本文大纲:
• prometheus metrics的概念
• k/v的数据形式
• prometheus exporter的使⽤(pull形式采集数据)
• prometheus pushgateway的⼊门介绍(push形式采集数据)
1)prometheus metrics的概念
promethes监控中对于采集过来的数据统⼀称为metrics数据
当我们需要为某个系统某个服务做监控、做统计,就需要⽤到Metrics。
metrics是⼀种对采样数据的总称(metrics 并不代表某⼀种具体的数据格式 是⼀种对于度量计算单位的抽象 )
咱们来介绍⼀下 metrics 的⼏种主要的类型
Gauges
最简单的度量指标,只有⼀个简单的返回值,或者叫瞬时状态,例如,我们想衡量⼀个待处理队列中任务的个数、
⽤更简单的⽅式举个例⼦
例如 : 如果我要监控硬盘容量或者内存的使⽤量,那么就应该使⽤Gauges的metrics格式来度量
因为硬盘的容量或者内存的使⽤量是随着时间的推移不断的瞬时没有规则变化的
这种变化没有规律,当前是多少,采集回来的就是多少 5:00 21%。5:01 25% , 5:02 17%
既不能肯定是 ⼀只持续增⻓ 也不能肯定是⼀直降低
是多少 就是多少 这种就是Gauges使⽤类型的代表
如图所示 CPU的上下浮动就是采集使⽤Gauge形式的 metrics数据 没有规律 是多少就得到多少然后显示出来 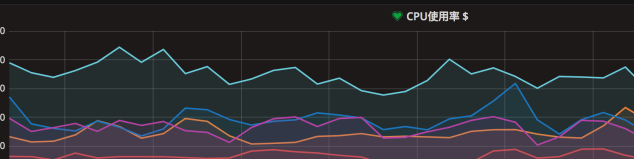
Counters 类型metris
Counter就是计数器,从数据量0开始累积计算 在理想状态下只能是永远的增⻓不会降低
Counter => 数字 +++ 2:00 => 0 prometheus
举个例⼦来说
⽐如对⽤户访问量的采样数据
我们的产品被⽤户访问⼀次就是1 过了10分钟后 积累到 100
过⼀天后 积累到 20000
⼀周后 积累到 100000-150000
如下图展示的Counter数据 是从0开始⼀直不断的积累,累加下去的 所以理想状态下 不可能出现任何降低的状况
最多只可能是 ⼀直保持不变(例如 ⽤户不再访问了,那么当前累积的总访问量 会以⼀条水平线的状态保持下去 直到 再被访问)
如下图展示的 就是⼀个counter类型的metrics数据采集。 采集的是 ⽤户的访问累积量 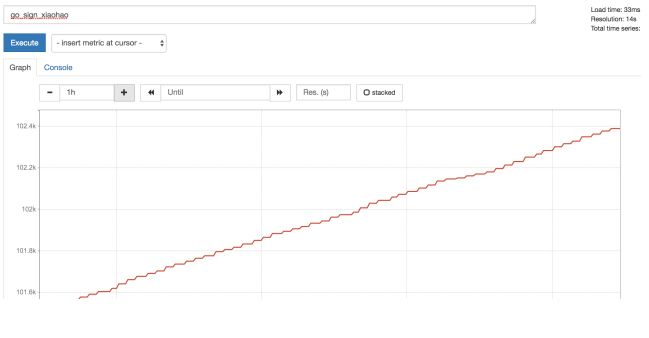
Histograms
Histogram统计数据的分布情况。⽐如最⼩值,最⼤值,中间值,还有中位数,75百分位, 90百分位, 95百分位, 98百分位, 99百分位, 和 99.9百分位的值(percentiles)。
这是⼀种特殊的 metrics数据类型 , 代表的是⼀种近似的百分⽐估算数值
⽐如我们在企业⼯作中 经常接触这种数据
Http_response_time HTTP响应时间
代表的是 ⼀次⽤户HTTP请求 在系统传输和执⾏过程中 总共花费的时间
nginx中的 也会记录这⼀项数值 在⽇志中
那么问题来了
我们做⼀个假设
如果我们想通过监控的⽅式 抓取当天的nginx access_log ,并且想监控⽤户的访问时间
我们应该怎么做呢?
