编码,首先对计算机来说,他的基层只能识别0,1二进制信息,字节是计算机的最小处理单元,一字节占用8位,也就是说在计算机中最小可以处理 8 位的二进制数。同时,在计算机上存储的数据也是以字节为单位的信息,在读取计算机上的信息时就是读取的二进制的这些0、1组成的数字信息。
所以为了能让计算机识别更多的数据,就出现了Ascii、UTF-8、GBK以及Unicode 等编码类型的标准码来翻译成计算机能识别的二进制数。
接下来来了解一下这些编码:
-
ASCAII码:
ASCII码 表示127个英文字符 每个中文需要使用两个字节来编码,中文编码的规则 —— GB2312 由于不同国家有不同的编码规则,如日本,韩国都使用各自国家的 编码规则,在多语言混用的场合会出现混乱。 -
UTF-8码:
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字 节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生 僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文 字符,用UTF-8编码就能节省空间。 UTF-8的一个好处在于,原有的ASCII的编码可以在UTF-8下继续工 作。 -
GBK码:
GBK编码,是对GB2312编码的扩展,因此完全兼容GB2312-80标准。GBK编码依然采用双字节编码方案,其编码范围:8140-FEFE,剔除xx7F码位,共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。GBK编码支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年12月15日正式发布,这一版的GBK规范为1.0版。 -
Unicode码 :
Unicode 用来把所有语言都统一到一套编码里,这样就不会再有乱 码问题了。Unicode 通常用两个字节编码(有的也用四个字节),而 ASCII码通常用一个字节字节。ASCII码转换成Unicode在前面一个字节 补0
所以在进行文件操作的时候要涉及编码还有解码,在python3中用**encode()来编码,用decode()**来解码。
编码(encode):将Unicode字符串(中的代码点)转换特定字符编码对应的字节串的过程和规则
解码(decode):将特定字符编码的字节串转换为对应的Unicode字符串(中的代码点)的过程和规则
通过了解,编码过程为:
人类的字符 ===> 翻译 ===> 数字(数字说的就是计算机能读懂的语言)
我们要保证不乱吗的核心法则就是,文件是以什么标准编码的,就以什么格式读取。
所以之前遇到很多次tomcat配置啊,数据库配置啊,都有编码问题而出现控制台乱码问题,问题出在编码问题上,需要更改配置。
接下来看看pycharm中使用python3的文件操作:
新建一个文件

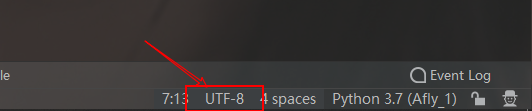
默认编码格式是utf-8:
打开文件:
f = open(r'B:pythonAfly_1lianxia','r').read() print(f)
以gbk编码打开

运行报错

改为utf-8

正常运行
