在有向图中,边是单向的:每条边连接的两个顶点都是一个有序对,它们的邻接性是单向的。许多应用都是天然的有向图,如下图。为实现添加这种单向性的限制很容易也很自然,看起来没什么坏处。但实际上这种组合性的结构对算法有深刻的影响,使得有向图和无向图的处理大有不同。

1.术语
虽然我们为有向图的定义和无向图几乎相同(将使用的部分算法和代码也是),但为了说明边的方向性而产生的细小文字差异所代表的结构特性是重点。
定义:一幅有方向性的图(或有向图)是由一组顶点和一组有方向的边组成的,每条有方向的边都连着有序的一对顶点。
我们称一条有向边由第一个顶点指出并指向第二个顶点。在一幅有向图中,一个顶点的出度为由该顶点指出的边的总数;一个顶点的入度为指向该顶点的边的总数。一条有向边的第一个顶点称为它的头,第二个顶点则称为它的尾。用 v->w 表示有向图中一条由v 指向 w 的边。一幅有向图的两个顶点的关系可能有四种:没有边相连;v->w; w-> v;v->w 和 w->v。
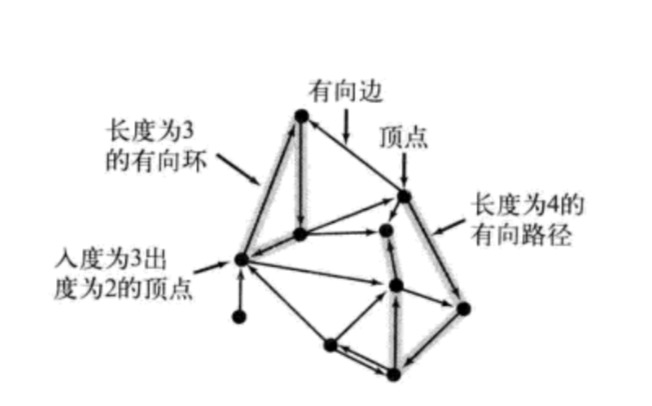
在一幅有向图中,有向路径由一系列顶点组成,对于其中的每个顶点都存在一条有向边从它指向序列中的下一个顶点。有向环为一条至少含有一条边且起点和终点相同的有向路径。路径或环的长度即为其中所包含的边数。
当存在从 v 到 w 的有向路径时,称顶点 w 能够由顶点 v 达到。我们需要理解有向图中的可达性和无向图中的连通性的区别。
2.有向图的数据类型
有向图API

有向图表示
我们使用邻接表来表示有向图,其中边 v -> w 表示顶点 v 所对应的邻接链表中包含一个 w 顶点。这种表示方法和无向图几乎相同而且更明晰,因为每条边都只会出现一次。
有向图取反
Digraph 的 API 中还添加了一个 Reverse 方法。它返回该有向图的一个副本,但将其中所有边的方向反转。在处理有向图时这个方法有时很有用,因为这样用例就可以找出“指向”每个顶点的所有边,而 Adj 方法给出的是由每个顶点指出的边所连接的所有顶点。
顶点的符号名
