 3.13 分布式事务 13.1 JTA分布式事务接口定义,对此与Spring事务体系的整合 13.2 TCC分布式事务概念 13.3 TCC分布式事务实现框架案例1:tcc-transaction 13.3.1 TccCompensableAspect切面拦截创建ROOT事务 13.3.2 TccTransactionContextAspect切面使远程RPC调用资源加入到上述事务中,作为一个参与者 13.3.3 TccCompensableAspect切面根据远程RPC传递的TransactionContext的标记创建出分支事务 13.3.4 全部RPC调用完毕,ROOT事务开始提交或者回滚,执行所有参与者的提交或回滚 13.3.5 所有参与者的提交或者回滚,还是通过远程RPC调用,provider端开始执行对应分支事务的confirm或者cancel方法 13.3.6 事务的存储,集群共享问题13.3.7 事务的恢复,避免集群重复恢复 13.4 TCC分布式事务实现框架案例2:ByteTCC 13.4.1 JTA事务管理实现,类比Jotm、Atomikos等JTA实现 13.4.2 事务的存储和恢复,集群是否共享问题调用方创建CompensableTransaction事务,并加入资源 13.4.3 CompensableMethodInterceptor拦截器向spring事务注入CompensableInvocation资源 13.4.4 Spring的分布式事务管理器创建作为协调者CompensableTransaction类型事务,和当前线程进行绑定,同时创建一个jta事务 13.4.5 在执行sql等操作的时候,所使用的jdbc等XAResource资源加入上述jta事务 13.4.6 dubbo RPC远程调用前,CompensableDubboServiceFilter创建出一个代理XAResource,加入上述 CompensableTransaction类型事务,并在RPC调用过程传递TransactionContext参与方创建分支的CompensableTransaction事务,并加入资源,然后提交jta事务 13.4.7 RPC远程调用来到provider端,CompensableDubboServiceFilter根据传递过来的TransactionContext创建出对应的CompensableTransaction类型事务 13.4.8 provider端,执行时遇见@Transactional和@Compensable,作为一个参与者开启try阶段的事务,即创建了一个jta事务 13.4.9 provider端try执行完毕开始准备try的提交,仅仅是提交上述jta事务,返回结果到RPC调用端调用方决定回滚还是提交 13.4.10 全部执行完毕后开始事务的提交或者回滚,如果是提交则先对jta事务进行提交(包含jdbc等XAResource资源的提交),提交成功后再对CompensableTransaction类型事务进行提交,如果jta事务提交失败,则需要回滚CompensableTransaction类型事务。 13.4.11 CompensableTransaction类型事务的提交就是对CompensableInvocation资源和RPC资源的提交,分别调用每一个CompensableInvocation资源的confirm,以及每一个RPC资源的提交CompensableInvocation资源的提交 13.4.12 此时每一个CompensableInvocation资源的confirm又会准备开启一个新的事务,当前线程的CompensableTransaction类型事务已存在,所以这里开启事务仅仅是创建了一个新的jta事务而已 13.4.13 针对此,每一个CompensableInvocation资源的confirm开启的事务,又开始重复上述过程,对于jdbc等资源都加入新创建的jta事务中,而RPC资源和CompensableInvocation资源仍然加入到当前线程绑定的CompensableTransaction类型事务 13.4.14 当前CompensableInvocation资源的confirm开启的事务执行完毕后,开始执行commit,此时仍然是执行jta事务的提交,提交完毕,一个CompensableInvocation资源的confirm完成,继续执行下一个CompensableInvocation资源的confirm,即又要重新开启一个新的jta事务RPC资源的提交(参与方CompensableTransaction事务的提交) 13.4.15 当所有CompensableInvocation资源的confirm执行完毕,开始执行RPC资源的commit,会进行远程调用,执行远程provider分支事务的提交,远程调用过程会传递事务id 13.4.16 provider端,根据传递过来的事务id找到对应的CompensableTransaction事务,开始执行提交操作,提交操作完成后返回响应结束 