归并排序的基本思想
将待排序序列R[0...n-1]看成是n个长度为1的有序序列,将相邻的有序表成对归并,得到n/2个长度为2的有序表;将这些有序序列再次归并,得到n/4个长度为4的有序序列;如此反复进行下去,最后得到一个长度为n的有序序列。
综上可知:
归并排序其实要做两件事:
(1)“分解”——将序列每次折半划分。
(2)“合并”——将划分后的序列段两两合并后排序。
我们先来考虑第二步,如何合并?
在每次合并过程中,都是对两个有序的序列段进行合并,然后排序。
这两个有序序列段分别为 R[low, mid] 和 R[mid+1, high]。
先将他们合并到一个局部的暂存数组R2中,带合并完成后再将R2复制回R中。
为了方便描述,我们称 R[low, mid] 第一段,R[mid+1, high] 为第二段。
每次从两个段中取出一个记录进行关键字的比较,将较小者放入R2中。最后将各段中余下的部分直接复制到R2中。
经过这样的过程,R2已经是一个有序的序列,再将其复制回R中,一次合并排序就完成了。
核心代码
int i = low; // i是第一段序列的下标
int j = mid + 1; // j是第二段序列的下标
int k = 0; // k是临时存放合并序列的下标
int[] array2 = new int[high - low + 1]; // array2是临时合并序列
// 扫描第一段和第二段序列,直到有一个扫描结束
while (i <= mid && j <= high) {
// 判断第一段和第二段取出的数哪个更小,将其存入合并序列,并继续向下扫描
if (array[i] <= array[j]) {
array2[k] = array[i];
i++;
k++;
} else {
array2[k] = array[j];
j++;
k++;
}
}
// 若第一段序列还没扫描完,将其全部复制到合并序列
while (i <= mid) {
array2[k] = array[i];
i++;
k++;
}
// 若第二段序列还没扫描完,将其全部复制到合并序列
while (j <= high) {
array2[k] = array[j];
j++;
k++;
}
// 将合并序列复制到原始序列中
for (k = 0, i = low; i <= high; i++, k++) {
array[i] = array2[k];
}
}
掌握了合并的方法,接下来,让我们来了解 如何分解。
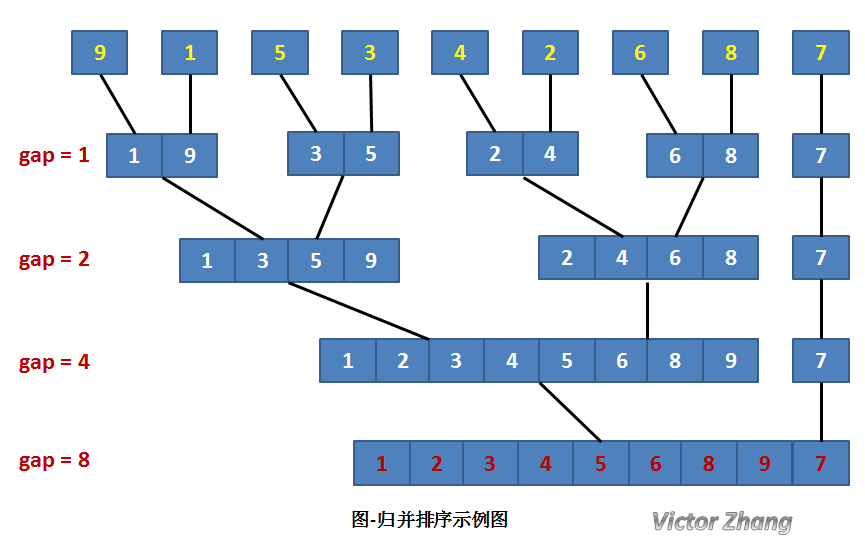
在某趟归并中,设各子表的长度为gap,则归并前R[0...n-1]中共有n/gap个有序的子表:R[0...gap-1], R[gap...2*gap-1], ... , R[(n/gap)*gap ... n-1]。
调用Merge将相邻的子表归并时,必须对表的特殊情况进行特殊处理。
若子表个数为奇数,则最后一个子表无须和其他子表归并(即本趟处理轮空):若子表个数为偶数,则要注意到最后一对子表中后一个子表区间的上限为n-1。
核心代码
int i = 0;
// 归并gap长度的两个相邻子表
for (i = 0; i + 2 * gap - 1 < length; i = i + 2 * gap) {
Merge(array, i, i + gap - 1, i + 2 * gap - 1);
}
// 余下两个子表,后者长度小于gap
if (i + gap - 1 < length) {
Merge(array, i, i + gap - 1, length - 1);
}
}
public int[] sort(int[] list) {
for (int gap = 1; gap < list.length; gap = 2 * gap) {
MergePass(list, gap, list.length);
System.out.print("gap = " + gap + ": ");
this.printAll(list);
}
return list;
}
算法分析
归并排序算法的性能
|
排序类别 |
排序方法 |
时间复杂度 |
空间复杂度 |
稳定性 |
复杂性 |
||
|
平均情况 |
最坏情况 |
最好情况 |
|||||
|
归并排序 |
归并排序 |
O(nlog2n) |
O(nlog2n) |
O(nlog2n) |
O(n) |
稳定 |
较复杂 |
时间复杂度
归并排序的形式就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的可以得出它的时间复杂度是O(n*log2n)。
空间复杂度
由前面的算法说明可知,算法处理过程中,需要一个大小为n的临时存储空间用以保存合并序列。
算法稳定性
在归并排序中,相等的元素的顺序不会改变,所以它是稳定的算法。
归并排序和堆排序、快速排序的比较
若从空间复杂度来考虑:首选堆排序,其次是快速排序,最后是归并排序。
若从稳定性来考虑,应选取归并排序,因为堆排序和快速排序都是不稳定的。
若从平均情况下的排序速度考虑,应该选择快速排序。