在有向图中,使用符号名作为顶点也很简单,参考 SymbolGraph。
namespace Digraphs { public class Digraph { private int v; private int e; private List<int>[] adj; public Digraph(int V) { this.v = V; this.e = 0; adj = new List<int>[v]; for (var i = 0; i < v; i++) { adj[i] = new List<int>(); } } public int V() { return v; } public int E() { return e; } public List<int> Adj(int v) { return adj[v]; } public void AddEdge(int v, int w) { adj[v].Add(w); e++; } public Digraph Reverse() { Digraph R = new Digraph(v); for (var i = 0; i < v; i++) foreach (var w in Adj(i)) R.AddEdge(w,i); return R; } } }
3.有向图的可达性
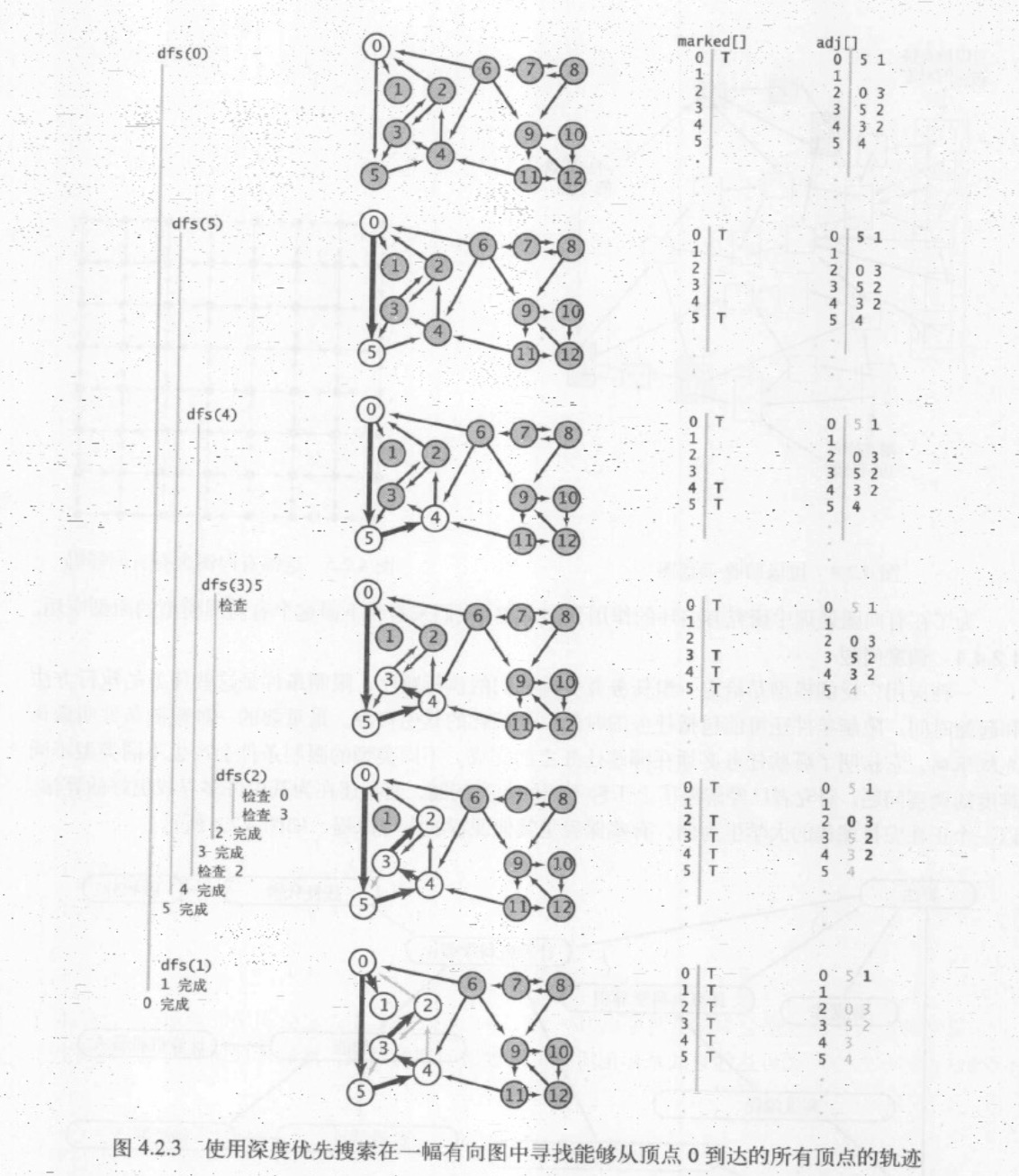
在无向图中介绍的深度优先搜索 DepthFirstSearch ,解决了单点连通性的问题,使得用例可以判定其他顶点和给定的起点是否连通。使用完全相同的代码,将其中的 Graph 替换成 Digraph 也可以解决有向图中的单点可达性问题(给定一幅有向图和一个起点 s ,是否存在一条从 s 到达给定顶点 v 的有向路径?)。

在添加了一个接受多个顶点的构造函数之后,这份 API 使得用例能够解决一个更加一般的问题 -- 多点可达性 (给定一幅有向图和顶点的集合,是否存在一条从集合中的任意顶点到达给定顶点 v 的有向路径?)
