之前了解到网络编程的其他协议,今天来看看我们常见的http协议:
http协理解
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使 用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口 (默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上 存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或 者隧道(tunnel)。 尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用它或它支持 的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议 提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在 TCP/IP协议族使用TCP作为其传输层。 通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP 连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返 回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者 其它信息。
就简单来理解我们在上网时候需要用它来作为我们网站的门,它有一些规定,你得输入正确的格式才能访问网站,比如在浏览器输入框输入http://www.baidu.com,其实http协议后面还跟的是80端口,只是默认省略了,然后结合之前我们的了解,它其实是与服务端建立了一个tcp套接字连接,然后再让服务器给你资源。
看看具体步骤:
- 客户端连接到Web服务器 一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP 套接字连接。例如,http://www.luffycity.com。
- 发送HTTP请求 通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求 行、请求头部、空行和请求数据4部分组成。
- 服务器接受请求并返回HTTP响应 Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读 取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
- 释放连接TCP连接 若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP 连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接 收请求;
- 客户端浏览器解析HTML内容 客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应 头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据 HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。 例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;
- 浏览器将该 html 文本并显示内容;
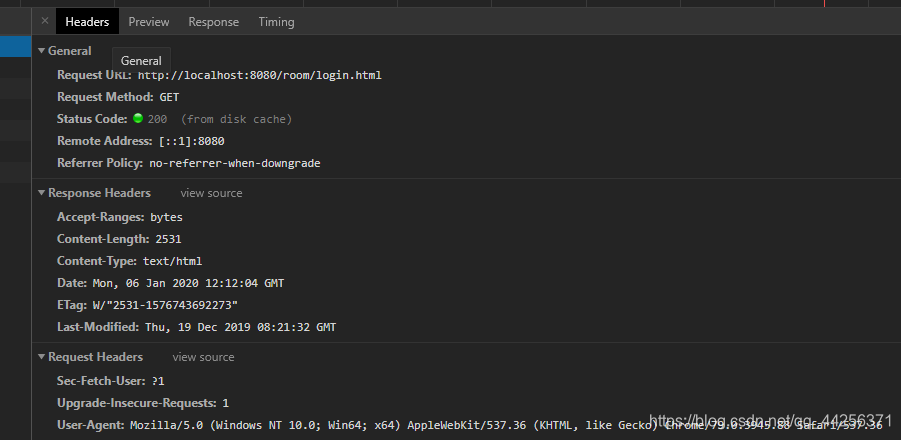
java项目前端理解
总结一下之前再自己配tomcat项目的一些步骤结合再次理解一下:
首先贴上之前写的项目预览图(Java实训项目,借鉴了前端代码),拿来理解一下我们再日常生活中怎样再网页上,具体就不做说明了:
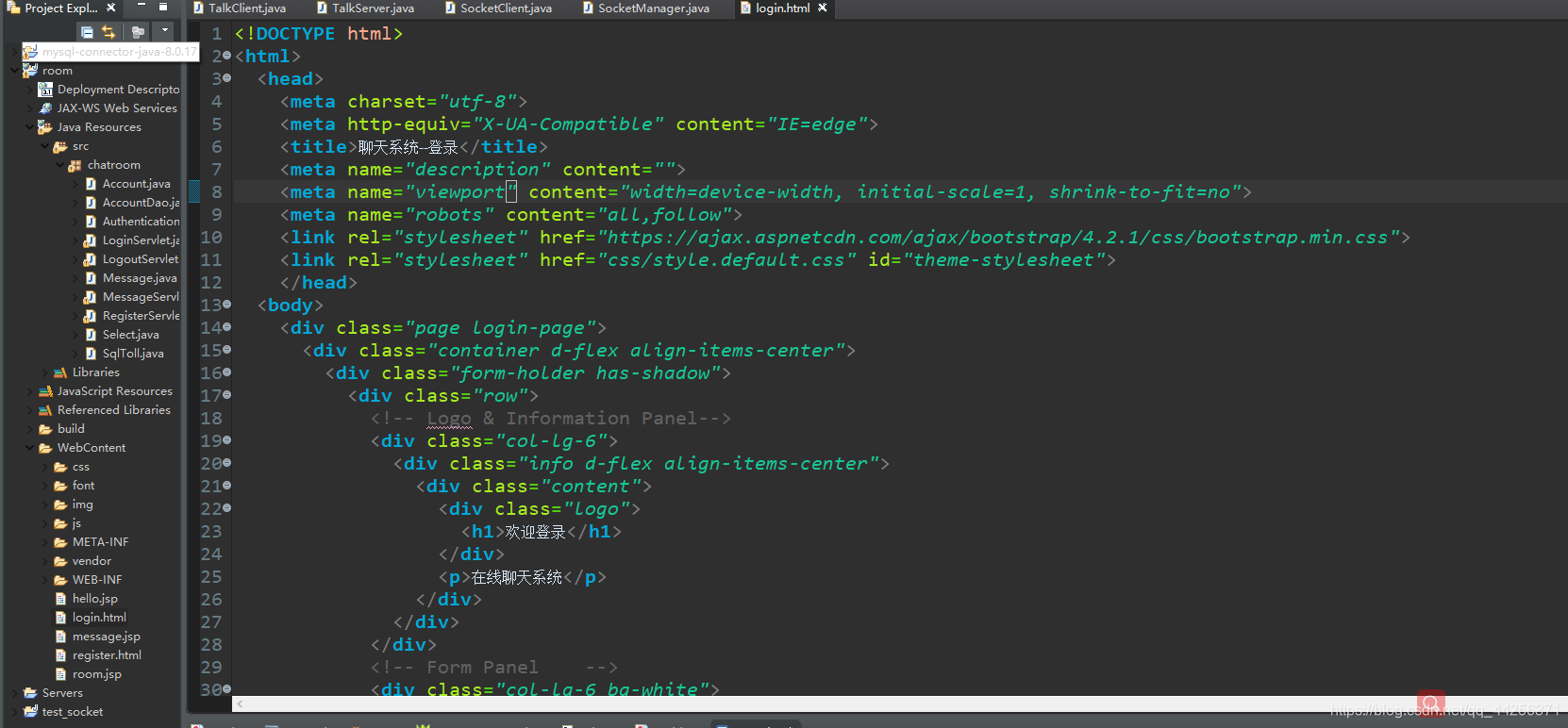
具题一些文件,直接来运行
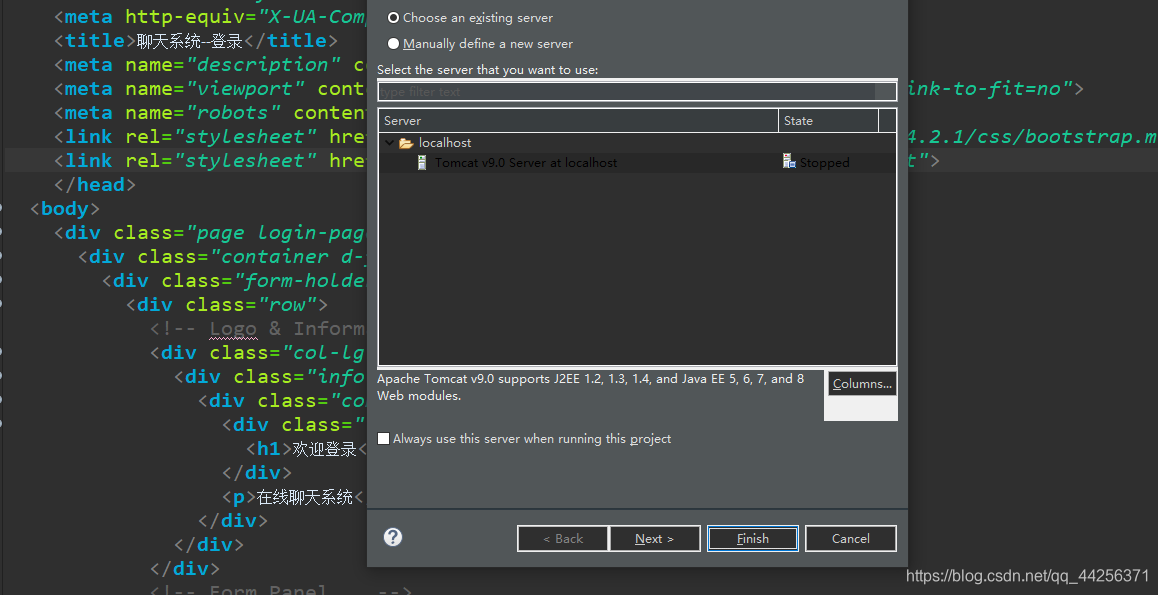
这样就表示一个网站系统在本地环境下开始运行了
运行之后它直接自动由编译器帮我们跳转到登录界面
