什么是TF-IDF算法?
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
TF-IDF有两层意思:
-
TF:"词频"(Term Frequency)
-
IDF"逆文档频率"(Inverse Document Frequency)
TF-IDF应用
- 搜索引擎
- 关键词提取
- 文本相似性
- 文本摘要
TF-IDF算法步骤
第一步,计算词频:

第二步,计算逆文档频率:
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
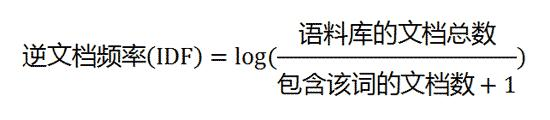
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF:
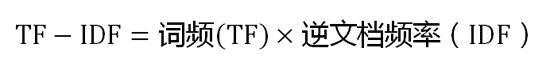
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。
所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,取最大的几个。
TF-IDF算法的不足
TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。
在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。
IDF 的简单结构并不能使提取的关键词,十分有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。
- 没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
- 按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
- 传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类目间的分布情况。
- 对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
Python实现
import math
corpus = [
"what is the weather like today",
"what is for dinner tonight",
"this is a question worth pondering",
"it is a beautiful day today"
]
words = []
# 对corpus分词
for i in corpus:
words.append(i.split())
# 如果有自定义的停用词典,我们可以用下列方法来分词并去掉停用词
# f = ["is", "the"]
# for i in corpus:
# all_words = i.split()
# new_words = []
# for j in all_words:
# if j not in f:
# new_words.append(j)
# words.append(new_words)
# print(words)
# 进行词频统计
def Counter(word_list):
wordcount = []
for i in word_list:
count = {}
for j in i:
if not count.get(j):
count.update({j: 1})
elif count.get(j):
count[j] += 1
wordcount.append(count)
return wordcount
wordcount = Counter(words)
# 计算TF(word代表被计算的单词,word_list是被计算单词所在文档分词后的字典)
def tf(word, word_list):
return word_list.get(word) / sum(word_list.values())
# 统计含有该单词的句子数
def count_sentence(word, wordcount):
return sum(1 for i in wordcount if i.get(word))
# 计算IDF
def idf(word, wordcount):
return math.log(len(wordcount) / (count_sentence(word, wordcount) + 1))
# 计算TF-IDF
def tfidf(word, word_list, wordcount):
return tf(word, word_list) * idf(word, wordcount)
p = 1
for i in wordcount:
print("part:{}".format(p))
p = p+1
for j, k in i.items():
print("word: {} ---- TF-IDF:{}".format(j, tfidf(j, i, wordcount)))