下面的 DirectedDFS 算法使用了解决图处理的标准范例和标准的深度优先搜索来解决。对每个起点调用递归方法 Dfs ,以标记遇到的任意顶点。
namespace Digraphs { public class DirectedDFS { private bool[] marked; public DirectedDFS(Digraph G, int s) { marked = new bool[G.V()]; Dfs(G,s); } public DirectedDFS(Digraph G, IEnumerable<int> sources) { marked = new bool[G.V()]; foreach (var s in sources) { if (!marked[s]) Dfs(G,s); } } private void Dfs(Digraph G, int V) { marked[V] = true; foreach (var w in G.Adj(V)) { if (!marked[w]) Dfs(G,w); } } public bool Marked(int v) { return marked[v]; } } }
在有向图中,深度优先搜索标记由一个集合的顶点可达的所有顶点所需的时间与被标记的所有顶点的出度之和成正比。
有向图的寻路
在无向图中的寻找路径的算法,只需将 Graph 替换为 Digraph 就能够解决下面问题:
1.单点有向路径:给定一幅有向图和一个起点 s ,从 s 到给定目的顶点是否存在一条有向路径?如果有,找出这条路径。
2.单点最短有向路径:给定一幅有向图和一个起点 s ,从 s 到给定目的顶点 v 是否存在一条有向路径?如果有,找出其中最短的那条(所含边数最少)。
4.环和有向无环图
在和有向图相关的实际应用中,有向环特别的重要。没有计算机的帮助,在一幅普通的有向图中找出有向环可能会很困难。从原则上来说,一幅有向图可能含有大量的环;在实际应用中,我们一般只重点关注其中一小部分,或者只想知道它们是否存在。

调度问题
一种应用广泛的模型是给定一组任务并安排它们的执行顺序,限制条件是这些任务的执行方法和开始时间。限制条件还可能包括任务的耗时以及消耗的资源。最重要的一种限制条件叫做优先级限制,它指明了哪些任务必须在哪些任务之前完成。不同类型的限制条件会产生不同类型不同难度的调度问题。
下面以一个正在安排课程的大学生为例,有些课程是其他课程的先导课程:

如果假设该学生一次只能修一门课程,就会遇到优先级下的调度问题:给定一组需要完成的任务,以及一组关于任务完成的先后次序的优先级限制。在满足限制条件的前提下应该如何安排并完成所有任务?