13.4.17 协调者收到响应后继续执行下一个RPC资源的提交,当所有RPC资源也完成相应的提交,则协调者算是彻底完成该事务 3.14 一致性算法 14.1 raft(详见Raft算法赏析) 14.1.1 leader选举过程,leader选举约束,要包含所有commited entries,实现上log比过半的log都最新即可 14.1.2 log复制过程,leader给所有的follower发送AppendEntries RPC请求,过半follower回复ok,则可提交该entry,然后向客户端响应OK 14.1.3 在上述leader收到过半复制之后,挂了,则后续leader不能直接对这些之前term的过半entry进行提交(这一部分有详细的案例来证明,并能说出根本原因),目前做法是在当前term中创建空的entry,然后如果这些新创建的entry被大部分复制了,则此时就可以对之前term的过半entry进行提交了 14.1.4 leader一旦认为某个term可以提交了,则更新自己的commitIndex,同时应用entry到状态机中,然后在下一次与follower的heartbeat通信中,将leader的commitIndex带给follower,让他们进行更新,同时应用entry到他们的状态机中 14.1.5 从上述流程可以看到,作为client来说,可能会出现这样的情况:leader认为某次client的请求可以提交了(对应的entry已经被过半复制了),此时leader挂了,还没来得及给client回复,也就是说对client来说,请求虽然失败了,但是请求对应的entry却被持久化保存了,但是有的时候却是请求失败了(过半都没复制成功)没有持久化成功,也就是说请求失败了,服务器端可能成功了也可能失败了。所以这时候需要在client端下功夫,即cleint端重试的时候仍然使用之前的请求数据进行重试,而不是采用新的数据进行重试,服务器端也必须要实现幂等。 14.1.6 Cluster membership changes 14.2 ZooKeeper使用的ZAB协议(详见ZooKeeper的一致性算法赏析) 14.2.1 leader选举过程。要点:对于不同状态下的server的投票的收集,投票是需要选举出一个包含所有日志的server来作为leader 14.2.2 leader和follower数据同步过程,全量同步、差异同步、日志之间的纠正和截断,来保证和leader之间的一致性。以及follower加入已经完成选举的系统,此时的同步的要点:阻塞leader处理写请求,完成日志之间的差异同步,还要处理现有进行中的请求的同步,完成同步后,解除阻塞。 14.2.3 广播阶段,即正常处理客户端的请求,过半响应即可回复客户端。 14.2.4 日志的恢复和持久化。持久化:每隔一定数量的事务日志持久化一次,leader选举前持久化一次。恢复:简单的认为已写入日志的的事务请求都算作已提交的请求(不管之前是否已过半复制),全部执行commit提交。具体的恢复是:先恢复快照日志,然后再应用相应的事务日志 14.3 paxos(详见paxos算法证明过程) 14.3.1 paxos的运作过程: Phase 1: (a) 一个proposer选择一个编号为n的议案,向所有的acceptor发送prepare请求 Phase 1: (b) 如果acceptor已经响应的prepare请求中议案编号都比n小,则它承诺不再响应prepare请求或者accept请求中议案编号小于n的, 并且找出已经accept的最大议案的value返回给该proposer。如果已响应的编号比n大,则直接忽略该prepare请求。 Phase 2:(a) 如果proposer收到了过半的acceptors响应,那么将提出一个议案(n,v),v就是上述所有acceptor响应中最大accept议案的value,或者是proposer自己的value。然后将该议案发送给所有的acceptor。这个请求叫做accept请求,这一步才是所谓发送议案请求,而前面的prepare请求更多的是一个构建出最终议案(n,v)的过程。 Phase 2:(b) acceptor接收到编号为n的议案,如果acceptor还没有对大于n的议案的prepare请求响应过,则acceptor就accept该议案,否则拒绝 14.3.2 paxos的证明过程: 1 足够多的问题 2 acceptor的初始accept 3 P2-对结果要求 4 P2a-对acceptor的accept要求 5 P2b-对proposer提出议案的要求(结果上要求) 6 P2c-对proposer提出议案的要求(做法上要求) 7 引出prepare过程和P1a 8 8 优化prepare 14.3.3 base paxos和multi-paxos 4 大数据方向 4.1 Hadoop 1.1 