本文大纲:
• Prometheus 官⽹下载
• Prometheus 开始安装
• Prometheus 启动运⾏
• Prometheus 基本配置⽂件讲解
• 安装第⼀个exporter =》 node_exporter
• Prometheus 连接exporter获取数据
• Prometheus 命令⾏⼊门第⼀个查询公式
安装Prometheus之前 我们必须先安装ntp时间同步
(prometheus对系统时间的准确性要求很⾼,必须保证本机时间实时同步)
以Centos7 为例
~]# timedatectl set-timezone Asia/Shanghai ~]# contab -e * * * * * ntpdate -u cn.pool.ntp.org
1) Prometheus下载
⾸先 我们去到http://prometheus.io 官⽹
下载最新版本 prometheus-2.2.1.linux-amd64.tar.gz
wget https://github.com/prometheus/prometheus/releases/download/v2.2.1/prometheus-2.2.1.linux-amd64.tar.gz
2) Prometheus的安装 ⾮常简单
[root@server01 download]# tar -xvzf prometheus-2.0.0.linux-amd64.tar.gz prometheus-2.0.0.linux-amd64/ prometheus-2.0.0.linux-amd64/consoles/ prometheus-2.0.0.linux-amd64/consoles/index.html.example prometheus-2.0.0.linux-amd64/consoles/node-cpu.html prometheus-2.0.0.linux-amd64/consoles/node-disk.html prometheus-2.0.0.linux-amd64/consoles/node-overview.html prometheus-2.0.0.linux-amd64/consoles/node.html prometheus-2.0.0.linux-amd64/consoles/prometheus-overview.html prometheus-2.0.0.linux-amd64/consoles/prometheus.html prometheus-2.0.0.linux-amd64/console_libraries/ prometheus-2.0.0.linux-amd64/console_libraries/menu.lib prometheus-2.0.0.linux-amd64/console_libraries/prom.lib prometheus-2.0.0.linux-amd64/prometheus.yml prometheus-2.0.0.linux-amd64/LICENSE prometheus-2.0.0.linux-amd64/NOTICE prometheus-2.0.0.linux-amd64/prometheus prometheus-2.0.0.linux-amd64/promtool cp -rf prometheus-2.0.0.linux-amd64 /usr/local/prometheus
3) Prometheus 启动 和 后台运⾏
启动也很简单
~]# ./prometheus level=info ts=2018-05-10T07:34:01.397792062Z caller=main.go:220 msg="Starting Prometheus" version="(version=2.2.1, branch=HEAD , revision=bc6058c81272a8d938c05e75607371284236aadc)"level=info ts=2018-05-10T07:34:01.397842176Z caller=main.go:221 build_context="(go=go1.10, user=root@149e5b3f0829, date=201803 14-14:15:45)"level=info ts=2018-05-10T07:34:01.397855314Z caller=main.go:222 host_details="(Linux 3.10.0-327.el7.x86_64 #1 SMP Thu Nov 19 2 2:10:57 UTC 2015 x86_64 node1 (none))"level=info ts=2018-05-10T07:34:01.397868136Z caller=main.go:223 fd_limits="(soft=1024, hard=4096)" level=info ts=2018-05-10T07:34:01.40145866Z caller=main.go:504 msg="Starting TSDB ..." level=info ts=2018-05-10T07:34:01.416327032Z caller=web.go:382 component=web msg="Start listening for connections" address=0.0 .0.0:9090level=info ts=2018-05-10T07:34:01.795931346Z caller=main.go:514 msg="TSDB started" level=info ts=2018-05-10T07:34:01.79597709Z caller=main.go:588 msg="Loading configuration file" filename=prometheus.yml level=info ts=2018-05-10T07:34:01.847028303Z caller=main.go:491 msg="Server is ready to receive web requests."