对于任意一个这样的问题,我们先画出一幅有向图,其中顶点对应任务,有向边对应优先级顺序。为了简化问题,我们以整数为顶点:
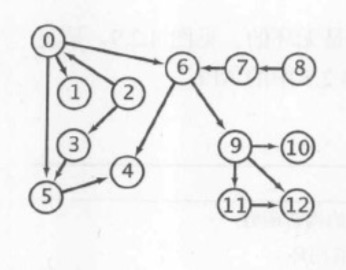
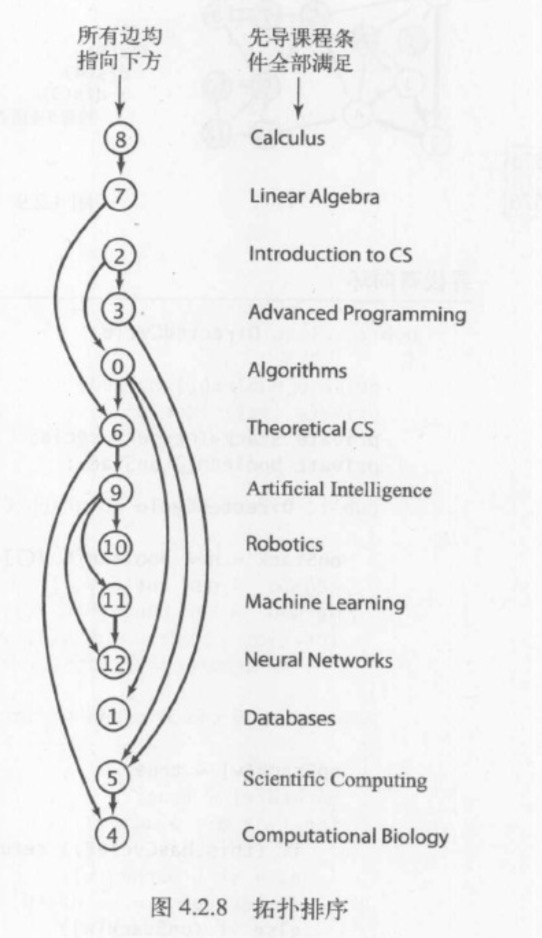
在有向图中,优先级限制下的调度问题等价于一个基本问题--拓扑排序:给定一幅图,将所有顶点排序,使得所有的有向边均从排在前面的元素指向排在后面的元素(或者说明无法做到这一点)。
如图,所有的边都是向下的,所以清晰地表示了这幅有向图模型所代表的有优先级限制的调度问题的一个解决方法:按照这个顺序,该同学可以满足先导课程限制的条件下修完所有课程。
有向图中的环
如果任务 x 必须在任务 y 之前完成,而任务 y 必须在任务 z 之前完成,但任务 z 又必须在任务 x 之前完成,那肯定是有人搞错了,因为这三个限制条件是不可能被同时满足的。一般来说,如果一个优先级限制的问题中存在有向环,那么这个问题肯定是无解的。要检查这种错误,需要解决 有向环检测:给定的有向图中包含有向环吗?如果有,按照路径的方向从某个顶点并返回自己来找到环上的所有顶点。
一幅有向图中含有环的数量可能是图的大小的指数级别,因此我们只需找到一个环即可,而不是所有环。在任务调度和其他许多实际问题中不允许出现有向环,因此有向无环图就变得很特殊。
基于深度优先搜索可以解决有向环检测的问题,因为由系统维护的递归调用的栈表示的正是“当前”正在遍历的有向路径。一旦我们找到了一条有向边 v -> w 且 w 已经存在于栈中,就找到了一个环,因为栈表示的是一条由 w 到 v 的有向路径,而 v -> w 正好补全了这个环。如果没有找到这样的边,就意味着这副有向图是无环的。DirectedCycle 基于这个思想实现的:
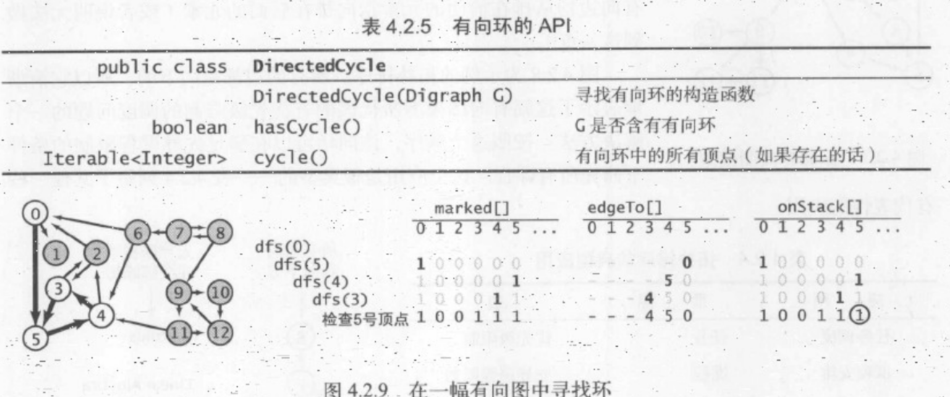
namespace Digraphs { public class DirectedCycle { private bool[] marked; private int[] edgeTo; private Stack<int> cycle;//有向环中的所有顶点(如果存在) private bool[] onStack;//递归调用的栈上的所有顶点 public DirectedCycle(Digraph G) { onStack = new bool[G.V()]; edgeTo = new int[G.V()]; marked = new bool[G.V()]; for (int v = 0; v < G.V(); v++) { if (!marked[v]) Dfs(G,v); } } private void Dfs(Digraph G, int v) { onStack[v] = true; marked[v] = true; foreach (var w in G.Adj(v)) { if (hasCycle()) return; else if (!marked[w]) { edgeTo[w] = v; Dfs(G, w); } else if (onStack[w]) { cycle = new Stack<int>(); for (int x = v; x != w; x = edgeTo[x]) cycle.Push(x); cycle.Push(w); cycle.Push(v); } } onStack[v] = false; } private bool hasCycle() { return cycle != null; } public IEnumerable<int> Cycle() { return cycle; } } }
