先贴一个beautifulsoup的官方文档,https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id12
requests库用来获取url的响应,但是获取到确实网页代码,为了拿到自己想要的东西,我们需要用一下beautifulsoup这个库,这个库能把想要的东西提取出来。
下载和安装在官方文档里都有,这里还要说一下解析器。beautifulsoup这个库除了支持python标准库中的HTML解析器,还支持其他类似,lxml和html5lib。

上面这张表来自官方文档,选择哪种解析器就因人而异了。
接下来进入正文,首先要构造一个对象,用soup = BeautifulSoup(html,'lxml'),这html可以是事先用requests库请求来的,也可以是自己写的,当然,也可以用soup = BeautifulSoup(open("index.html"))这种方法打开自己html。
然后就是去查看那个html,当html里有a标签时,用soup.a即可输出遇到的第一条a标签,同理,也可以soup.title输出html的title标签。
仅仅是第一个标签那么满足不了我们的需求,我们需要所有的标签里的数据就需要用到findAll这个方法啦,用all_a=soup.findAll('a'),即可获得所有的a标签,但是这时候的输出都是带着a标签的,想要只获得内容,有需要用到string方法,all_a.string,即可。
话不多说,先试着把小米官网中的h2标签,即小标题给爬取下来试试
from bs4 import BeautifulSoup import lxml import requests url = 'https://www.mi.com/' try: #模拟浏览器 kv = {'user-agent':'Mozilla/5.0'} r = requests.get(url , headers = kv) #状态码检查,用于 r.raise_for_status() r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text,'lxml') for tag in soup.findAll('h2'): print(tag.string) except: ("爬取失败")
然后再讲讲string方法,在官方文档中的解释是这样的
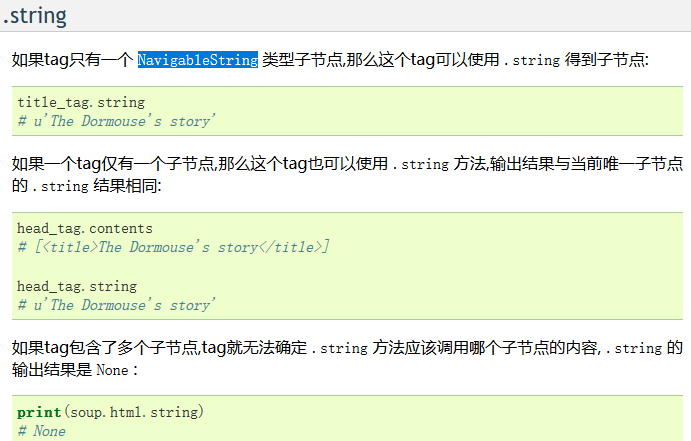
简单的说就是,当你获取的标签里没有别的标签了,你调用这个方法会输出这个标签里的内容,但这个标签里如果有其他的小标签和内容时,返回一个none值,比如说再爬取小米的a标签时、

这一条数据返回的就是none值
我们爬取数据的时候有时会把空白爬进去,但是又不想要空白的时候可以用.stripped_strings方法去除掉空白
然后讲一讲定位就比如说上面那条带着i标签的a标签,我们可以先找到i标签,在用他的父节点输出a标签,用。parent的方法,同理,通过 .next_siblings 和 .previous_siblings 属性可以找到当前节点的兄弟节点