决策树是一种用于分类和回归的有监督学习方法——预测模型
该方法是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值大于0的概率,树中的每一个节点表示某个对象,而每一个分叉路代表某个可能的属性值,而每一个叶节点则对应的是从根节点到该叶节点所经历的路径所表示的对象的值。
例如:决策树解决相亲问题
女儿:男方长得帅不帅?
母亲:挺帅的。
女儿:是不是公务员?
母亲:是,在税务局呢。
女儿:那好,我去见见。
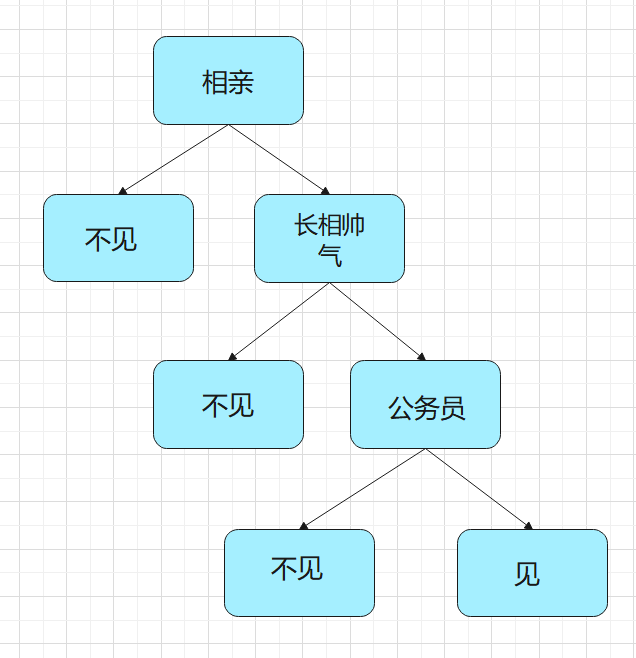
这个女孩的决策过程就是典型分类树决策,如果江所有的条件量化的话,就可以计算出其概率。
代码示例:
#决策树 鸢尾花 from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris #鸢尾花 from sklearn.model_selection import train_test_split #测试集分割 if __name__ == '__main__': arr=load_iris(return_X_y=True) #取出鸢尾花数据 train,target=arr[0],arr[1] #train_data 8 份 test_data 2 份 ,总和为train train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=1024) # 决策树 默认为基尼系数 也可以改成熵 clf=DecisionTreeClassifier(criterion='entropy') #criterion:gini或者entropy,前者是基尼系数,后者是信息熵。 clf.fit(train_data,train_target) y_=clf.predict(test_data) print(y_) print(test_target) print(1-abs((y_-test_target).sum())/len(y_)) #结果为 1.0 即预测结果和实际结果相同