该类为标准的的递归 Dfs 方法添加了一个布尔类型的数组 onStack 来保存递归调用期间栈上的所有顶点。当它找到一条边 v -> w 且 w 在栈中时,它就找到了一个有向环。环上的所有顶点可以通过 edgeTo 中的链接得到。
在执行 Dfs 时,查找的是一条由起点到 v 的有向路径。要保存这条路径,DirectedCycle 维护了一个 由顶点索引的数组 onStack,以标记递归调用的栈上的所有顶点(在调用 Dfs 时将 onStack[ v ] 设为 true,在调用结束时将其设为 false)。DirectedCycle 同时也使用了一个 edgeTo 数组,在找到有向环时返回环中的所有顶点。
顶点的深度优先次序与拓扑排序
优先级限制下的调度问题等价于计算有向无环图中的所有顶点的拓扑排序:

下面算法的基本思想是深度优先搜索正好只会访问每个顶点一次。如果将 Dfs 的参数顶点保存在一个数据结构中,遍历这个数据结构实际上就能访问图中的所有顶点,遍历的顺序取决于这个数据结构的性质以及是在递归调用之前还是之后进行保存。在典型的应用中,顶点一下三种排列顺序:
前序:在递归调用之前将顶点加入队列;
后序:在递归调用之后将顶点加入队列;
逆后序:在递归调用之后将顶点压入栈。
该类允许用例用各种顺序遍历深度优先搜索经过得顶点。这在高级得有向图处理算法非常有用,因为搜索得递归性使得我们能够证明这段计算得许多性质。
namespace Digraphs { public class DepthFirstOrder { private bool[] marked; private Queue<int> pre;//所有顶点的前序排列 private Queue<int> post;//所有顶点的后序排列 private Stack<int> reversePost;//所有顶点的逆后序排列 public DepthFirstOrder(Digraph G) { marked = new bool[G.V()]; pre = new Queue<int>(); post = new Queue<int>(); reversePost = new Stack<int>(); for (var v = 0; v < G.V(); v++) { if (!marked[v]) Dfs(G,v); } } private void Dfs(Digraph G, int v) { pre.Enqueue(v); marked[v] = true; foreach (var w in G.Adj(v)) { if (!marked[w]) Dfs(G,w); } post.Enqueue(v); reversePost.Push(v); } public IEnumerable<int> Pre() { return pre; } public IEnumerable<int> Post() { return post; } public IEnumerable<int> ReversePost() { return reversePost; } } }