把⽇志每⾏的 http_response_time 数值统统采集下来啊 然后计算⼀下总的平均值即可
那么⼤⽶要问⼤家⼀句了 假如我们采集到 今天⼀天的访问量 是100万次
然后把这100万次的 http_response_time 全都加⼀起 然后 除以100万 最后得出来⼀个avg值
0.05秒 = 50毫秒
这个数据的意义⼤么?
假如 今天中午1:00的时候 发⽣了⼀次线上故障 系统整体的访问变得⾮常缓慢 ⼤部分的⽤户
请求时间都达到了 0.5~1秒作⽤
但是这⼀段时间 只持续了5分钟, 总的⼀天的平均值并不能表现得出来 我们如何在1:00-
1:05的时候 实现报警呢?
在举个例⼦:
就算我们⼀天下来 线上没有发⽣故障 ⼤部分⽤户的响应时间 都在 0.05秒(通过 总时间/总
次数得出)
但是我们不要忘了 任何系统中 都⼀定存在 慢请求 就是有⼀少部分的⽤户 请求时间会⽐总
的平均值⼤很多 甚⾄接近 5秒 10秒的也有
(这种情况很普遍 因为各种因素 可能是软件本⾝的bug 也可能是系统的原因 更有可能是少
部分⽤户的使⽤途径中出现了问题)
那么我们的监控需要 发现和报警 这种少部分的特殊状况,⽤总平均能获得吗?
如果采⽤总平均的⽅式,那不管发⽣什么特殊情况,因为⼤部分的⽤户响应都是正常的 你
永远也发现不了少部分的问题
所以 Histogram的metrics类型 在这种时候就派上⽤场了
通过histogram类型(prometheus中 其实提供了⼀个 基于histogram算法的 函数 可以直接使
⽤)
可以分别统计出 全部⽤户的响应时间中
~=0.05秒的 量有多少 0 ~ 0.05秒的有多少, > 2秒的有多少 >10秒的有多少 => 1%
我们就可以很清晰的看到 当前我们的系统中 处于基本正常状态的有多少百分⽐的⽤户(或
者是请求)
多少处于速度极快的⽤户, 多少处于慢请求或者有问题的请求
metrics的类型其实还有另外的类型
但是在我们⼤⽶运维的课程中 我们最主要使⽤的 就是 counter ganga 和 histogram
2) k/v的数据形式
prometheus 的数据类型就是依赖于这种 metris的类型来计算的
⽽对于采集回来的数据类型再往细了说必须要以⼀种具体的数据格式供我们查看和使⽤
那么我们来看⼀下⼀个exporter 给我们采集来的 服务器上的k/v形式 metrics数据
当⼀个exporter(node_exporter) 被安装和运⾏在 被监控的服务器上后
使⽤简单的 curl命令 就可以看到 exporer帮我们采集到 metrics数据的样⼦ , 以 k / v 的形式展现和保存
curl localhost:9100/metrics 
如上图所⽰ curl之后的结果输出
prometheus_server
带# 的⾏ 是注释⾏ ⽤来解释下⾯这⼀项 k / v 数值 是什么东东的采样数据
⽽ 我们真正关⼼的 是这样的 数据 


看到了没有 就是⽤空格分开的 KEY / Value 数据
第⼀个代表的是 当前采集的 最⼤⽂件句柄数 是 65535
第⼆个代表的是 当前采集的 被打开的⽂件句柄数是: 10
这样就⾮常好理解了
另外 我们在看下这⾥ 