之后默认运⾏在 9090
浏览器可以直接打开访问⽆账号密码验证 (如果希望加上验证 ,可以使⽤类似apache httppass ⽅式添加)
4)接下来 我们来简单看⼀下 Prometheus的主配置⽂件
其实prometheus解压安装之后,就默认⾃带了⼀个基本的配置⽂件如下
prometheus.yml
我们来⼤致讲解⼀下配置⽂件的内容
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). 前两个全局变量 scrape_interval. 抓取采样数据的 时间间隔, 默认 每15秒去被监控机上 采样⼀次 => 5s 这个就是我们所说的 prometheus的⾃定义 数据采集频率了 evaluation_interval. 监控数据规则的评估频率 grafana 这个参数是prometheus多长时间 会进⾏⼀次 监控规则的评估 举个例: 假如 我们设置 当 内存使⽤量 > 70%时 发出报警 这么⼀条rule(规则) 那么prometheus 会默认 每15秒来执⾏⼀次这个规则 检查内存的情况 # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 Alertmanager 是prometheus的⼀个⽤于管理和发出报警的 插件 我们这⾥对 Alertmanger 暂时先不做介绍 暂时也不需要 (我们采⽤ 4.0最新版的 Grafana , 本 ⾝就已经⽀持报警发出功能了 往后我们会学习到) 再往后 从这⾥开始 进⼊prometheus重要的 配置采集节点的设置 # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] 先定义⼀个 job的名称
- job_name: 'prometheus' 然后定义监控节点 targets
static_configs:
- targets: ['localhost:9090'] - targets的设定 以这种形式设定 默认带了⼀个 prometheus本机的 static_configs: - targets: ['localhost:9090'] 这⾥可以继续 扩展加⼊ 其他需要被监控的节点 如下是⼀个 ⽣产配置例⼦ - job_name: 'aliyun' static_configs: - targets: [‘server04:9100’,'IP:9100’,’nginx06:9100','web7:9100’,'redis1:9100','log: 9100','redis2:9100'] prometheuserver _ /etc/hosts, local_dns server 可以看到 targets可以并列写⼊ 多个节点 ⽤逗号隔开, 机器名+端⼜号 端⼜号:通常⽤的就是 exporters 的端⼜ 在这⾥ 9100 其实是 node_exporter 的默认端⼜ 如此 prometheus就可以通过配置⽂件 识别监控的节点,持续开始采集数据 prometheus到此就算初步的搭建好了
5) 光搭建好prometheus_server 是不够的,我们需要给监控节点搭建第⼀个exporter ⽤来采样数据
我们就选⽤企业中最常⽤的 node_exporter 这个插件
node_exporter 是⼀个以http_server⽅式运⾏在后台,并且持续不断采集 Linux系统中各种操作系统本⾝相关的监控参数的程序
其采集量是很⼤很全的,往往默认的采集项⽬就远超过你的实际需求
接下来我们来看下 node_exporter是怎么回事
⼀样先下载node_exporter 从官⽹
wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0-rc.3/node_exporter-0.16.0-rc.3.linux-amd64.tar.gz
下载之后解压缩然后直接运⾏即可
node_exporter的运⾏更加简单如下所示
~]# ./node_exporter INFO[0000] Starting node_exporter (version=0.16.0-rc.3, branch=HEAD, revision=575d8950d367987ab8792e90fb2cf00c3fee1c10) source="node_exporter.go:82" INFO[0000] Build context (go=go1.9.5, user=root@d986ef46b6d6, date=20180427-15:51:15) source="node_exporter.go:83" INFO[0000] Enabled collectors: source="node_exporter.go:90" INFO[0000] - arp source="node_exporter.go:97" INFO[0000] - bcache source="node_exporter.go:97" INFO[0000] - bonding source="node_exporter.go:97" INFO[0000] - conntrack source="node_exporter.go:97" INFO[0000] - cpu source="node_exporter.go:97" INFO[0000] - diskstats source="node_exporter.go:97" INFO[0000] - edac source="node_exporter.go:97" INFO[0000] - entropy source="node_exporter.go:97" INFO[0000] - filefd source="node_exporter.go:97" INFO[0000] - filesystem source="node_exporter.go:97" INFO[0000] - hwmon source="node_exporter.go:97" INFO[0000] - infiniband source="node_exporter.go:97" INFO[0000] - ipvs source="node_exporter.go:97" INFO[0000] - loadavg source="node_exporter.go:97" INFO[0000] - mdadm source="node_exporter.go:97" INFO[0000] - meminfo source="node_exporter.go:97" INFO[0000] - netdev source="node_exporter.go:97" INFO[0000] - netstat source="node_exporter.go:97" INFO[0000] - nfs source="node_exporter.go:97" INFO[0000] - nfsd source="node_exporter.go:97" INFO[0000] - sockstat source="node_exporter.go:97" INFO[0000] - stat source="node_exporter.go:97" INFO[0000] - textfile source="node_exporter.go:97" INFO[0000] - time source="node_exporter.go:97" INFO[0000] - timex source="node_exporter.go:97" INFO[0000] - uname source="node_exporter.go:97" INFO[0000] - vmstat source="node_exporter.go:97" INFO[0000] - wifi source="node_exporter.go:97" INFO[0000] - xfs source="node_exporter.go:97" INFO[0000] - zfs source="node_exporter.go:97" INFO[0000] Listening on :9100 source="node_exporter.go:111"
运⾏起来以后 我们使⽤netstats -tnlp 可以来看下 node_exporter进程的状态
~]# netstat -tnlp | grep node tcp6 0 0 :::9100 :::* LISTEN 21886/./node_export
这⾥就可以看出 node_exporter默认⼯作在9100端⼜
可以响应 prometheus_server发过来的 HTTP_GET请求
也可以响应其他⽅式的 HTTP_GET请求
我们⾃⼰就可以发送 测试
执⾏curl之后,我们看到 node_exporter 给我们返回了 ⼤量的这种 metrics类型 K/V数据
~]# curl localhost:9100/metrics
关于 metrics 和 k/v 这里就不介绍了
⽽这些 返回的 K/V数据 ,其中的Key的名称就可以直接复制黏贴在prometheus的查询命令⾏来查看结果了
我们来试⼀试
就⽤这⼀项看看 node_memory_MemFree
# curl localhost:9100/metrics | grep node_memory_MemFree
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 52834 100 52834 0 0 4765k 0 --:--:-- --:--:-- --:--:-- 5159k