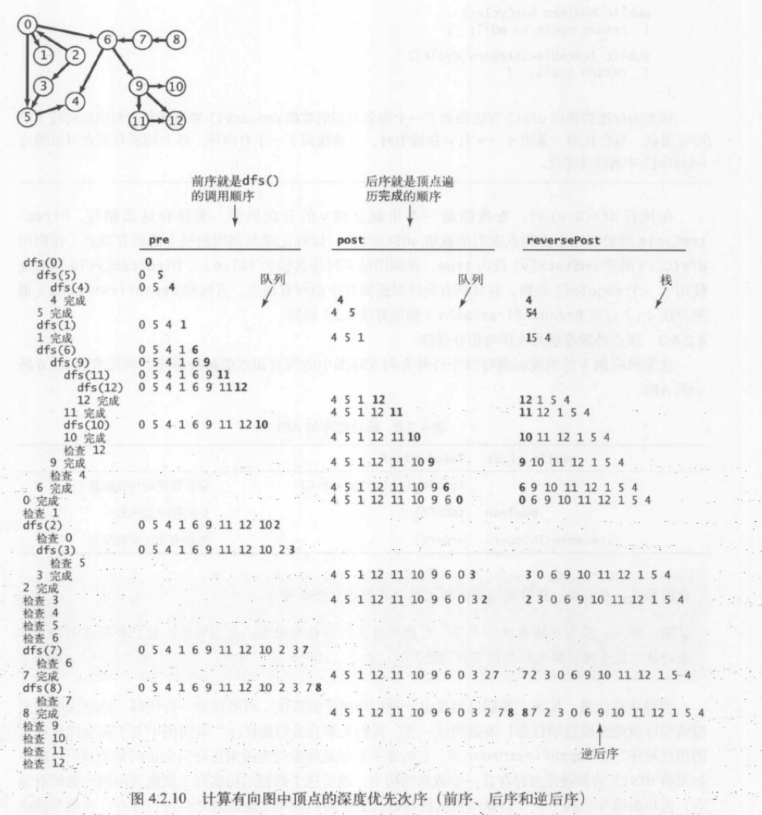
一幅有向无环图得拓扑排序即为所有顶点的逆后序排列。
拓扑排序
namespace Digraphs { public class Topological { private IEnumerable<int> order; public Topological(Digraph G) { DirectedCycle cycleFinder = new DirectedCycle(G); if (cycleFinder.HasCycle()) { DepthFirstOrder dfs = new DepthFirstOrder(G); order = dfs.ReversePost(); } } public IEnumerable<int> Order() { return order; } public bool IsDAG() { return order != null; } } }
这段使用 DirectedCycle 检测是否有环,使用 DepthFirstOrder 返回有向图的逆后序。

使用深度优先搜索对有向无环图进行拓扑排序所需的时间和 V+E 成正比。第一遍深度优先搜索保证了不存在有向环,第二遍深度优先搜索产生了顶点的逆后序排列。
在实际应用中,拓扑排序和有向环的检测总是一起出现,因为有向环的检测是排序的前提。例如,在一个任务调度应用中,无论计划如何安排,其背后的有向图中包含的环意味着存在一个必须被纠正的严重错误。因此,解决任务调度类应用通常需要一下3步:
1.指明任务和优先级条件;
2.不断检测并去除有向图中的所有环,以确保存在可行方案;
3.使用拓扑排序解决调度问题。
类似地,调度方案的任何变动之后都需要再次检查是否存在环,然后再计算新的调度安排。
5.有向图中的强连通性
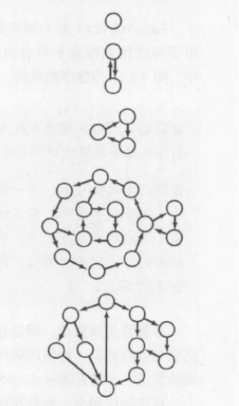
如果两个顶点 v 和 w 是相互可达的,则称它们为强连通的。也就是说,即存在一条从 v 到 w 的有向路径,也存在一条从 w 到 v 的有向路径。如果一幅有向图中的任意两个顶点都是强连通的,则称这副有向图也是强连通的。
下面是强连通图的例子,可以看到,环在强连通性的理解上起着重要的作用。
强连通分量
和无向图中的连通性一样,有向图中的强连通性也是一种顶点之间的等价关系:
自反性:任意顶点 v 和自己都是强连通的。
对称性:如果 v 和 w 是强连通的,那么 w 和 v 也是。
传递性:如果 v 和 w 是强连通的且 w 和 x 也是强连通的,那么 v 和 x 也是强连通的。
作为一种等价关系,强连通性将所有顶点分为了一些等价类,每个等价类都是由相互均为强连通的顶点的最大子集组成。我们称这些子集为强连通分量。如下图,一个含有 V 个顶点的有向图含有 1~ V个强连通分量——一个强连通图只含有一个强连通分量,而一个有向无环图则含有 V 个强连通分量。需要注意的是强连通分量的定义是基于顶点的,而不是边。有些边连接的两个顶点都在同一个强连通分量中,而有些边连接的两个顶点则不在同一强连通分量中。