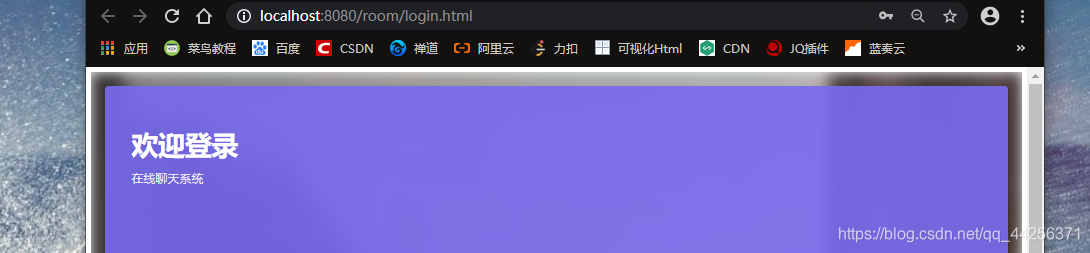
它是自动跳转到的页面,咱们来模仿自己在登录时候的情形:
打开新标签页输入具体要访问的网址:


在我们把网址输入好之后,在localhost:8080之后跟的就是具体文件目录了定位资源,我们在浏览网页也就是浏览这些html文件(比较浅显的理解一下下)。
接着inter会看到浏览器进行连接服务器,会有等待:
等待完之后我们就进入网页:
看到了正常的登录页面,由于我注册好了接着直接登录:
这就基本实现我们日常生活中的一些上网流程。
再模仿两位浏览器端的聊天:
了解完我们日常生活中的怎样登录网站,还有浏览器端和服务器端的交互。
接下来就是看看浏览器怎样来解析的一个html文档
html文件在没有写入html标签之前和txt文本是一个性质的,不含任何样式。只是单纯的文本预览文件。一旦加入了html标签,表示内容有了语义!浏览器的渲染引擎才会根据标签的语义开始解析。
接着就是浏览器的解析:
就是构建一颗DOM树:
解析一个文档意味着把它翻译成有意义的结构以供代码使用。解析的结果通常是一个表征文档的由节点组成的树,称为解析树或句法树。
解析器通常把工作分给两个组件——分词程序负责把输入切分成合法符号序列,解析程序负责按照句法规则分析文档结构和构建句法树。词法分析器知道如何过滤像空格,换行之类的无关字符。
解析器输出的树是由DOM元素和属性节点组成的。DOM的全称为:Document Object Model。它是HTML文档的对象化描述,也是HTML元素与外界(如Javascript)的接口。
比如一个简单的html文件:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
我们都知道代码是逐行执行的,解析也是如此。这里涉及到一个解析算法,算法太复杂,简单的理解为:解析由两部分组成:分词与构建树。它把输入解析成符号序列。在HTML中符号就是开始标签,结束标签,属性名称和属生值。分词器识别这些符号并将其送入树构建者,然后继续分析处理下一个符号,直到输入结束。