# HELP node_memory_MemFree_bytes Memory information field MemFree_bytes.
# TYPE node_memory_MemFree_bytes gauge
node_memory_MemFree_bytes 7.376896e+07
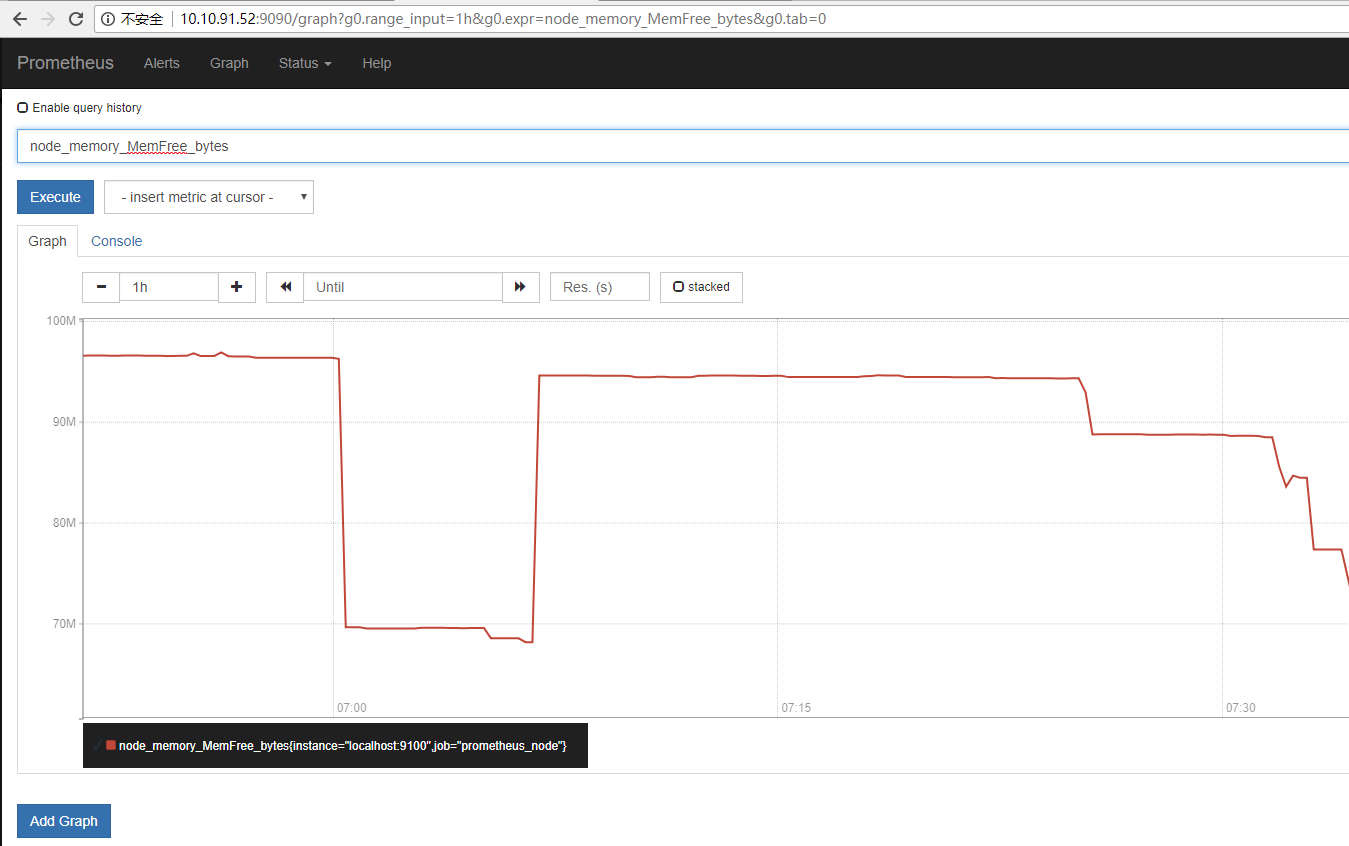
直接就可以看到曲线了
这个就是最简单的来查看⼀下服务器的空闲内存状态的⽅式