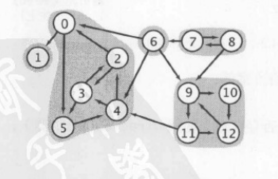
强连通分量API

设计一种平方级别的算法来计算强连通分量并不困难,单对于处理实际应用中的大型图来说,平方级别的时间和空间需求是不可接受的。
Kosaraju算法
在有向图中如何高效地计算强连通分量?我们只需修改无向图连通分量的算法 CC ,KosarajuCC 算法如下,它将会完成一下任务:
1.在给定的一幅有向图 G 中,使用 DepthFirstOrder 来计算它的反向图 GR 的逆后序排列;
2.在 G 中进行标准的深度优先搜索,但是要按照刚才计算得到的顺序而非标准的顺序来访问所有未被标记的顶点;
3.在构造函数中,所有在同一个递归 Dfs() 调用中被访问到的顶点都在同一个强连通分量中,将它们按照和 CC 相同的方式识别出来。
namespace Digraphs { public class KosarajuCC { private bool[] marked;//已访问的顶点 private int[] id;//强连通分量的标识符 private int count;//强连通分量的数量 public KosarajuCC(Digraph G) { marked = new bool[G.V()]; id = new int[G.V()]; DepthFirstOrder order = new DepthFirstOrder(G.Reverse()); foreach (var s in order.ReversePost()) { if (!marked[s]) { Dfs(G,s); count++; } } } private void Dfs(Digraph G, int v) { marked[v] = true; id[v] = count; foreach (var w in G.Adj(v)) { if (!marked[w]) Dfs(G,w); } } public bool StronglyConnected(int v, int w) { return id[v] == id[w]; } public int Id(int v) { return id[v]; } public int Count() { return count; } } }
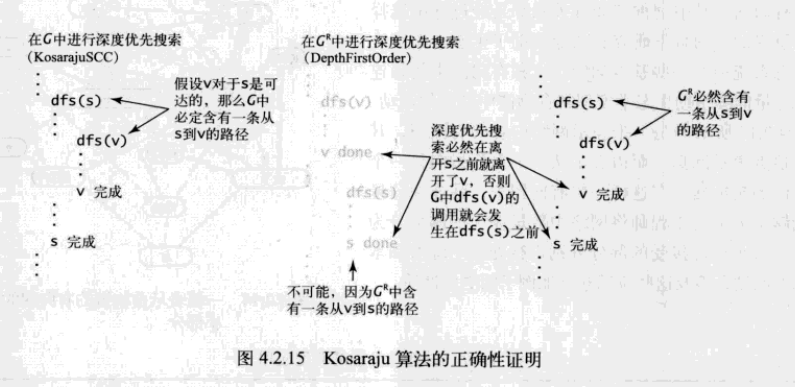

Kosaraju 算法的预处理所需的时间和空间与 V+E 成正比且支持常数时间的有向图强连通性的查询。
再谈可达性
在无向图中如果两个顶点 V 和 W 是连通的,那么就既存在一条从 v 到 w 的路径也存在一条从 w 到 v 的路径。在有向图中如果两个顶点 v 和 w 是强连通的,那么就既存在一条从 v 到 w 的路径也存在另一条从 w 到 v 的路径。但对于一对非强连通的顶点,也许存在一条从 v 到 w 的路径,也许存在一条从 w 到 v 的路径,也许两条都不存在,但不可能两条都存在。
顶点对的可达性:对于无向图,等价于连通性问题;对于有向图,它和强连通性有很大区别。 CC 实现需要线性级别的预处理时间才能支持常数时间的操作。在有向图的相应实现中能否达到这样的性能?