第⼆⾏的 # 告诉我们了 这⼀项数据的metrics类型 属于gauge
因为很简单, ⽂件句柄数的使⽤ 是没有规律的瞬时采样数据 当前是多少就是多少
3) exporter的使⽤
官⽹提供了丰富的 成型 exportrs插件可以使⽤
举⼏个例⼦

下载⾸页 其实就已经提供了 很多 很常⽤的 exporters
这些exporters 分别使⽤不同的开发语⾔开发,有 go 有 Java 有python 有ruby 等等
我们不关⼼社区组织 ⽤什么语⾔做的开发
我们只要关⼼ 如何下载和正确安装使⽤ 即可
⼤多数exporters 下载之后,就提供了启动的命令 ⼀般直接运⾏ 带上⼀定的参数就可以了
⽐如 最常⽤的 node_exporter =》 这个exporter⾮常强⼤,⼏乎可以把 Linux系统中 和系统⾃
⾝相关的监控数据 全抓出来了(很多参数 说真的 都没听说过 ⽐你想象的 学过的 多的多)
这⾥只给⼤家⼀个截图 展⽰node_exporter⼀部分的 ⽀持的监控数据采集
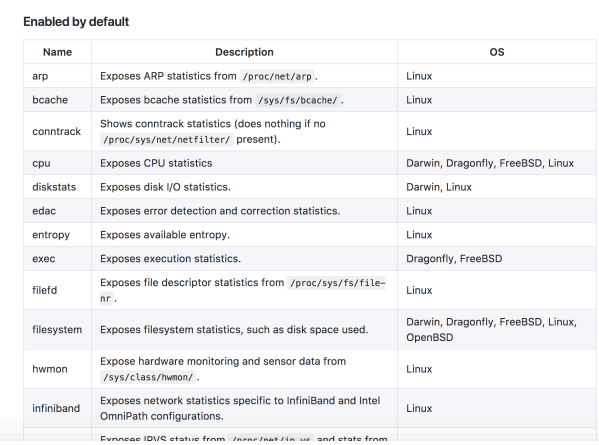

每⼀项 其实还有N多的⼦项, 该有的数据都有了,不该有的 不重要的 基本也有了 应有尽有
咱们还需要 ⾃⼰开发采集exporter吗? 其实不怎么需要了 直接⽤就好了
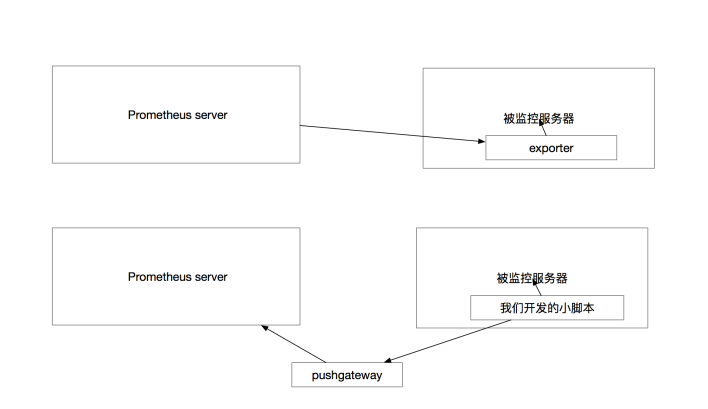
4) pushgateway 的概念介绍
之前说的 exporter 是⾸先安装在被监控服务器上运⾏在后台
然后⾃动采集系统数据 , 本⾝又是⼀个 HTTP_server 可以被prometheus服务器定时去HTTP GET取得数据
属于pull的形式
如果把这个过程反过来
push的形式是把pushgateway安装在客户端或者服务端(其实装哪⾥都⽆俗谓)
pushgateway本⾝也是⼀个http服务器
运维通过写⾃⼰的脚本程序抓⾃⼰想要的监控数据然后推送到 pushgateway(HTTP) 再由pushgateway推送到 prometheus服务端
是⼀个反过来的被动模式
为什么已经有了那么强⼤的 pull 形式的node_exporter采集还需要⼀个pushgateway的形式呢?
其实对这个问题的回答是:
• exporter虽然采集类型已经很丰富了,但是我们依然需要很多⾃制的监控数据⾮规则化的⾃定制的
• exporter 由于数据类型采集量⼤,其实很多数据或者说⼤部分数据其实我们监控中真的⽤不到,⽤pushgateway是定义⼀项数据就采集着⼀种节省资源
• ⼀个新的⾃定义的pushgateway脚本开发远远⽐开发⼀个全新的exporter 简单快速的多的多的多! (exporter的开发需要使⽤真正的编程语⾔ ,shell这种快速脚本是不
⾏的⽽且需要了解很多 prometheus⾃定的编程格式才能开始制作⼯作量很⼤)
• exporter虽然已经很丰富了,但是依然有很多的我们需要的采集形式, exporter⽆法提供,或者说 现有的expoter还不⽀持,但是如果使⽤pushgateway的形式 就可以任意灵活,想做什么都可以做到⽽且极快
最后 ⽤⼀张图 来⽴刻这两种不同的 采集形式