UserGroupInformation源码解读:JAAS认证、user和group关系的维护 1.2 RPC通信的实现 1.3 代理用户的过程 1.4 kerberos认证 4.2 MapReduce 2.1 MapReduce理论及其对应的接口定义 4.3 HDFS 3.1 MapFile、SequenceFile 3.2 ACL 4.4 YARN、Mesos 资源调度 4.5 oozie 5.1 oozie XCommand设计 5.2 DagEngine的实现原理 4.6 Hive 6.1 HiveServer2、metatore的thrift RPC通信设计 6.2 Hive的优化过程 6.3 HiveServer2的认证和授权 6.4 metastore的认证和授权 6.5 HiveServer2向metatore的用户传递过程 4.7 Hbase 7.1 Hbase的整体架构图 7.2 Hbase的WAL和MVCC设计 7.3 client端的异步批量flush寻找RegionServer的过程 7.4 Zookeeper上HBase节点解释 7.5 Hbase中的mini、major合并 7.6 Region的高可用问题对比kafka分区的高可用实现 7.7 RegionServer RPC调用的隔离问题 7.8 数据从内存刷写到HDFS的粒度问题 7.9 rowKey的设计 7.10 MemStore与LSM
架构管控项目一个;开发维护项目一个;新开发项目一个;维保项目一个;
针对自己参与的项目,下面列出三个月来我涉及的一些技术栈、业务栈及工具栈概述:
1、技术栈:
Java:
SSM(Spring + Spring MVC + Mybatis):
Spring:
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架;
Spring MVC:
Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制;
Mybatis:
MyBatis是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO)MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的 XML或注解用于配置和原始映射,将接口和 Java 的POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录;
Java基础
多线程、Future、Callable
内部类、闭包和回调
并发、Executor
Apache Commons CLI 开发命令行工具
JVM:
类加载机制;
线程安全;
垃圾回收机制——新生代、老年代、永久代,能够对需要执行的程序配置相关参数;
JAVA堆;
HaaS:统一Hadoop资源池平台,基于Hadoop等大数据技术,提供统一数据存储、计算能力
HDFS(Hadoop Distributed File System):海量数据存储
存储并管理PB级数据;
处理非结构化数据;
注重数据处理的吞吐量;
应用模式Write_Once_Read_Many;
YARN(Yet Another Resource Negotiator):统一资源调度和分配
ResourceManager:负责集群资源管理和调度;
ApplicationMaster:替代JobTracker负责计算任务的管理和调度;
Nodemanager:替代TaskTracker负责每个节点上计算Task的管理和调度;
MapReduce:非结构化、半结构化数据的海量批处理
Map:映射,用来把一组键值对映射成一组新的键值对;
Reduce:归约,用来保证所有映射的键值对中的每一个共享相同的键组,并进行聚合计算;
核心思想:
利用成百上千个CPU并行处理海量数据;
移动计算比移动数据更划算;
Spark:分布式内存计算框架
Spark是一种与Hadoop相似的开源集群计算环境,Spark使用了内存内运算技术,能在数据尚未写入硬盘时即在内存内分析运算,而相对于传统的大数据解决方案Hadoop的MapReduce会在运行完工作后将中介数据存放在磁盘中,Spark在内存内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍;
Spark Streaming:实时/准实时流的计算框架
Spark Streaming将数据划分为一个一个的数据块(batch),每个数据块通过微批处理的方式对数据进行处理,在Spark Streaming中,数据处理的单位是一批而不是单条,而数据采集确是逐条进行的,因此Spark Streaming系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是Spark Streaming的核心概念和关键参数,它决定了Spark Streaming提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能;