有向图 G 的传递闭包是由相同的一组顶点组成的另一幅有向图,在传递闭包中存在一条从 v 指向 w 的边当且仅当在 G 中 w 是从 v 可达的。
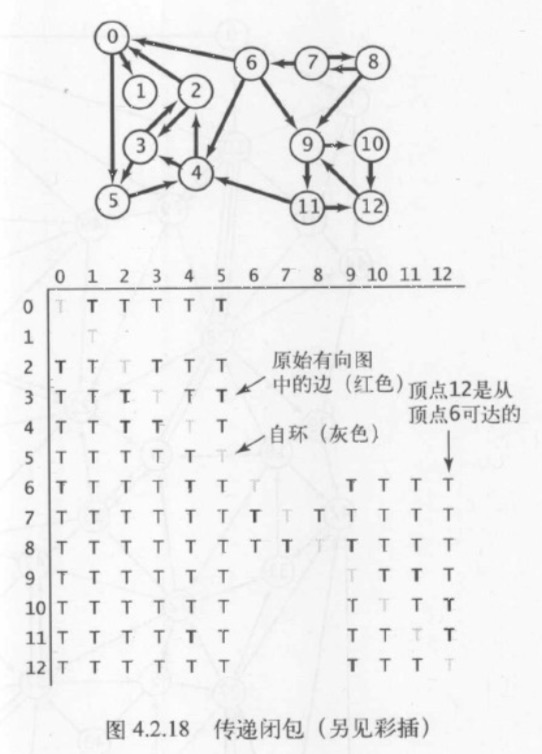
根据约定,每个顶点对于自己都是可达的,因此传递闭包会含有 V 个自环。上图只有 22 条有向边,但它的传递闭包含有可能的 169 条有向边中的 102 条。一般来说,一幅有向图的传递闭包中所含的边都比原图中多得多。例如,含有 V 个顶点和 V 条边的有向环的传递闭包是一幅含有 V 的平方条边的有向完全图。因为传递闭包一般都是稠密的,我们通常都将它们表示为一个布尔值矩阵,其中 v 行 w 列的值为 true 当且仅当 w 是从 v 可达的。与其计算一幅有向图的传递闭包,不如使用深度优先搜索来实现如下API:

下面的算法使用 DirectedDFS 实现:
namespace Digraphs { public class TransitiveClosure { private DirectedDFS[] all; public TransitiveClosure(Digraph G) { all = new DirectedDFS[G.V()]; for (var v = 0; v < G.V(); v++) all[v] = new DirectedDFS(G,v); } public bool Reachable(int v, int w) { return all[v].Marked(w); } } }
该算法无论对于稀疏图还是稠密图,都是理想解决方案,但对于大型有向图不适用,因为构造函数所需的空间和 V 的平方成正比,所需的时间和 V(V+ E) 成正比。
总结