HBase:Key/Value、半结构化数据的海量存储和检索
分布式的、面向列的开源数据库;
Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和故障转移机制。这使得HBase可以用于支撑亿级的海量数据存储和应用;
Hive:结构化数据的查询和分析
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行;
Hive擅长的是非实时的、离线的、对响应实时性要求不高的海量数据即席查询(SQL查询);
Hive和传统关系型数据库有很大区别,Hive将外部的任务解析成一个MapReduce可执行计划,每次提交任务和执行任务都需要消耗很多时间(可以换用Tez计算框架来提升性能),这也就决定Hive只能处理一些高延迟的应用。
Zookeeper:分布式协同工具
Zookeeper是利用Paxos算法解决消息传递一致性的分布式服务框架;
Zookeeper通过部署多台机器,能够实现分布式的负载均衡的访问服务。不同的Client向Zookeeper中不同机器请求数据;
为了实现集群中配置数据的增删改查保证一致性问题,需要有主节点,由主节点来做出修改的动作,并同步到其它节点上面;
当主节点出现故障时,将在其他节点中自动通过一定的选举方法选举出新的主节点;
Oozie:任务调度工具
Oozie是Hadoop平台的一种工作流调度引擎,Oozie是一种Java Web应用程序,它运行在Java Servlet容器(Tomcat),并使用数据库来存储以下内容:
工作流定义;
当前运行的工作流实例,包括实例的状态和变量;
Oozie工作流是放置在控制依赖DAG中的一组动作,其中指定了动作执行的顺序;
Ambari:可视化集群管理工具
部署、启动、监控、查看、关闭Hadoop集群,可视化监控、运维、告警;
Ambari主要由两部分组成:
Ambari Server;
Ambari Client;
用户通过Ambari Server通知Ambari Agent安装对应的软件,Ambari Agent会定时地发送各个机器每个软件模块的状态给Ambari Server,最终这些状态信息会呈现在Ambari的GUI,方便用户了解到集群的各种状态,并进行相应的维护;
Kafka:分布式消息总线
Kafka是一个低延迟高吞吐的分布式消息队列,适用于离线和在线消息消费,用于低延迟地收集和发送大量的事件和日志数据;
消息队列(Message Queue)用于将消息生产的前端和后端服务架构解耦,它是一种pub-sub结构,前端消息生产者不需要知道后端消息消费者的情况,只需要将消息发布到消息队列中,且只用发布一次,即可认为消息已经被可靠存储了,不用再维护消息的一致性和持久化,同时消息只传输一次就可以给后端多个消费者,避免了每个消费者都直接去前端获取造成的前端服务器计算资源和带宽的浪费,甚至影响生产环境;
消息队列分为以下几种角色:
Producer:生产者,即消息生产者,比如实时信令数据;
Consumer: 消费者,即消息的消费者,比如后端的实时统计程序和批量挖掘程序;
Consumer Group:消费者组,即消费者的并发单位,在数据量比较大的时候,需要分布式集群来处理消息,针对同一种消息,一组消费者各自消费某一Topic(话题,代表一些消息,Topic 是一个逻辑单位,一个 Topic 被划分成 N 个 Partition,在数据量大的时候通过 Partition 来实现分布式传输)的一部分,来协作处理;
Broker:存储节点,Kafka支持将消息进行短暂的持久化,比如存储最近一周的数据,以便下游集群故障时,重新订阅之前丢失的数据。
在Kafka中,Producer自动通过Zookeeper获取到Broker列表,通过Partition算法自动负载均衡将消息发送到Broker集群。Broker 收到消息后自动分发到副本 Broker 上保证消息的可靠性。下游消费者通过 Zookeeper获取Broker集群位置和Topic等信息,自动完成订阅消费等动作。
Kerberos & Ranger:安全加固
Kerberos:
通过密钥系统为客户机/服务器应用程序提供强大的认证服务;
Apache Ranger:
集中式安全管理框架,并解决授权和审计;
身份验证(Authentication):基于Kerberos的用户、服务身份验证;
统一账户(Account):使用统一应用账号访问平台众多服务;
访问授权(Authorization):基于Ranger的精细粒度访问权限;
操作审计(Audit):基于Ranger的集中式审计日志;
DBaaS:开箱即用的关系型数据库服务
MySQL高可用:
主从复制:
一主一从 + Keepalived + VRRP((Virtual Router Redundancy Protocol,虚拟路由冗余协议):
Keepalived:
Keepalived是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
VRRP:
解决静态路由单点故障问题,VRRP通过一竞选(election)协议来动态的将路由任务交给LAN中虚拟路由器中的某台VRRP路由器。
采用一主一从构建高可用MySQL服务,当主机宕机时,可以自动触发主从节点切换。通过使用VIP + Keepalived组件,实现主从切换时MySQL服务IP自动漂移,主从库自动切换。
MHA(一主一从一只读) + Keepalived + VRRP:
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
CssS:提供标准化的容器技术和容器管理方案,支撑无状态应用的标准化打包和部署
Docker:开源应用容器引擎
Docker是Docker公司开源的一个基于轻量级虚拟化技术的容器引擎项目,整个项目 基于 Go 语言开发,并遵从 Apache 2.0 协议;
当前,Docker可以在容器内部快速自动化部署应用,并可以通过内核虚拟化技术 (namespaces及cgroups等) 来提供容器的资源隔离与安全保障等;
Docker通过操作系统层的虚拟化实现隔离,所以Docker容器在运行时,不需要类似 虚拟机(VM)额外的操作系统开销,提高资源利用率,并且提升诸如I/O等方面的性能;
Docker彻底释放了虚拟化的潜力和威力,极大降低了云计算资源供应的成本,同时让业务应用的开发、测试、部署都变得前所未有敏捷、高效和轻松;
Kubernetes:容器集群管理系统
Kubernetes是Google开源的容器集群管理系统,其提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,其主要功能如下:
使用Docker对应用程序包装(package)、实例化(instantiate)、运行(run);
以集群的方式运行、管理跨机器的容器;
解决Docker跨机器容器之间的通讯问题;
Kubernetes的自我修复机制使得容器集群总是运行在用户期望的状态;
DevOps:开发运维一体化
第一阶段:核心实践和试点;
第二阶段:持续集成和测试;
第三阶段:持续部署和交付;
第四阶段:持续运维;
第五阶段:持续评估改进;统一日志服务:提供多租户安全的系统、应用海量日志分析、交互式查询和可视化
核心能力:
规划构建的统一日志平台核心能力包括:
多租户安全:支持多租户端到端业务日志的存储、分析、可视化能力,支持多租户数据安全;
分析挖掘能力:通过Elasticsearch的结构化查询,实现复杂的多维度联合查询及数据聚合,深度挖掘日志数据;
可视化能力:支持图表可视化呈现分析结果,支持Dashboard实时监控关键指标;
Filebeat:
轻量级的日志采集器,部署于应用侧,负责实时采集日志;
Logstash:
负责日志解析和转发,灵活的正则配置可同时处理不同数据结构的日志,并写入Elasticsearch不同索引;
Kafka:
分布式消息队列,在Filebeat和Logstash中引入分布式消息队列Kafka,可以从容的应对峰值数据的高负载,并且在Logstash出现故障时,具备良好的恢复能力,可直接从Kafka做数据回放,避免回溯至若干上游应用;
Elasticsearch:
负责日志(原始数据、分析数据)的存储、索引和搜索,是实时分析数据流程的核心组件;
Kibana:
前端可视化工具,Elasticsearch的皮肤,结合Elasticsearch丰富的查询逻辑,可定制多种图表;
Linux命令行:
FTP、不同服务器之间、服务器与本地上传/下载、进程监控、内存监控、JVM监控、打包部署、Vim编辑、文件授权、审阅日志文件等等;
Bash脚本开发:
能够阅读并编写简单的脚本;
Python:
能够阅读一般的Python脚本,深入后可学习爬虫;
机器学习算法:
逻辑回归算法;
基于特征的推荐算法;
分类算法;
聚类算法;
2、工具栈:
版本管理工具:Git,SVN;
JAVA开发IDE:Intellij IDEA;
项目构建工具:Maven;
文本编辑器:Subline、NotePad等;
数据库管理工具:Navicat、SQLite Free等;
终端仿真程序:SecureCRT、Xshell5等;
3、业务栈:
Tower化记录:
做好任务的Tower化记录,包括:
需求由来;
任务的具体描述;
解决问题的过程中关键细节记录;
抄送给相关的项目负责人,并给出制定出解决问题的时间;
任务结论及相关解决方案文件的上传;
CPS工作清单:
对于维护过程中出现的每一个相关问题,应养成记录的良好习惯,方便未来进行整理和排查。因此建立DMP项目维护工作清单,对于维护项的类别、详细描述、维护时间、维护耗时、处理结果、维护相关人员及对应的Tower任务链接进行记录;
现有任务梳理:
梳理遗留任务清单并标注优先级;
评估还需要多少人天可以完成问题及Bug;
评估未来的运维(不含新需求)每周需要投入的人力;